 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Schedulers: An Adaptive Scheduling Agent as a Learned Router for Expert Policies
Nov 07, 2025Modern operating system schedulers employ a single, static policy, which struggles to deliver optimal performance across the diverse and dynamic workloads of contemporary systems. This "one-policy-fits-all" approach leads to significant compromises in fairness, throughput, and latency, particularly with the rise of heterogeneous hardware and varied application architectures. This paper proposes a new paradigm: dynamically selecting the optimal policy from a portfolio of specialized schedulers rather than designing a single, monolithic one. We present the Adaptive Scheduling Agent (ASA), a lightweight framework that intelligently matches workloads to the most suitable "expert" scheduling policy at runtime. ASA's core is a novel, low-overhead offline/online approach. First, an offline process trains a universal, hardware-agnostic machine learning model to recognize abstract workload patterns from system behaviors. Second, at runtime, ASA continually processes the model's predictions using a time-weighted probability voting algorithm to identify the workload, then makes a scheduling decision by consulting a pre-configured, machine-specific mapping table to switch to the optimal scheduler via Linux's sched_ext framework. This decoupled architecture allows ASA to adapt to new hardware platforms rapidly without expensive retraining of the core recognition model. Our evaluation, based on a novel benchmark focused on user-experience metrics, demonstrates that ASA consistently outperforms the default Linux scheduler (EEVDF), achieving superior results in 86.4% of test scenarios. Furthermore, ASA's selections are near-optimal, ranking among the top three schedulers in 78.6% of all scenarios. This validates our approach as a practical path toward more intelligent, adaptive, and responsive operating system schedulers.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
LIME-M: Less Is More for Evaluation of MLLMs
Sep 10, 2024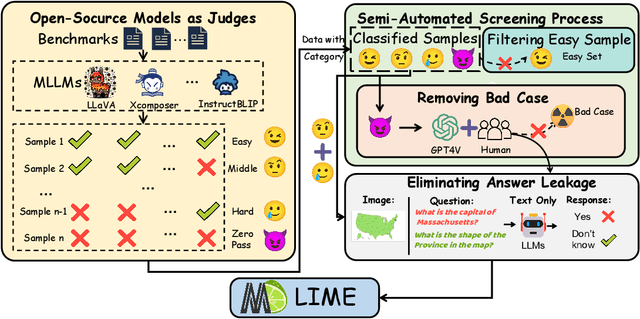
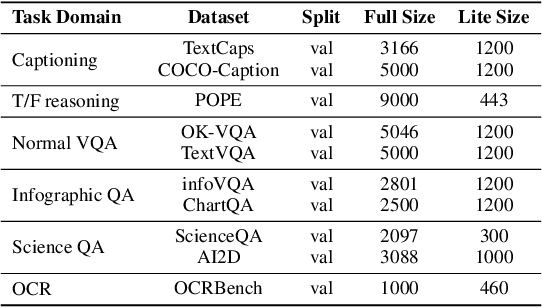
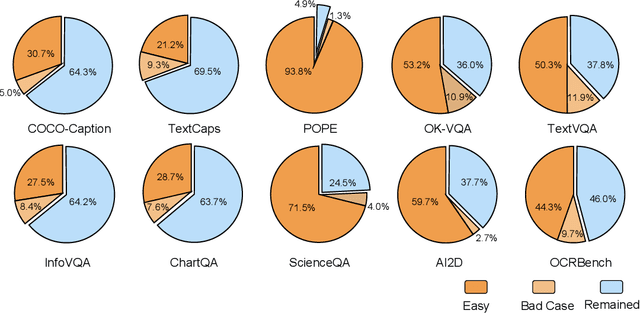
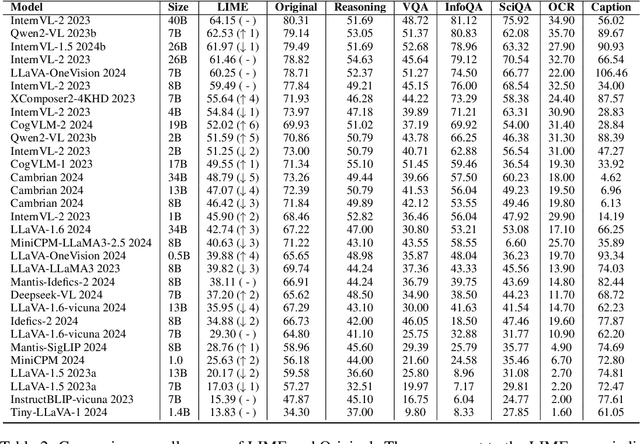
With the remarkable success achieved by Multimodal Large Language Models (MLLMs), numerous benchmarks have been designed to assess MLLMs' ability to guide their development in image perception tasks (e.g., image captioning and visual question answering). However, the existence of numerous benchmarks results in a substantial computational burden when evaluating model performance across all of them. Moreover, these benchmarks contain many overly simple problems or challenging samples, which do not effectively differentiate the capabilities among various MLLMs. To address these challenges, we propose a pipeline to process the existing benchmarks, which consists of two modules: (1) Semi-Automated Screening Process and (2) Eliminating Answer Leakage. The Semi-Automated Screening Process filters out samples that cannot distinguish the model's capabilities by synthesizing various MLLMs and manually evaluating them. The Eliminate Answer Leakage module filters samples whose answers can be inferred without images. Finally, we curate the LIME-M: Less Is More for Evaluation of Multimodal LLMs, a lightweight Multimodal benchmark that can more effectively evaluate the performance of different models. Our experiments demonstrate that: LIME-M can better distinguish the performance of different MLLMs with fewer samples (24% of the original) and reduced time (23% of the original); LIME-M eliminates answer leakage, focusing mainly on the information within images; The current automatic metric (i.e., CIDEr) is insufficient for evaluating MLLMs' capabilities in captioning. Moreover, removing the caption task score when calculating the overall score provides a more accurate reflection of model performance differences. All our codes and data are released at https://github.com/kangreen0210/LIME-M.