 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecode_transformed: The Influence of Large Language Models on Code
Jun 13, 2025Coding remains one of the most fundamental modes of interaction between humans and machines. With the rapid advancement of Large Language Models (LLMs), code generation capabilities have begun to significantly reshape programming practices. This development prompts a central question: Have LLMs transformed code style, and how can such transformation be characterized? In this paper, we present a pioneering study that investigates the impact of LLMs on code style, with a focus on naming conventions, complexity, maintainability, and similarity. By analyzing code from over 19,000 GitHub repositories linked to arXiv papers published between 2020 and 2025, we identify measurable trends in the evolution of coding style that align with characteristics of LLM-generated code. For instance, the proportion of snake\_case variable names in Python code increased from 47% in Q1 2023 to 51% in Q1 2025. Furthermore, we investigate how LLMs approach algorithmic problems by examining their reasoning processes. Given the diversity of LLMs and usage scenarios, among other factors, it is difficult or even impossible to precisely estimate the proportion of code generated or assisted by LLMs. Our experimental results provide the first large-scale empirical evidence that LLMs affect real-world programming style.
Wikipedia in the Era of LLMs: Evolution and Risks
Mar 04, 2025

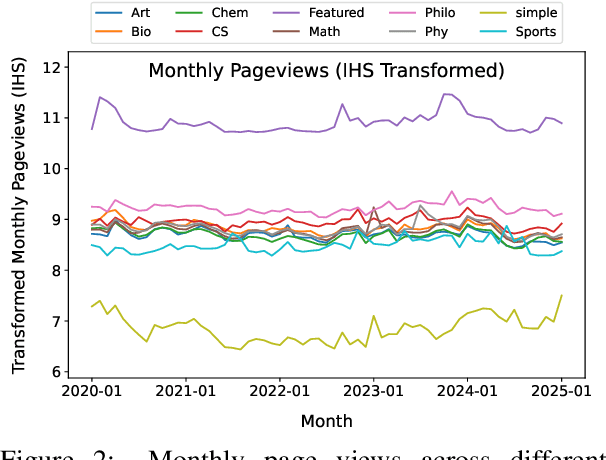

In this paper, we present a thorough analysis of the impact of Large Language Models (LLMs) on Wikipedia, examining the evolution of Wikipedia through existing data and using simulations to explore potential risks. We begin by analyzing page views and article content to study Wikipedia's recent changes and assess the impact of LLMs. Subsequently, we evaluate how LLMs affect various Natural Language Processing (NLP) tasks related to Wikipedia, including machine translation and retrieval-augmented generation (RAG). Our findings and simulation results reveal that Wikipedia articles have been influenced by LLMs, with an impact of approximately 1%-2% in certain categories. If the machine translation benchmark based on Wikipedia is influenced by LLMs, the scores of the models may become inflated, and the comparative results among models might shift as well. Moreover, the effectiveness of RAG might decrease if the knowledge base becomes polluted by LLM-generated content. While LLMs have not yet fully changed Wikipedia's language and knowledge structures, we believe that our empirical findings signal the need for careful consideration of potential future risks.
Matching for causal effects via multimarginal optimal transport
Dec 08, 2021



Matching on covariates is a well-established framework for estimating causal effects in observational studies. The principal challenge in these settings stems from the often high-dimensional structure of the problem. Many methods have been introduced to deal with this challenge, with different advantages and drawbacks in computational and statistical performance and interpretability. Moreover, the methodological focus has been on matching two samples in binary treatment scenarios, but a dedicated method that can optimally balance samples across multiple treatments has so far been unavailable. This article introduces a natural optimal matching method based on entropy-regularized multimarginal optimal transport that possesses many useful properties to address these challenges. It provides interpretable weights of matched individuals that converge at the parametric rate to the optimal weights in the population, can be efficiently implemented via the classical iterative proportional fitting procedure, and can even match several treatment arms simultaneously. It also possesses demonstrably excellent finite sample properties.