 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgenvAgent: Automated Data Visualization from Natural Language via Collaborative Agent Workflow
Feb 07, 2025



Natural Language to Visualization (NL2Vis) seeks to convert natural-language descriptions into visual representations of given tables, empowering users to derive insights from large-scale data. Recent advancements in Large Language Models (LLMs) show promise in automating code generation to transform tabular data into accessible visualizations. However, they often struggle with complex queries that require reasoning across multiple tables. To address this limitation, we propose a collaborative agent workflow, termed nvAgent, for NL2Vis. Specifically, nvAgent comprises three agents: a processor agent for database processing and context filtering, a composer agent for planning visualization generation, and a validator agent for code translation and output verification. Comprehensive evaluations on the new VisEval benchmark demonstrate that nvAgent consistently surpasses state-of-the-art baselines, achieving a 7.88% improvement in single-table and a 9.23% improvement in multi-table scenarios. Qualitative analyses further highlight that nvAgent maintains nearly a 20% performance margin over previous models, underscoring its capacity to produce high-quality visual representations from complex, heterogeneous data sources.
Hyperspectral Image Classification Based on Adaptive Sparse Deep Network
Oct 21, 2019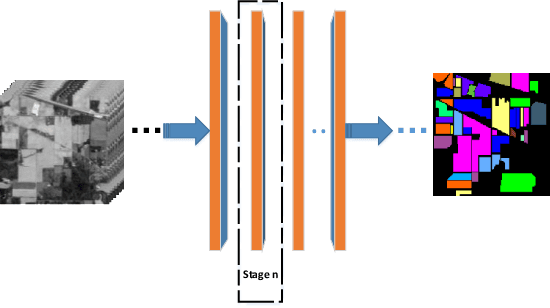
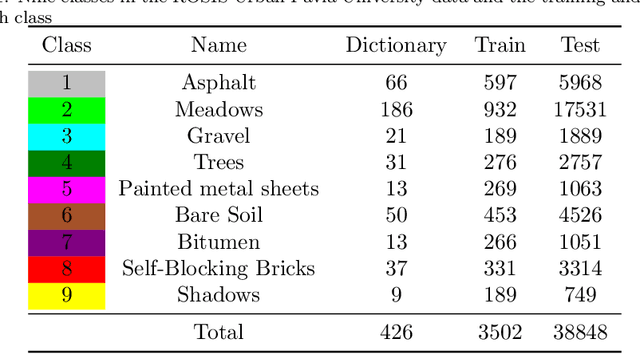
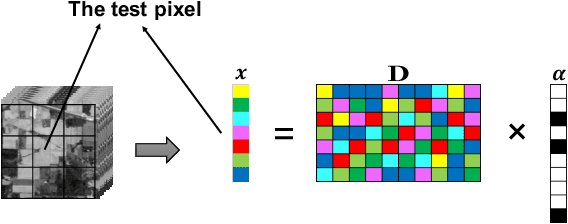
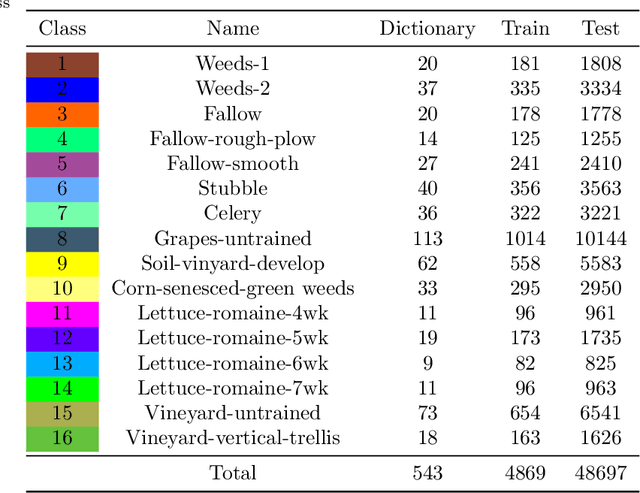
Sparse model is widely used in hyperspectral image classification.However, different of sparsity and regularization parameters has great influence on the classification results.In this paper, a novel adaptive sparse deep network based on deep architecture is proposed, which can construct the optimal sparse representation and regularization parameters by deep network.Firstly, a data flow graph is designed to represent each update iteration based on Alternating Direction Method of Multipliers (ADMM) algorithm.Forward network and Back-Propagation network are deduced.All parameters are updated by gradient descent in Back-Propagation.Then we proposed an Adaptive Sparse Deep Network.Comparing with several traditional classifiers or other algorithm for sparse model, experiment results indicate that our method achieves great improvement in HSI classification.