 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntoTKGE: Ontology-Enhanced Temporal Knowledge Graph Extrapolation
Apr 07, 2026Temporal knowledge graph (TKG) extrapolation is an important task that aims to predict future facts through historical interaction information within KG snapshots. A key challenge for most existing TKG extrapolation models is handling entities with sparse historical interaction. The ontological knowledge is beneficial for alleviating this sparsity issue by enabling these entities to inherit behavioral patterns from other entities with the same concept, which is ignored by previous studies. In this paper, we propose a novel encoder-decoder framework OntoTKGE that leverages the ontological knowledge from the ontology-view KG (i.e., a KG modeling hierarchical relations among abstract concepts as well as the connections between concepts and entities) to guide the TKG extrapolation model's learning process through the effective integration of the ontological and temporal knowledge, thereby enhancing entity embeddings. OntoTKGE is flexible enough to adapt to many TKG extrapolation models. Extensive experiments on four data sets demonstrate that OntoTKGE not only significantly improves the performance of many TKG extrapolation models but also surpasses many SOTA baseline methods.
Joint Knowledge Base Completion and Question Answering by Combining Large Language Models and Small Language Models
Apr 07, 2026Knowledge Bases (KBs) play a key role in various applications. As two representative KB-related tasks, knowledge base completion (KBC) and knowledge base question answering (KBQA) are closely related and inherently complementary with each other. Thus, it will be beneficial to solve the task of joint KBC and KBQA to make them reinforce each other. However, existing studies usually rely on the small language model (SLM) to enhance them jointly, and the large language model (LLM)'s strong reasoning ability is ignored. In this paper, by combining the strengths of the LLM with the SLM, we propose a novel framework JCQL, which can make these two tasks enhance each other in an iterative manner. To make KBC enhance KBQA, we augment the LLM agent-based KBQA model's reasoning paths by incorporating an SLM-trained KBC model as an action of the agent, alleviating the LLM's hallucination and high computational costs issue in KBQA. To make KBQA enhance KBC, we incrementally fine-tune the KBC model by leveraging KBQA's reasoning paths as its supplementary training data, improving the ability of the SLM in KBC. Extensive experiments over two public benchmark data sets demonstrate that JCQL surpasses all baselines for both KBC and KBQA tasks.
* 20 pages, 11 figures
DiagLink: A Dual-User Diagnostic Assistance System by Synergizing Experts with LLMs and Knowledge Graphs
Jan 28, 2026The global shortage and uneven distribution of medical expertise continue to hinder equitable access to accurate diagnostic care. While existing intelligent diagnostic system have shown promise, most struggle with dual-user interaction, and dynamic knowledge integration -- limiting their real-world applicability. In this study, we present DiagLink, a dual-user diagnostic assistance system that synergizes large language models (LLMs), knowledge graphs (KGs), and medical experts to support both patients and physicians. DiagLink uses guided dialogues to elicit patient histories, leverages LLMs and KGs for collaborative reasoning, and incorporates physician oversight for continuous knowledge validation and evolution. The system provides a role-adaptive interface, dynamically visualized history, and unified multi-source evidence to improve both trust and usability. We evaluate DiagLink through user study, use cases and expert interviews, demonstrating its effectiveness in improving user satisfaction and diagnostic efficiency, while offering insights for the design of future AI-assisted diagnostic systems.
Enhancing Clinical Predictive Modeling through Model Complexity-Driven Class Proportion Tuning for Class Imbalanced Data: An Empirical Study on Opioid Overdose Prediction
May 09, 2023Class imbalance problems widely exist in the medical field and heavily deteriorates performance of clinical predictive models. Most techniques to alleviate the problem rebalance class proportions and they predominantly assume the rebalanced proportions should be a function of the original data and oblivious to the model one uses. This work challenges this prevailing assumption and proposes that links the optimal class proportions to the model complexity, thereby tuning the class proportions per model. Our experiments on the opioid overdose prediction problem highlight the performance gain of tuning class proportions. Rigorous regression analysis also confirms the advantages of the theoretical framework proposed and the statistically significant correlation between the hyperparameters controlling the model complexity and the optimal class proportions.
Reveal the Unknown: Out-of-Knowledge-Base Mention Discovery with Entity Linking
Feb 14, 2023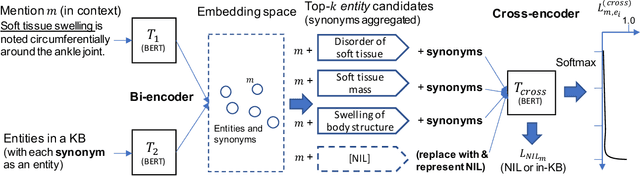
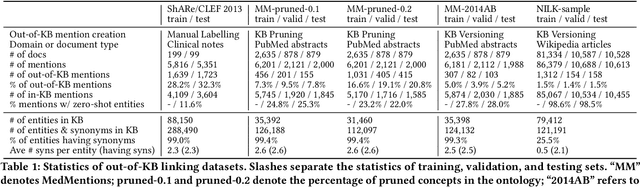
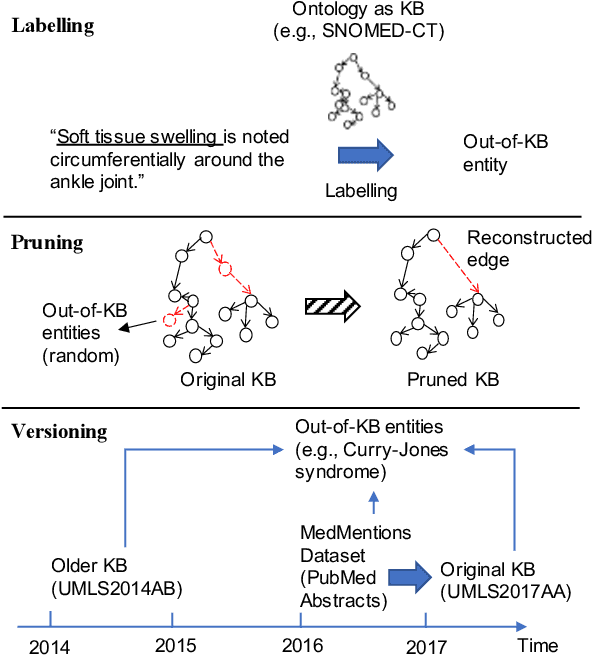
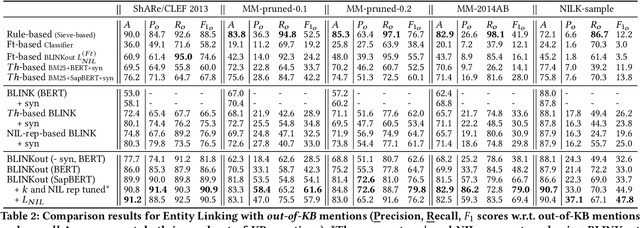
Discovering entity mentions that are out of a Knowledge Base (KB) from texts plays a critical role in KB maintenance, but has not yet been fully explored. The current methods are mostly limited to the simple threshold-based approach and feature-based classification; the datasets for evaluation are relatively rare. In this work, we propose BLINKout, a new BERT-based Entity Linking (EL) method which can identify mentions that do not have a corresponding KB entity by matching them to a special NIL entity. To this end, we integrate novel techniques including NIL representation, NIL classification, and synonym enhancement. We also propose Ontology Pruning and Versioning strategies to construct out-of-KB mentions from normal, in-KB EL datasets. Results on four datasets of clinical notes and publications show that BLINKout outperforms existing methods to detect out-of-KB mentions for medical ontologies UMLS and SNOMED CT.
Joint Open Knowledge Base Canonicalization and Linking
Dec 02, 2022Open Information Extraction (OIE) methods extract a large number of OIE triples (noun phrase, relation phrase, noun phrase) from text, which compose large Open Knowledge Bases (OKBs). However, noun phrases (NPs) and relation phrases (RPs) in OKBs are not canonicalized and often appear in different paraphrased textual variants, which leads to redundant and ambiguous facts. To address this problem, there are two related tasks: OKB canonicalization (i.e., convert NPs and RPs to canonicalized form) and OKB linking (i.e., link NPs and RPs with their corresponding entities and relations in a curated Knowledge Base (e.g., DBPedia). These two tasks are tightly coupled, and one task can benefit significantly from the other. However, they have been studied in isolation so far. In this paper, we explore the task of joint OKB canonicalization and linking for the first time, and propose a novel framework JOCL based on factor graph model to make them reinforce each other. JOCL is flexible enough to combine different signals from both tasks, and able to extend to fit any new signals. A thorough experimental study over two large scale OIE triple data sets shows that our framework outperforms all the baseline methods for the task of OKB canonicalization (OKB linking) in terms of average F1 (accuracy).
Low-resource Personal Attribute Prediction from Conversation
Nov 28, 2022



Personal knowledge bases (PKBs) are crucial for a broad range of applications such as personalized recommendation and Web-based chatbots. A critical challenge to build PKBs is extracting personal attribute knowledge from users' conversation data. Given some users of a conversational system, a personal attribute and these users' utterances, our goal is to predict the ranking of the given personal attribute values for each user. Previous studies often rely on a relative number of resources such as labeled utterances and external data, yet the attribute knowledge embedded in unlabeled utterances is underutilized and their performance of predicting some difficult personal attributes is still unsatisfactory. In addition, it is found that some text classification methods could be employed to resolve this task directly. However, they also perform not well over those difficult personal attributes. In this paper, we propose a novel framework PEARL to predict personal attributes from conversations by leveraging the abundant personal attribute knowledge from utterances under a low-resource setting in which no labeled utterances or external data are utilized. PEARL combines the biterm semantic information with the word co-occurrence information seamlessly via employing the updated prior attribute knowledge to refine the biterm topic model's Gibbs sampling process in an iterative manner. The extensive experimental results show that PEARL outperforms all the baseline methods not only on the task of personal attribute prediction from conversations over two data sets, but also on the more general weakly supervised text classification task over one data set.
Multi-View Clustering for Open Knowledge Base Canonicalization
Jun 22, 2022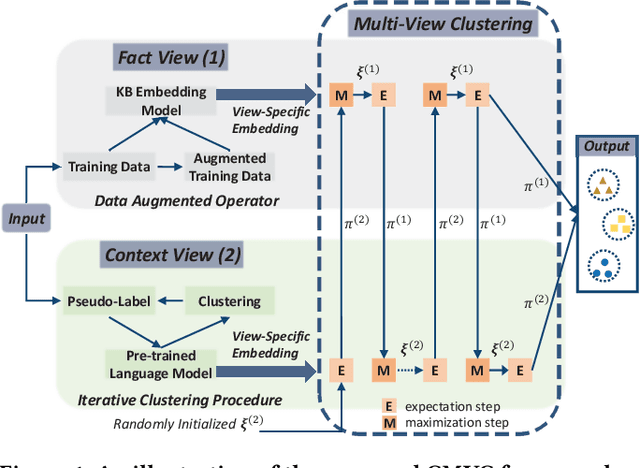
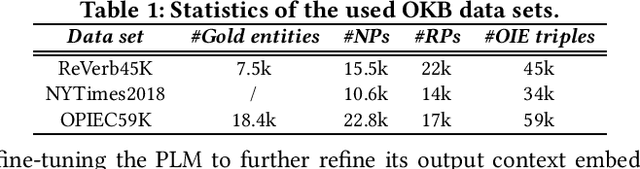
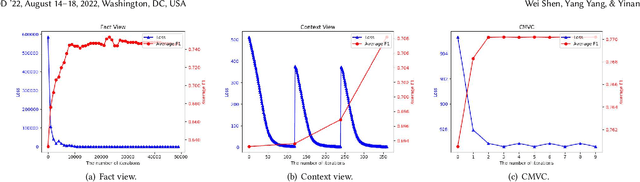
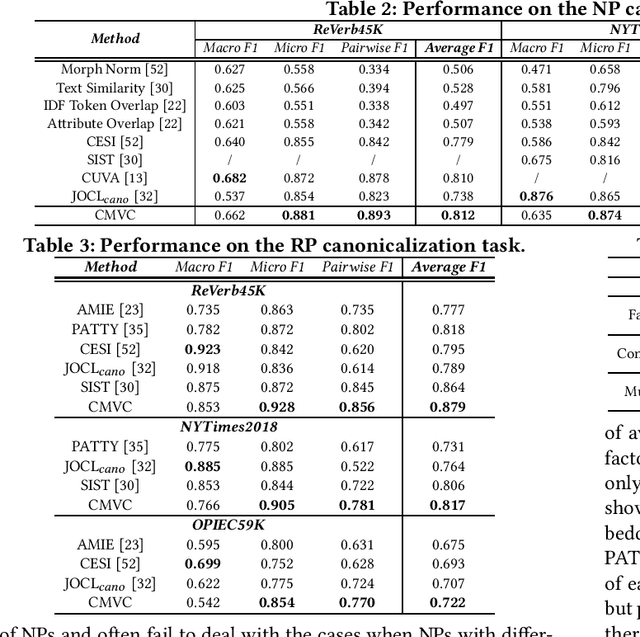
Open information extraction (OIE) methods extract plenty of OIE triples <noun phrase, relation phrase, noun phrase> from unstructured text, which compose large open knowledge bases (OKBs). Noun phrases and relation phrases in such OKBs are not canonicalized, which leads to scattered and redundant facts. It is found that two views of knowledge (i.e., a fact view based on the fact triple and a context view based on the fact triple's source context) provide complementary information that is vital to the task of OKB canonicalization, which clusters synonymous noun phrases and relation phrases into the same group and assigns them unique identifiers. However, these two views of knowledge have so far been leveraged in isolation by existing works. In this paper, we propose CMVC, a novel unsupervised framework that leverages these two views of knowledge jointly for canonicalizing OKBs without the need of manually annotated labels. To achieve this goal, we propose a multi-view CH K-Means clustering algorithm to mutually reinforce the clustering of view-specific embeddings learned from each view by considering their different clustering qualities. In order to further enhance the canonicalization performance, we propose a training data optimization strategy in terms of data quantity and data quality respectively in each particular view to refine the learned view-specific embeddings in an iterative manner. Additionally, we propose a Log-Jump algorithm to predict the optimal number of clusters in a data-driven way without requiring any labels. We demonstrate the superiority of our framework through extensive experiments on multiple real-world OKB data sets against state-of-the-art methods.
Entity Linking Meets Deep Learning: Techniques and Solutions
Sep 26, 2021
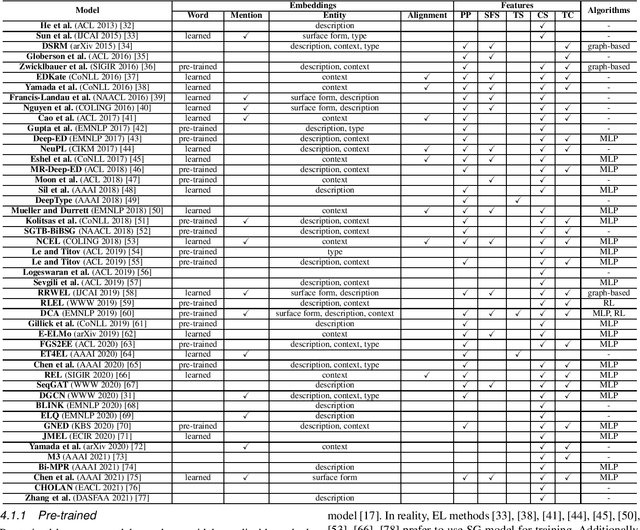
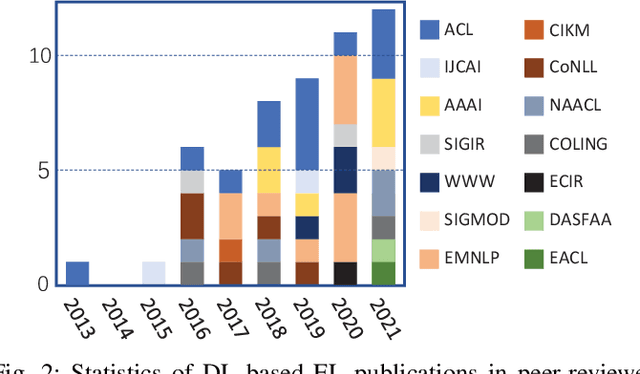
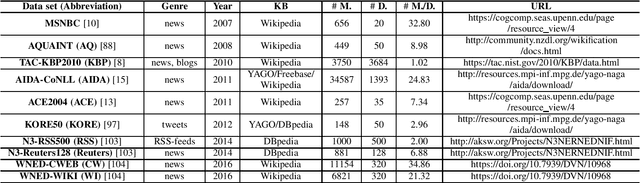
Entity linking (EL) is the process of linking entity mentions appearing in web text with their corresponding entities in a knowledge base. EL plays an important role in the fields of knowledge engineering and data mining, underlying a variety of downstream applications such as knowledge base population, content analysis, relation extraction, and question answering. In recent years, deep learning (DL), which has achieved tremendous success in various domains, has also been leveraged in EL methods to surpass traditional machine learning based methods and yield the state-of-the-art performance. In this survey, we present a comprehensive review and analysis of existing DL based EL methods. First of all, we propose a new taxonomy, which organizes existing DL based EL methods using three axes: embedding, feature, and algorithm. Then we systematically survey the representative EL methods along the three axes of the taxonomy. Later, we introduce ten commonly used EL data sets and give a quantitative performance analysis of DL based EL methods over these data sets. Finally, we discuss the remaining limitations of existing methods and highlight some promising future directions.
Subjective Bias in Abstractive Summarization
Jun 18, 2021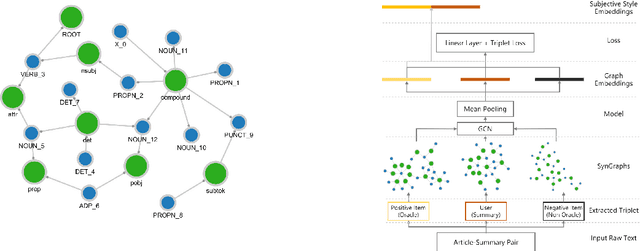

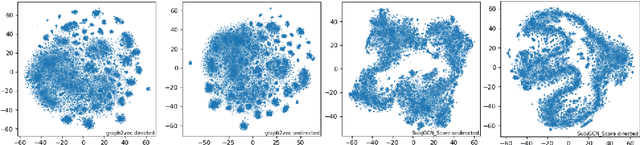
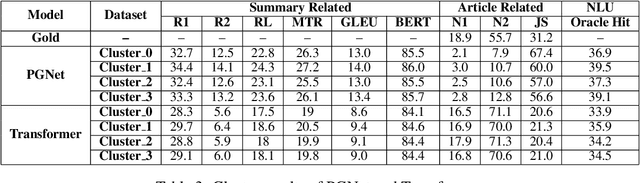
Due to the subjectivity of the summarization, it is a good practice to have more than one gold summary for each training document. However, many modern large-scale abstractive summarization datasets have only one-to-one samples written by different human with different styles. The impact of this phenomenon is understudied. We formulate the differences among possible multiple expressions summarizing the same content as subjective bias and examine the role of this bias in the context of abstractive summarization. In this paper a lightweight and effective method to extract the feature embeddings of subjective styles is proposed. Results of summarization models trained on style-clustered datasets show that there are certain types of styles that lead to better convergence, abstraction and generalization. The reproducible code and generated summaries are available online.