 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Clustering for Open Knowledge Base Canonicalization
Paper and Code
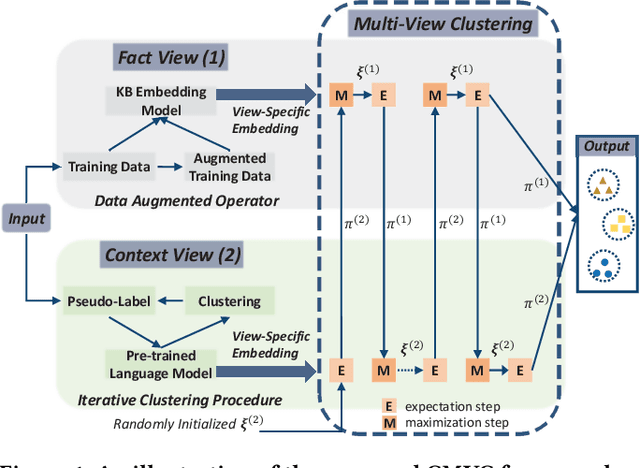
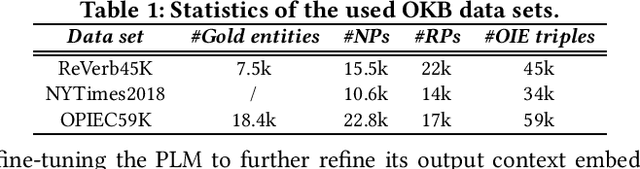
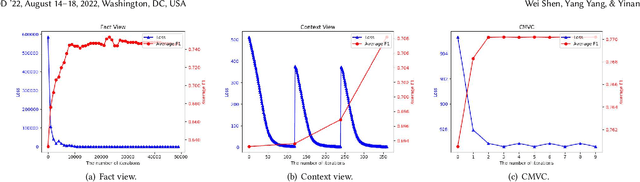
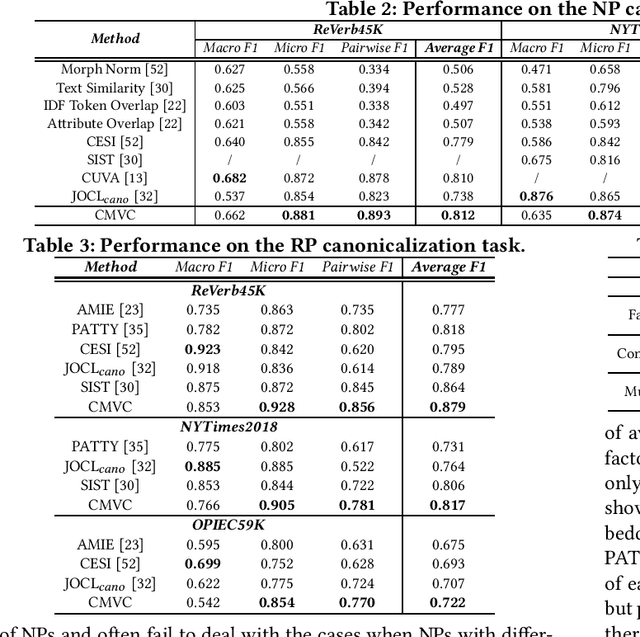
Open information extraction (OIE) methods extract plenty of OIE triples <noun phrase, relation phrase, noun phrase> from unstructured text, which compose large open knowledge bases (OKBs). Noun phrases and relation phrases in such OKBs are not canonicalized, which leads to scattered and redundant facts. It is found that two views of knowledge (i.e., a fact view based on the fact triple and a context view based on the fact triple's source context) provide complementary information that is vital to the task of OKB canonicalization, which clusters synonymous noun phrases and relation phrases into the same group and assigns them unique identifiers. However, these two views of knowledge have so far been leveraged in isolation by existing works. In this paper, we propose CMVC, a novel unsupervised framework that leverages these two views of knowledge jointly for canonicalizing OKBs without the need of manually annotated labels. To achieve this goal, we propose a multi-view CH K-Means clustering algorithm to mutually reinforce the clustering of view-specific embeddings learned from each view by considering their different clustering qualities. In order to further enhance the canonicalization performance, we propose a training data optimization strategy in terms of data quantity and data quality respectively in each particular view to refine the learned view-specific embeddings in an iterative manner. Additionally, we propose a Log-Jump algorithm to predict the optimal number of clusters in a data-driven way without requiring any labels. We demonstrate the superiority of our framework through extensive experiments on multiple real-world OKB data sets against state-of-the-art methods.