 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubjective Bias in Abstractive Summarization
Paper and Code
Jun 18, 2021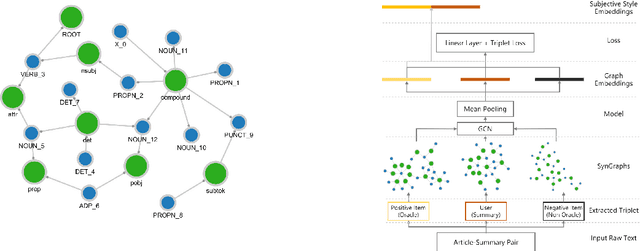

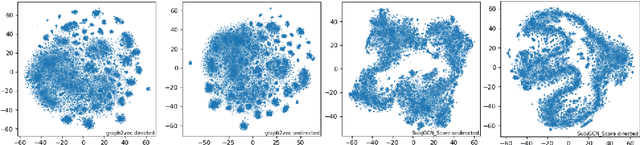
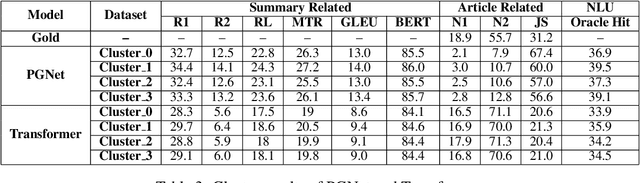
Due to the subjectivity of the summarization, it is a good practice to have more than one gold summary for each training document. However, many modern large-scale abstractive summarization datasets have only one-to-one samples written by different human with different styles. The impact of this phenomenon is understudied. We formulate the differences among possible multiple expressions summarizing the same content as subjective bias and examine the role of this bias in the context of abstractive summarization. In this paper a lightweight and effective method to extract the feature embeddings of subjective styles is proposed. Results of summarization models trained on style-clustered datasets show that there are certain types of styles that lead to better convergence, abstraction and generalization. The reproducible code and generated summaries are available online.