 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Large Language Models for Patient Information Extraction: Model Architecture, Fine-Tuning Strategy, and Multi-task Instruction Tuning
Sep 05, 2025



Natural language processing (NLP) is a key technology to extract important patient information from clinical narratives to support healthcare applications. The rapid development of large language models (LLMs) has revolutionized many NLP tasks in the clinical domain, yet their optimal use in patient information extraction tasks requires further exploration. This study examines LLMs' effectiveness in patient information extraction, focusing on LLM architectures, fine-tuning strategies, and multi-task instruction tuning techniques for developing robust and generalizable patient information extraction systems. This study aims to explore key concepts of using LLMs for clinical concept and relation extraction tasks, including: (1) encoder-only or decoder-only LLMs, (2) prompt-based parameter-efficient fine-tuning (PEFT) algorithms, and (3) multi-task instruction tuning on few-shot learning performance. We benchmarked a suite of LLMs, including encoder-based LLMs (BERT, GatorTron) and decoder-based LLMs (GatorTronGPT, Llama 3.1, GatorTronLlama), across five datasets. We compared traditional full-size fine-tuning and prompt-based PEFT. We explored a multi-task instruction tuning framework that combines both tasks across four datasets to evaluate the zero-shot and few-shot learning performance using the leave-one-dataset-out strategy.
Enhancing Clinical Predictive Modeling through Model Complexity-Driven Class Proportion Tuning for Class Imbalanced Data: An Empirical Study on Opioid Overdose Prediction
May 09, 2023Class imbalance problems widely exist in the medical field and heavily deteriorates performance of clinical predictive models. Most techniques to alleviate the problem rebalance class proportions and they predominantly assume the rebalanced proportions should be a function of the original data and oblivious to the model one uses. This work challenges this prevailing assumption and proposes that links the optimal class proportions to the model complexity, thereby tuning the class proportions per model. Our experiments on the opioid overdose prediction problem highlight the performance gain of tuning class proportions. Rigorous regression analysis also confirms the advantages of the theoretical framework proposed and the statistically significant correlation between the hyperparameters controlling the model complexity and the optimal class proportions.
A Multimodal Transformer: Fusing Clinical Notes with Structured EHR Data for Interpretable In-Hospital Mortality Prediction
Aug 09, 2022
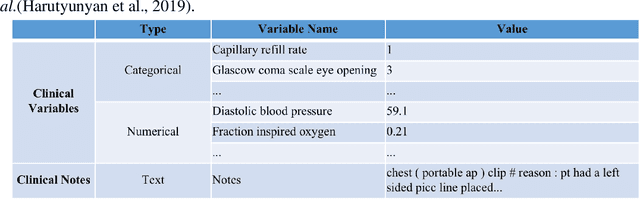
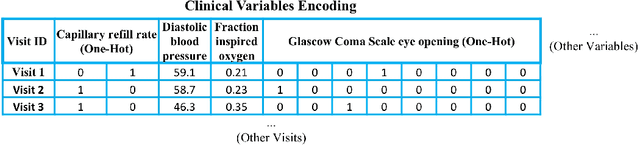
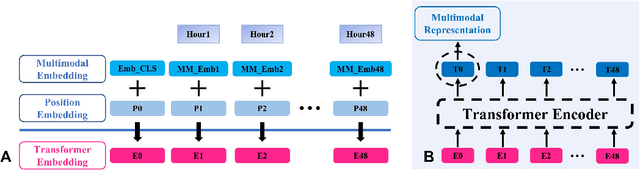
Deep-learning-based clinical decision support using structured electronic health records (EHR) has been an active research area for predicting risks of mortality and diseases. Meanwhile, large amounts of narrative clinical notes provide complementary information, but are often not integrated into predictive models. In this paper, we provide a novel multimodal transformer to fuse clinical notes and structured EHR data for better prediction of in-hospital mortality. To improve interpretability, we propose an integrated gradients (IG) method to select important words in clinical notes and discover the critical structured EHR features with Shapley values. These important words and clinical features are visualized to assist with interpretation of the prediction outcomes. We also investigate the significance of domain adaptive pretraining and task adaptive fine-tuning on the Clinical BERT, which is used to learn the representations of clinical notes. Experiments demonstrated that our model outperforms other methods (AUCPR: 0.538, AUCROC: 0.877, F1:0.490).
Identifying Risk of Opioid Use Disorder for Patients Taking Opioid Medications with Deep Learning
Oct 09, 2020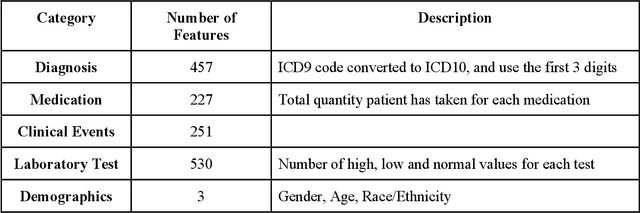
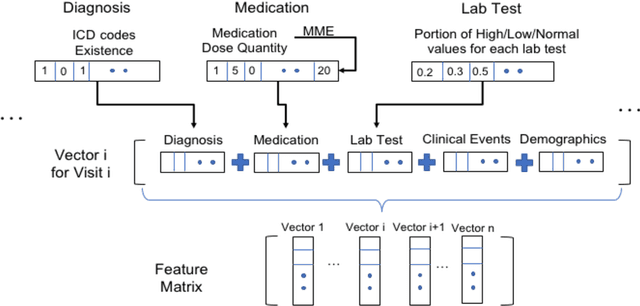
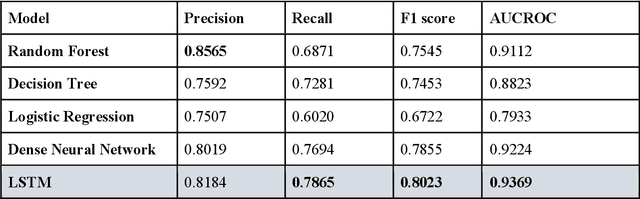
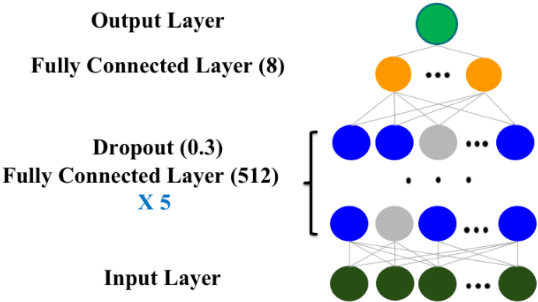
The United States is experiencing an opioid epidemic, and there were more than 10 million opioid misusers aged 12 or older each year. Identifying patients at high risk of Opioid Use Disorder (OUD) can help to make early clinical interventions to reduce the risk of OUD. Our goal is to predict OUD patients among opioid prescription users through analyzing electronic health records with machine learning and deep learning methods. This will help us to better understand the diagnoses of OUD, providing new insights on opioid epidemic. Electronic health records of patients who have been prescribed with medications containing active opioid ingredients were extracted from Cerner Health Facts database between January 1, 2008 and December 31, 2017. Long Short-Term Memory (LSTM) models were applied to predict opioid use disorder risk in the future based on recent five encounters, and compared to Logistic Regression, Random Forest, Decision Tree and Dense Neural Network. Prediction performance was assessed using F-1 score, precision, recall, and AUROC. Our temporal deep learning model provided promising prediction results which outperformed other methods, with a F1 score of 0.8023 and AUCROC of 0.9369. The model can identify OUD related medications and vital signs as important features for the prediction. LSTM based temporal deep learning model is effective on predicting opioid use disorder using a patient past history of electronic health records, with minimal domain knowledge. It has potential to improve clinical decision support for early intervention and prevention to combat the opioid epidemic.
Disease phenotyping using deep learning: A diabetes case study
Nov 28, 2018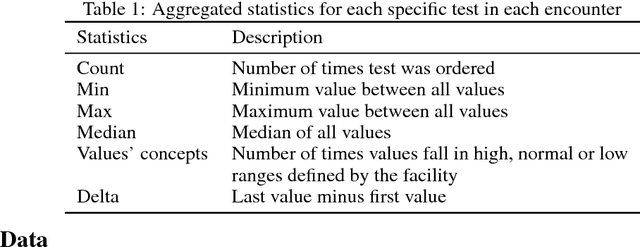
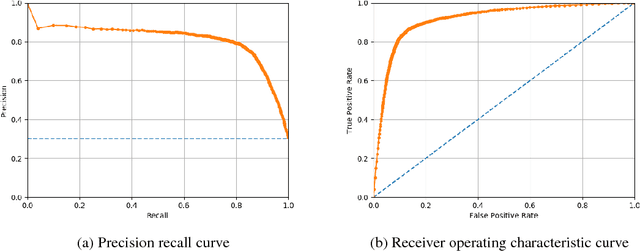
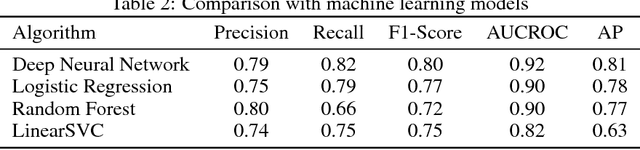
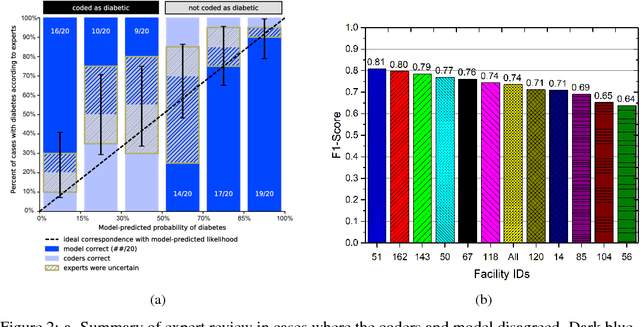
Characterization of a patient clinical phenotype is central to biomedical informatics. ICD codes, assigned to inpatient encounters by coders, is important for population health and cohort discovery when clinical information is limited. While ICD codes are assigned to patients by professionals trained and certified in coding there is substantial variability in coding. We present a methodology that uses deep learning methods to model coder decision making and that predicts ICD codes. Our approach predicts codes based on demographics, lab results, and medications, as well as codes from previous encounters. We are able to predict existing codes with high accuracy for all three of the test cases we investigated: diabetes, acute renal failure, and chronic kidney disease. We employed a panel of clinicians, in a blinded manner, to assess ground truth and compared the predictions of coders, model and clinicians. When disparities between the model prediction and coder assigned codes were reviewed, our model outperformed coder assigned ICD codes.