 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisease phenotyping using deep learning: A diabetes case study
Paper and Code
Nov 28, 2018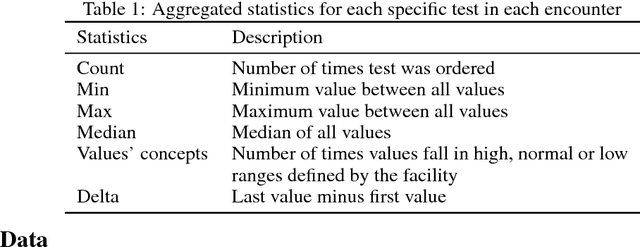
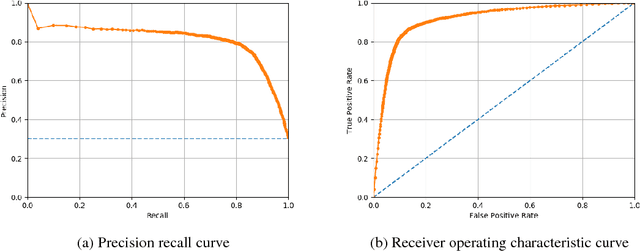
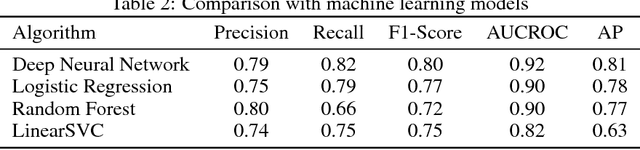
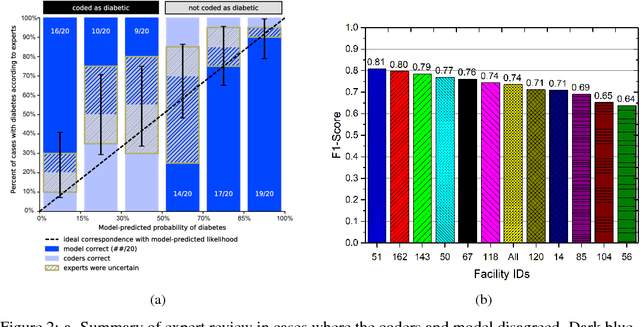
Characterization of a patient clinical phenotype is central to biomedical informatics. ICD codes, assigned to inpatient encounters by coders, is important for population health and cohort discovery when clinical information is limited. While ICD codes are assigned to patients by professionals trained and certified in coding there is substantial variability in coding. We present a methodology that uses deep learning methods to model coder decision making and that predicts ICD codes. Our approach predicts codes based on demographics, lab results, and medications, as well as codes from previous encounters. We are able to predict existing codes with high accuracy for all three of the test cases we investigated: diabetes, acute renal failure, and chronic kidney disease. We employed a panel of clinicians, in a blinded manner, to assess ground truth and compared the predictions of coders, model and clinicians. When disparities between the model prediction and coder assigned codes were reviewed, our model outperformed coder assigned ICD codes.