 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText4Seg: Reimagining Image Segmentation as Text Generation
Paper and Code

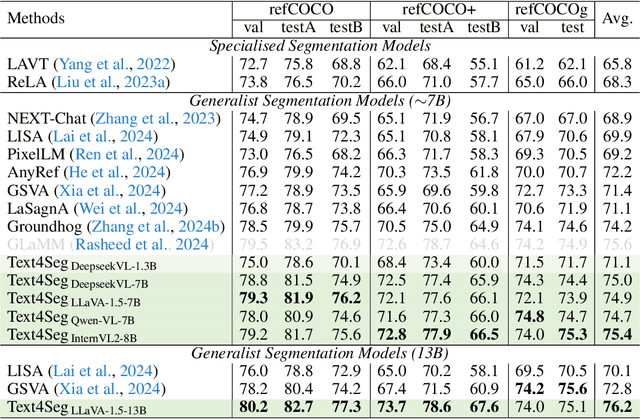
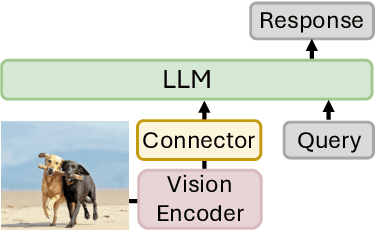
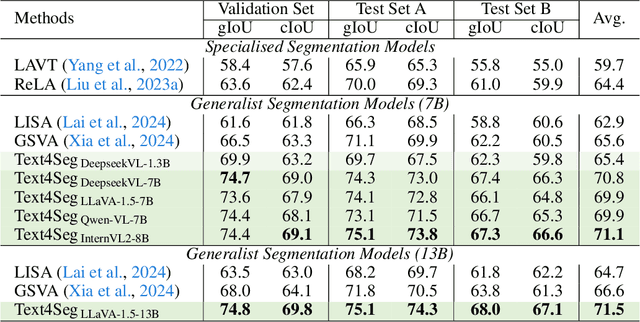
Multimodal Large Language Models (MLLMs) have shown exceptional capabilities in vision-language tasks; however, effectively integrating image segmentation into these models remains a significant challenge. In this paper, we introduce Text4Seg, a novel text-as-mask paradigm that casts image segmentation as a text generation problem, eliminating the need for additional decoders and significantly simplifying the segmentation process. Our key innovation is semantic descriptors, a new textual representation of segmentation masks where each image patch is mapped to its corresponding text label. This unified representation allows seamless integration into the auto-regressive training pipeline of MLLMs for easier optimization. We demonstrate that representing an image with $16\times16$ semantic descriptors yields competitive segmentation performance. To enhance efficiency, we introduce the Row-wise Run-Length Encoding (R-RLE), which compresses redundant text sequences, reducing the length of semantic descriptors by 74% and accelerating inference by $3\times$, without compromising performance. Extensive experiments across various vision tasks, such as referring expression segmentation and comprehension, show that Text4Seg achieves state-of-the-art performance on multiple datasets by fine-tuning different MLLM backbones. Our approach provides an efficient, scalable solution for vision-centric tasks within the MLLM framework.