 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmile on the Face, Sadness in the Eyes: Bridging the Emotion Gap with a Multimodal Dataset of Eye and Facial Behaviors
Dec 18, 2025Emotion Recognition (ER) is the process of analyzing and identifying human emotions from sensing data. Currently, the field heavily relies on facial expression recognition (FER) because visual channel conveys rich emotional cues. However, facial expressions are often used as social tools rather than manifestations of genuine inner emotions. To understand and bridge this gap between FER and ER, we introduce eye behaviors as an important emotional cue and construct an Eye-behavior-aided Multimodal Emotion Recognition (EMER) dataset. To collect data with genuine emotions, spontaneous emotion induction paradigm is exploited with stimulus material, during which non-invasive eye behavior data, like eye movement sequences and eye fixation maps, is captured together with facial expression videos. To better illustrate the gap between ER and FER, multi-view emotion labels for mutimodal ER and FER are separately annotated. Furthermore, based on the new dataset, we design a simple yet effective Eye-behavior-aided MER Transformer (EMERT) that enhances ER by bridging the emotion gap. EMERT leverages modality-adversarial feature decoupling and a multitask Transformer to model eye behaviors as a strong complement to facial expressions. In the experiment, we introduce seven multimodal benchmark protocols for a variety of comprehensive evaluations of the EMER dataset. The results show that the EMERT outperforms other state-of-the-art multimodal methods by a great margin, revealing the importance of modeling eye behaviors for robust ER. To sum up, we provide a comprehensive analysis of the importance of eye behaviors in ER, advancing the study on addressing the gap between FER and ER for more robust ER performance. Our EMER dataset and the trained EMERT models will be publicly available at https://github.com/kejun1/EMER.
Smile upon the Face but Sadness in the Eyes: Emotion Recognition based on Facial Expressions and Eye Behaviors
Nov 19, 2024



Emotion Recognition (ER) is the process of identifying human emotions from given data. Currently, the field heavily relies on facial expression recognition (FER) because facial expressions contain rich emotional cues. However, it is important to note that facial expressions may not always precisely reflect genuine emotions and FER-based results may yield misleading ER. To understand and bridge this gap between FER and ER, we introduce eye behaviors as an important emotional cues for the creation of a new Eye-behavior-aided Multimodal Emotion Recognition (EMER) dataset. Different from existing multimodal ER datasets, the EMER dataset employs a stimulus material-induced spontaneous emotion generation method to integrate non-invasive eye behavior data, like eye movements and eye fixation maps, with facial videos, aiming to obtain natural and accurate human emotions. Notably, for the first time, we provide annotations for both ER and FER in the EMER, enabling a comprehensive analysis to better illustrate the gap between both tasks. Furthermore, we specifically design a new EMERT architecture to concurrently enhance performance in both ER and FER by efficiently identifying and bridging the emotion gap between the two.Specifically, our EMERT employs modality-adversarial feature decoupling and multi-task Transformer to augment the modeling of eye behaviors, thus providing an effective complement to facial expressions. In the experiment, we introduce seven multimodal benchmark protocols for a variety of comprehensive evaluations of the EMER dataset. The results show that the EMERT outperforms other state-of-the-art multimodal methods by a great margin, revealing the importance of modeling eye behaviors for robust ER. To sum up, we provide a comprehensive analysis of the importance of eye behaviors in ER, advancing the study on addressing the gap between FER and ER for more robust ER performance.
Learning Language-guided Adaptive Hyper-modality Representation for Multimodal Sentiment Analysis
Oct 09, 2023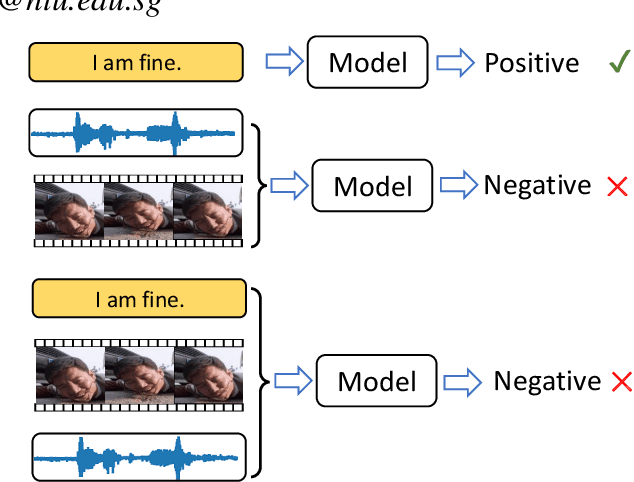
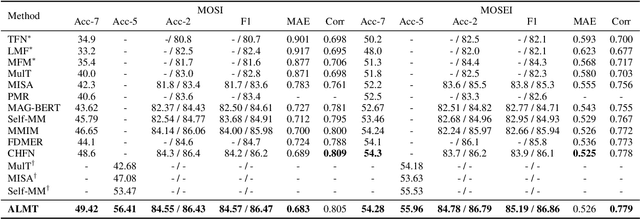
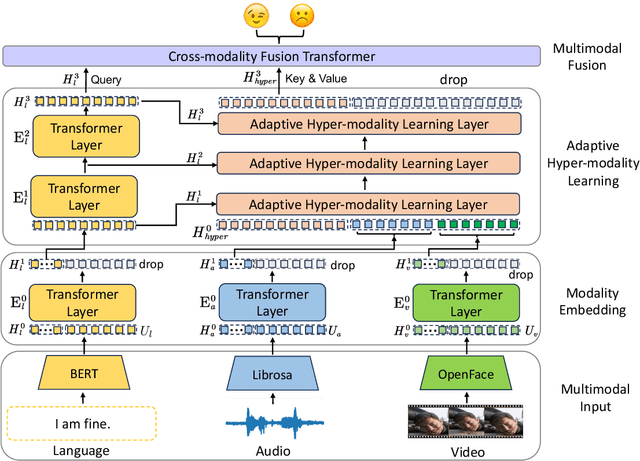
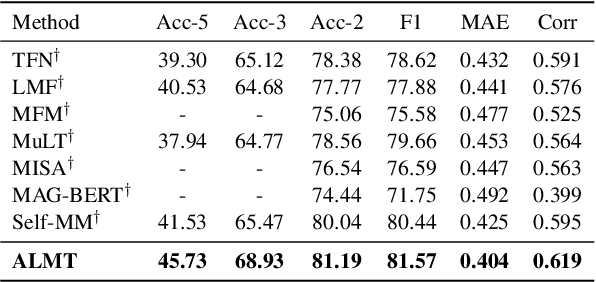
Though Multimodal Sentiment Analysis (MSA) proves effective by utilizing rich information from multiple sources (e.g., language, video, and audio), the potential sentiment-irrelevant and conflicting information across modalities may hinder the performance from being further improved. To alleviate this, we present Adaptive Language-guided Multimodal Transformer (ALMT), which incorporates an Adaptive Hyper-modality Learning (AHL) module to learn an irrelevance/conflict-suppressing representation from visual and audio features under the guidance of language features at different scales. With the obtained hyper-modality representation, the model can obtain a complementary and joint representation through multimodal fusion for effective MSA. In practice, ALMT achieves state-of-the-art performance on several popular datasets (e.g., MOSI, MOSEI and CH-SIMS) and an abundance of ablation demonstrates the validity and necessity of our irrelevance/conflict suppression mechanism.
Pose-disentangled Contrastive Learning for Self-supervised Facial Representation
Nov 24, 2022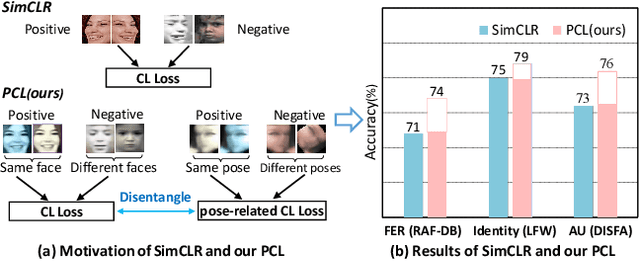
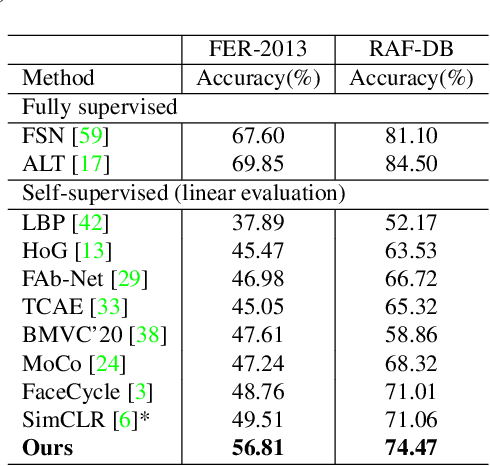
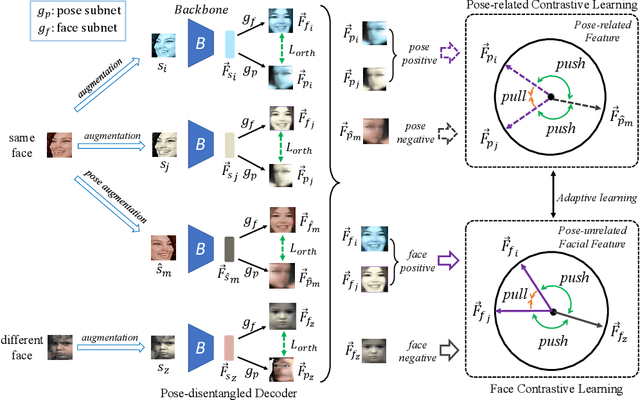
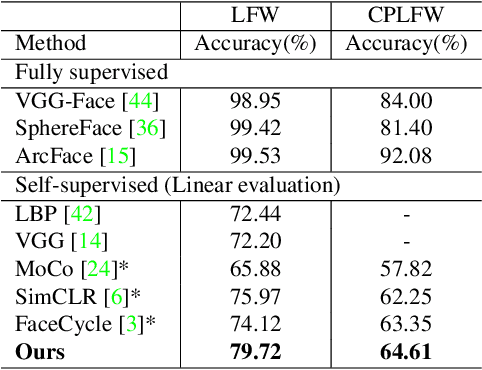
Self-supervised facial representation has recently attracted increasing attention due to its ability to perform face understanding without relying on large-scale annotated datasets heavily. However, analytically, current contrastive-based self-supervised learning still performs unsatisfactorily for learning facial representation. More specifically, existing contrastive learning (CL) tends to learn pose-invariant features that cannot depict the pose details of faces, compromising the learning performance. To conquer the above limitation of CL, we propose a novel Pose-disentangled Contrastive Learning (PCL) method for general self-supervised facial representation. Our PCL first devises a pose-disentangled decoder (PDD) with a delicately designed orthogonalizing regulation, which disentangles the pose-related features from the face-aware features; therefore, pose-related and other pose-unrelated facial information could be performed in individual subnetworks and do not affect each other's training. Furthermore, we introduce a pose-related contrastive learning scheme that learns pose-related information based on data augmentation of the same image, which would deliver more effective face-aware representation for various downstream tasks. We conducted a comprehensive linear evaluation on three challenging downstream facial understanding tasks, i.e., facial expression recognition, face recognition, and AU detection. Experimental results demonstrate that our method outperforms cutting-edge contrastive and other self-supervised learning methods with a great margin.