 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLA-Aware Distributed LLM Inference Across Device-RAN-Cloud
Feb 27, 2026Embodied AI requires sub-second inference near the Radio Access Network (RAN), but deployments span heterogeneous tiers (on-device, RAN-edge, cloud) and must not disrupt real-time baseband processing. We report measurements from a 5G Standalone (SA) AI-RAN testbed using a fixed baseline policy for repeatability. The setup includes an on-device tier, a three-node RAN-edge cluster co-hosting a containerized 5G RAN, and a cloud tier. We find that on-device execution remains multi-second and fails to meet sub-second budgets. At the RAN edge, SLA feasibility is primarily determined by model variant choice: quantized models concentrate below 0.5\,s, while unquantized and some larger quantized models incur deadline misses due to stalls and queuing. In the cloud tier, meeting a 0.5\,s deadline is challenging on the measured WAN path (up to 32.9\% of requests complete within 0.5\,s), but all evaluated variants meet a 1.0\,s deadline (100\% within 1.0\,s). Under saturated downlink traffic and up to $N{=}20$ concurrent inference clients, Multi-Instance GPU (MIG) isolation preserves baseband timing-health proxies, supporting safe co-location under fixed partitioning.
Smile on the Face, Sadness in the Eyes: Bridging the Emotion Gap with a Multimodal Dataset of Eye and Facial Behaviors
Dec 18, 2025Emotion Recognition (ER) is the process of analyzing and identifying human emotions from sensing data. Currently, the field heavily relies on facial expression recognition (FER) because visual channel conveys rich emotional cues. However, facial expressions are often used as social tools rather than manifestations of genuine inner emotions. To understand and bridge this gap between FER and ER, we introduce eye behaviors as an important emotional cue and construct an Eye-behavior-aided Multimodal Emotion Recognition (EMER) dataset. To collect data with genuine emotions, spontaneous emotion induction paradigm is exploited with stimulus material, during which non-invasive eye behavior data, like eye movement sequences and eye fixation maps, is captured together with facial expression videos. To better illustrate the gap between ER and FER, multi-view emotion labels for mutimodal ER and FER are separately annotated. Furthermore, based on the new dataset, we design a simple yet effective Eye-behavior-aided MER Transformer (EMERT) that enhances ER by bridging the emotion gap. EMERT leverages modality-adversarial feature decoupling and a multitask Transformer to model eye behaviors as a strong complement to facial expressions. In the experiment, we introduce seven multimodal benchmark protocols for a variety of comprehensive evaluations of the EMER dataset. The results show that the EMERT outperforms other state-of-the-art multimodal methods by a great margin, revealing the importance of modeling eye behaviors for robust ER. To sum up, we provide a comprehensive analysis of the importance of eye behaviors in ER, advancing the study on addressing the gap between FER and ER for more robust ER performance. Our EMER dataset and the trained EMERT models will be publicly available at https://github.com/kejun1/EMER.
Smile upon the Face but Sadness in the Eyes: Emotion Recognition based on Facial Expressions and Eye Behaviors
Nov 19, 2024



Emotion Recognition (ER) is the process of identifying human emotions from given data. Currently, the field heavily relies on facial expression recognition (FER) because facial expressions contain rich emotional cues. However, it is important to note that facial expressions may not always precisely reflect genuine emotions and FER-based results may yield misleading ER. To understand and bridge this gap between FER and ER, we introduce eye behaviors as an important emotional cues for the creation of a new Eye-behavior-aided Multimodal Emotion Recognition (EMER) dataset. Different from existing multimodal ER datasets, the EMER dataset employs a stimulus material-induced spontaneous emotion generation method to integrate non-invasive eye behavior data, like eye movements and eye fixation maps, with facial videos, aiming to obtain natural and accurate human emotions. Notably, for the first time, we provide annotations for both ER and FER in the EMER, enabling a comprehensive analysis to better illustrate the gap between both tasks. Furthermore, we specifically design a new EMERT architecture to concurrently enhance performance in both ER and FER by efficiently identifying and bridging the emotion gap between the two.Specifically, our EMERT employs modality-adversarial feature decoupling and multi-task Transformer to augment the modeling of eye behaviors, thus providing an effective complement to facial expressions. In the experiment, we introduce seven multimodal benchmark protocols for a variety of comprehensive evaluations of the EMER dataset. The results show that the EMERT outperforms other state-of-the-art multimodal methods by a great margin, revealing the importance of modeling eye behaviors for robust ER. To sum up, we provide a comprehensive analysis of the importance of eye behaviors in ER, advancing the study on addressing the gap between FER and ER for more robust ER performance.
Noise-Resistant Multimodal Transformer for Emotion Recognition
May 04, 2023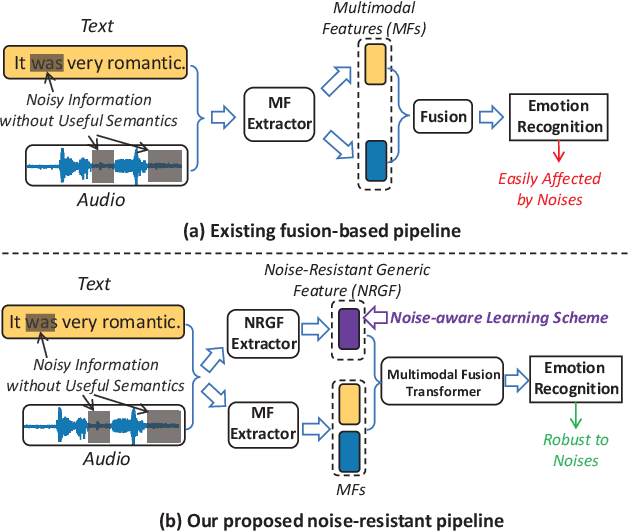
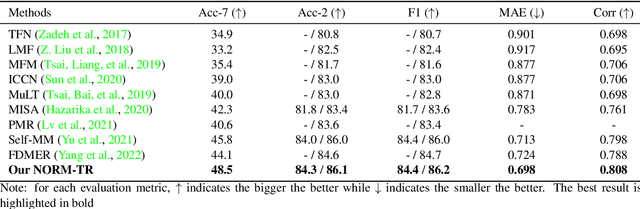
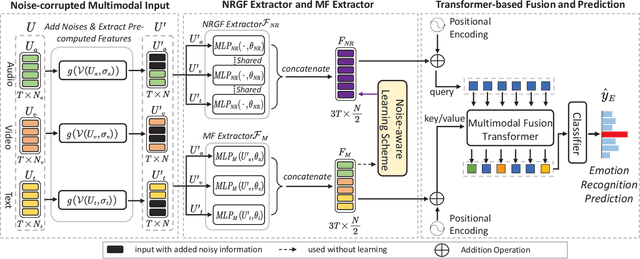
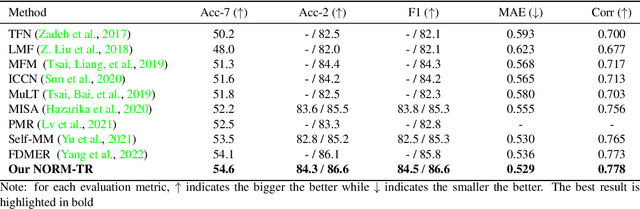
Multimodal emotion recognition identifies human emotions from various data modalities like video, text, and audio. However, we found that this task can be easily affected by noisy information that does not contain useful semantics. To this end, we present a novel paradigm that attempts to extract noise-resistant features in its pipeline and introduces a noise-aware learning scheme to effectively improve the robustness of multimodal emotion understanding. Our new pipeline, namely Noise-Resistant Multimodal Transformer (NORM-TR), mainly introduces a Noise-Resistant Generic Feature (NRGF) extractor and a Transformer for the multimodal emotion recognition task. In particular, we make the NRGF extractor learn a generic and disturbance-insensitive representation so that consistent and meaningful semantics can be obtained. Furthermore, we apply a Transformer to incorporate Multimodal Features (MFs) of multimodal inputs based on their relations to the NRGF. Therefore, the possible insensitive but useful information of NRGF could be complemented by MFs that contain more details. To train the NORM-TR properly, our proposed noise-aware learning scheme complements normal emotion recognition losses by enhancing the learning against noises. Our learning scheme explicitly adds noises to either all the modalities or a specific modality at random locations of a multimodal input sequence. We correspondingly introduce two adversarial losses to encourage the NRGF extractor to learn to extract the NRGFs invariant to the added noises, thus facilitating the NORM-TR to achieve more favorable multimodal emotion recognition performance. In practice, on several popular multimodal datasets, our NORM-TR achieves state-of-the-art performance and outperforms existing methods by a large margin, which demonstrates that the ability to resist noisy information is important for effective emotion recognition.