 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Resistant Multimodal Transformer for Emotion Recognition
Paper and Code
May 04, 2023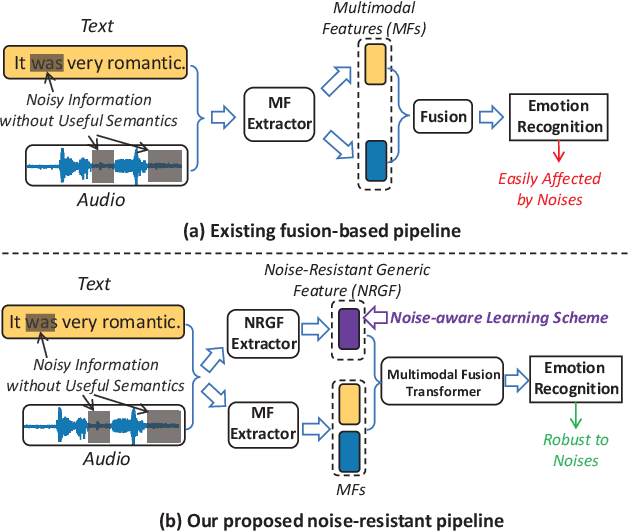
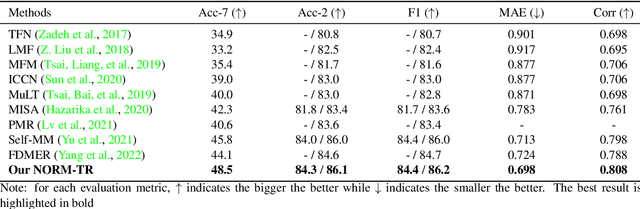
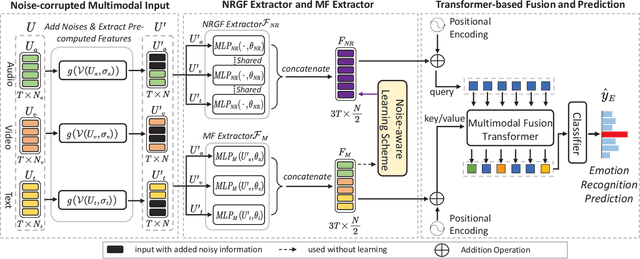
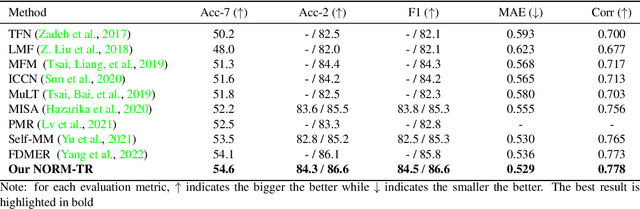
Multimodal emotion recognition identifies human emotions from various data modalities like video, text, and audio. However, we found that this task can be easily affected by noisy information that does not contain useful semantics. To this end, we present a novel paradigm that attempts to extract noise-resistant features in its pipeline and introduces a noise-aware learning scheme to effectively improve the robustness of multimodal emotion understanding. Our new pipeline, namely Noise-Resistant Multimodal Transformer (NORM-TR), mainly introduces a Noise-Resistant Generic Feature (NRGF) extractor and a Transformer for the multimodal emotion recognition task. In particular, we make the NRGF extractor learn a generic and disturbance-insensitive representation so that consistent and meaningful semantics can be obtained. Furthermore, we apply a Transformer to incorporate Multimodal Features (MFs) of multimodal inputs based on their relations to the NRGF. Therefore, the possible insensitive but useful information of NRGF could be complemented by MFs that contain more details. To train the NORM-TR properly, our proposed noise-aware learning scheme complements normal emotion recognition losses by enhancing the learning against noises. Our learning scheme explicitly adds noises to either all the modalities or a specific modality at random locations of a multimodal input sequence. We correspondingly introduce two adversarial losses to encourage the NRGF extractor to learn to extract the NRGFs invariant to the added noises, thus facilitating the NORM-TR to achieve more favorable multimodal emotion recognition performance. In practice, on several popular multimodal datasets, our NORM-TR achieves state-of-the-art performance and outperforms existing methods by a large margin, which demonstrates that the ability to resist noisy information is important for effective emotion recognition.