 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain-Specific Deblurring using Scale-Specific Attention
Paper and Code
Dec 12, 2021
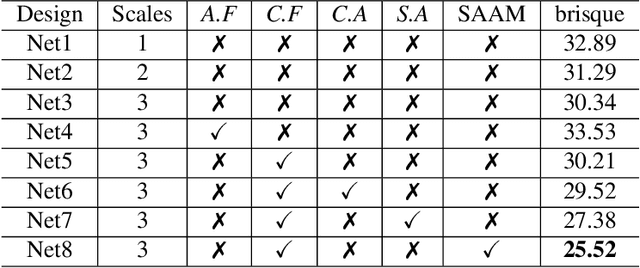
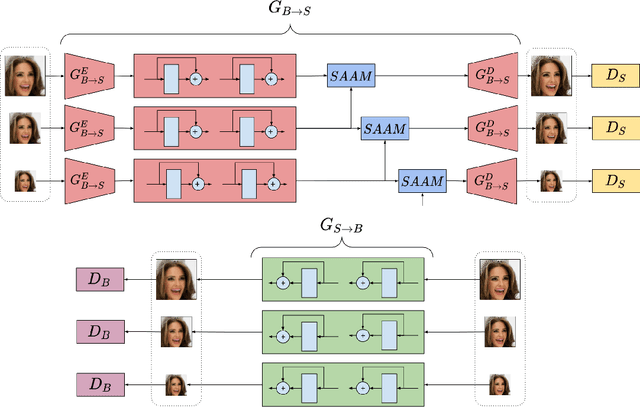
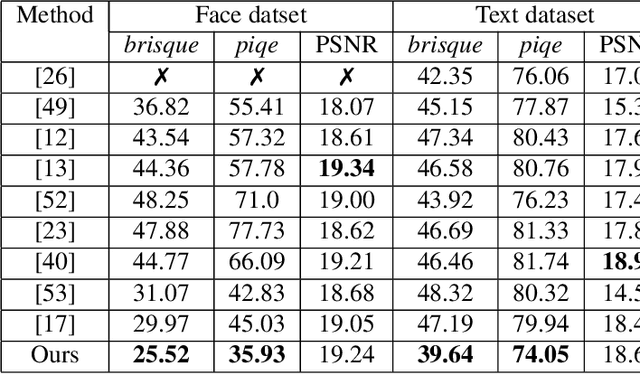
In the literature, coarse-to-fine or scale-recurrent approach i.e. progressively restoring a clean image from its low-resolution versions has been successfully employed for single image deblurring. However, a major disadvantage of existing methods is the need for paired data; i.e. sharpblur image pairs of the same scene, which is a complicated and cumbersome acquisition procedure. Additionally, due to strong supervision on loss functions, pre-trained models of such networks are strongly biased towards the blur experienced during training and tend to give sub-optimal performance when confronted by new blur kernels during inference time. To address the above issues, we propose unsupervised domain-specific deblurring using a scale-adaptive attention module (SAAM). Our network does not require supervised pairs for training, and the deblurring mechanism is primarily guided by adversarial loss, thus making our network suitable for a distribution of blur functions. Given a blurred input image, different resolutions of the same image are used in our model during training and SAAM allows for effective flow of information across the resolutions. For network training at a specific scale, SAAM attends to lower scale features as a function of the current scale. Different ablation studies show that our coarse-to-fine mechanism outperforms end-to-end unsupervised models and SAAM is able to attend better compared to attention models used in literature. Qualitative and quantitative comparisons (on no-reference metrics) show that our method outperforms prior unsupervised methods.