 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
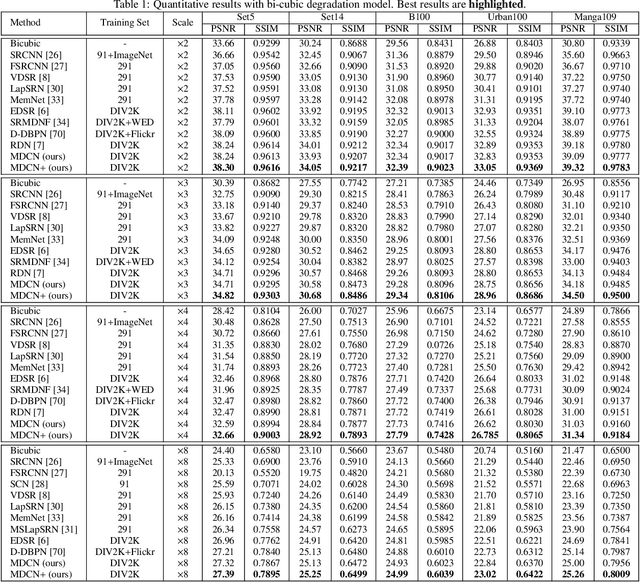
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Spatially-Attentive Patch-Hierarchical Network with Adaptive Sampling for Motion Deblurring
Feb 09, 2024
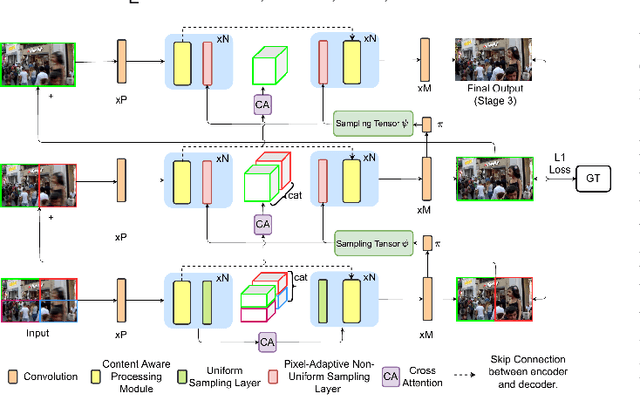
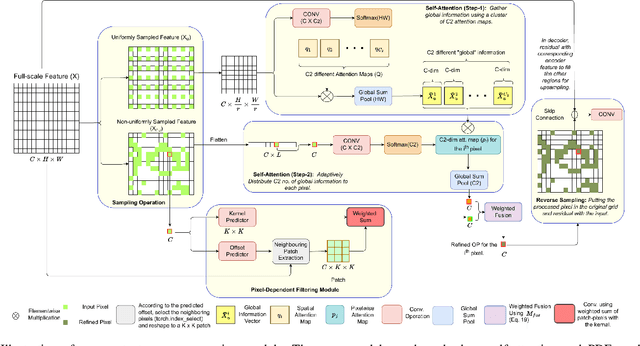
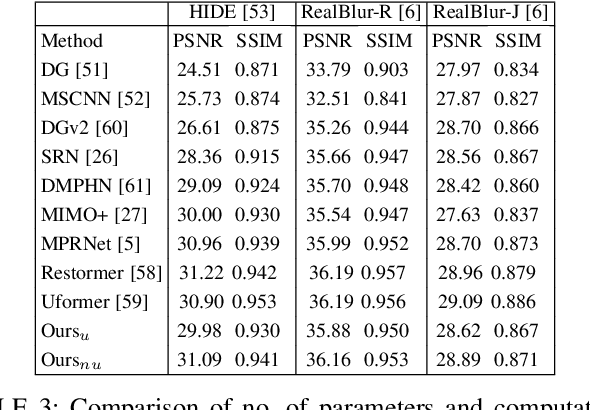
This paper tackles the problem of motion deblurring of dynamic scenes. Although end-to-end fully convolutional designs have recently advanced the state-of-the-art in non-uniform motion deblurring, their performance-complexity trade-off is still sub-optimal. Most existing approaches achieve a large receptive field by increasing the number of generic convolution layers and kernel size. In this work, we propose a pixel adaptive and feature attentive design for handling large blur variations across different spatial locations and process each test image adaptively. We design a content-aware global-local filtering module that significantly improves performance by considering not only global dependencies but also by dynamically exploiting neighboring pixel information. We further introduce a pixel-adaptive non-uniform sampling strategy that implicitly discovers the difficult-to-restore regions present in the image and, in turn, performs fine-grained refinement in a progressive manner. Extensive qualitative and quantitative comparisons with prior art on deblurring benchmarks demonstrate that our approach performs favorably against the state-of-the-art deblurring algorithms.
Unfolding a blurred image
Jan 28, 2022We present a solution for the goal of extracting a video from a single motion blurred image to sequentially reconstruct the clear views of a scene as beheld by the camera during the time of exposure. We first learn motion representation from sharp videos in an unsupervised manner through training of a convolutional recurrent video autoencoder network that performs a surrogate task of video reconstruction. Once trained, it is employed for guided training of a motion encoder for blurred images. This network extracts embedded motion information from the blurred image to generate a sharp video in conjunction with the trained recurrent video decoder. As an intermediate step, we also design an efficient architecture that enables real-time single image deblurring and outperforms competing methods across all factors: accuracy, speed, and compactness. Experiments on real scenes and standard datasets demonstrate the superiority of our framework over the state-of-the-art and its ability to generate a plausible sequence of temporally consistent sharp frames.
Image Superresolution using Scale-Recurrent Dense Network
Jan 28, 2022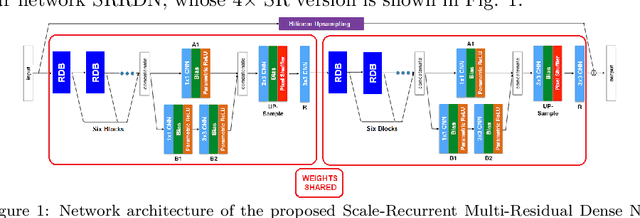

Recent advances in the design of convolutional neural network (CNN) have yielded significant improvements in the performance of image super-resolution (SR). The boost in performance can be attributed to the presence of residual or dense connections within the intermediate layers of these networks. The efficient combination of such connections can reduce the number of parameters drastically while maintaining the restoration quality. In this paper, we propose a scale recurrent SR architecture built upon units containing series of dense connections within a residual block (Residual Dense Blocks (RDBs)) that allow extraction of abundant local features from the image. Our scale recurrent design delivers competitive performance for higher scale factors while being parametrically more efficient as compared to current state-of-the-art approaches. To further improve the performance of our network, we employ multiple residual connections in intermediate layers (referred to as Multi-Residual Dense Blocks), which improves gradient propagation in existing layers. Recent works have discovered that conventional loss functions can guide a network to produce results which have high PSNRs but are perceptually inferior. We mitigate this issue by utilizing a Generative Adversarial Network (GAN) based framework and deep feature (VGG) losses to train our network. We experimentally demonstrate that different weighted combinations of the VGG loss and the adversarial loss enable our network outputs to traverse along the perception-distortion curve. The proposed networks perform favorably against existing methods, both perceptually and objectively (PSNR-based) with fewer parameters.
Deep Networks for Image and Video Super-Resolution
Jan 28, 2022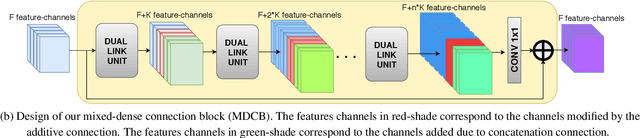
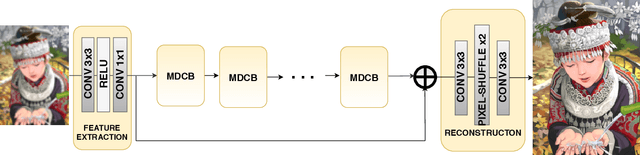
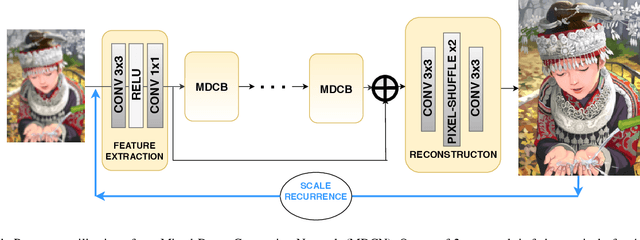
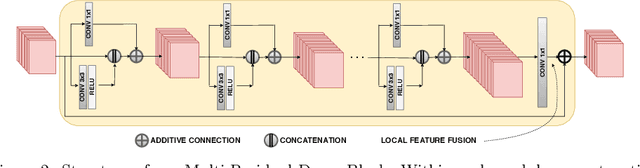
Efficiency of gradient propagation in intermediate layers of convolutional neural networks is of key importance for super-resolution task. To this end, we propose a deep architecture for single image super-resolution (SISR), which is built using efficient convolutional units we refer to as mixed-dense connection blocks (MDCB). The design of MDCB combines the strengths of both residual and dense connection strategies, while overcoming their limitations. To enable super-resolution for multiple factors, we propose a scale-recurrent framework which reutilizes the filters learnt for lower scale factors recursively for higher factors. This leads to improved performance and promotes parametric efficiency for higher factors. We train two versions of our network to enhance complementary image qualities using different loss configurations. We further employ our network for video super-resolution task, where our network learns to aggregate information from multiple frames and maintain spatio-temporal consistency. The proposed networks lead to qualitative and quantitative improvements over state-of-the-art techniques on image and video super-resolution benchmarks.
Image Restoration using Feature-guidance
Jan 01, 2022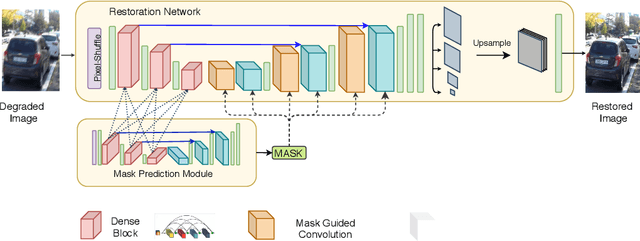



Image restoration is the task of recovering a clean image from a degraded version. In most cases, the degradation is spatially varying, and it requires the restoration network to both localize and restore the affected regions. In this paper, we present a new approach suitable for handling the image-specific and spatially-varying nature of degradation in images affected by practically occurring artifacts such as blur, rain-streaks. We decompose the restoration task into two stages of degradation localization and degraded region-guided restoration, unlike existing methods which directly learn a mapping between the degraded and clean images. Our premise is to use the auxiliary task of degradation mask prediction to guide the restoration process. We demonstrate that the model trained for this auxiliary task contains vital region knowledge, which can be exploited to guide the restoration network's training using attentive knowledge distillation technique. Further, we propose mask-guided convolution and global context aggregation module that focuses solely on restoring the degraded regions. The proposed approach's effectiveness is demonstrated by achieving significant improvement over strong baselines.
Adaptive Image Inpainting
Jan 01, 2022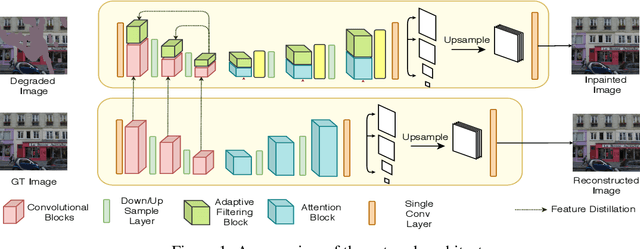

Image inpainting methods have shown significant improvements by using deep neural networks recently. However, many of these techniques often create distorted structures or blurry textures inconsistent with surrounding areas. The problem is rooted in the encoder layers' ineffectiveness in building a complete and faithful embedding of the missing regions. To address this problem, two-stage approaches deploy two separate networks for a coarse and fine estimate of the inpainted image. Some approaches utilize handcrafted features like edges or contours to guide the reconstruction process. These methods suffer from huge computational overheads owing to multiple generator networks, limited ability of handcrafted features, and sub-optimal utilization of the information present in the ground truth. Motivated by these observations, we propose a distillation based approach for inpainting, where we provide direct feature level supervision for the encoder layers in an adaptive manner. We deploy cross and self distillation techniques and discuss the need for a dedicated completion-block in encoder to achieve the distillation target. We conduct extensive evaluations on multiple datasets to validate our method.
Adaptive Single Image Deblurring
Jan 01, 2022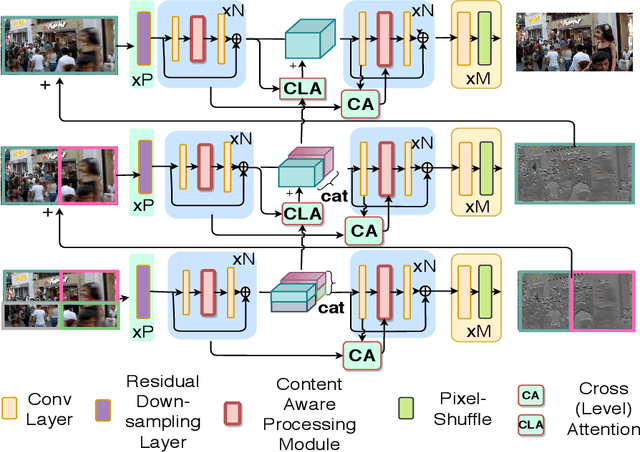
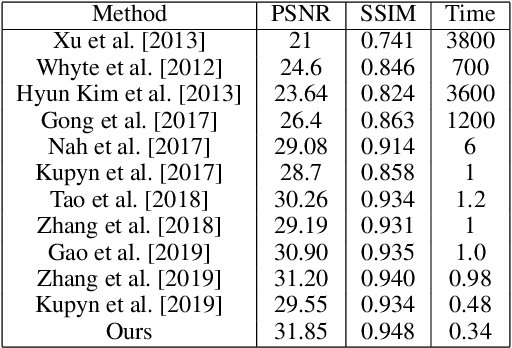

This paper tackles the problem of dynamic scene deblurring. Although end-to-end fully convolutional designs have recently advanced the state-of-the-art in non-uniform motion deblurring, their performance-complexity trade-off is still sub-optimal. Existing approaches achieve a large receptive field by a simple increment in the number of generic convolution layers, kernel-size, which comes with the burden of the increase in model size and inference speed. In this work, we propose an efficient pixel adaptive and feature attentive design for handling large blur variations within and across different images. We also propose an effective content-aware global-local filtering module that significantly improves the performance by considering not only the global dependencies of the pixel but also dynamically using the neighboring pixels. We use a patch hierarchical attentive architecture composed of the above module that implicitly discover the spatial variations in the blur present in the input image and in turn perform local and global modulation of intermediate features. Extensive qualitative and quantitative comparisons with prior art on deblurring benchmarks demonstrate the superiority of the proposed network.
Mitigating Channel-wise Noise for Single Image Super Resolution
Dec 14, 2021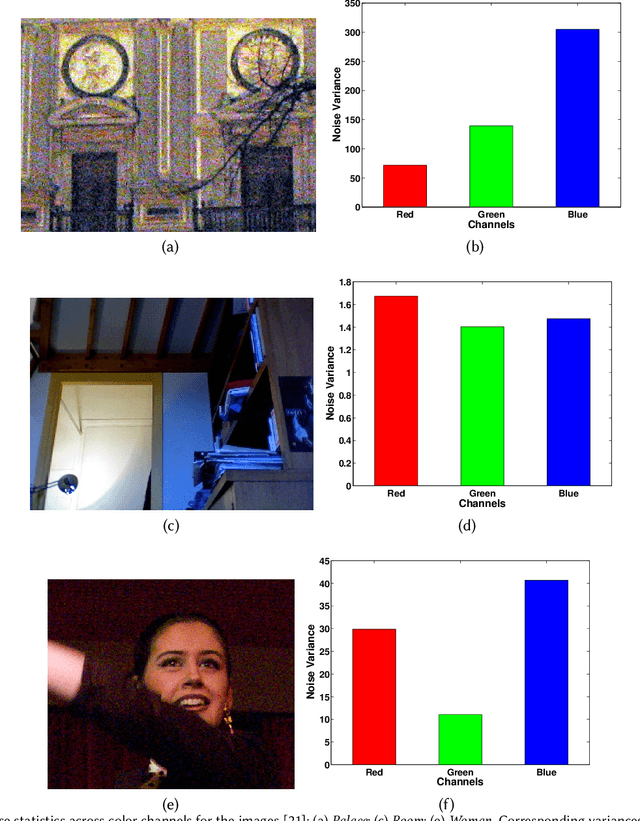
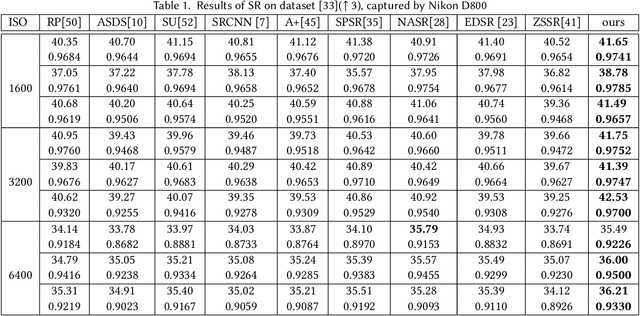


In practice, images can contain different amounts of noise for different color channels, which is not acknowledged by existing super-resolution approaches. In this paper, we propose to super-resolve noisy color images by considering the color channels jointly. Noise statistics are blindly estimated from the input low-resolution image and are used to assign different weights to different color channels in the data cost. Implicit low-rank structure of visual data is enforced via nuclear norm minimization in association with adaptive weights, which is added as a regularization term to the cost. Additionally, multi-scale details of the image are added to the model through another regularization term that involves projection onto PCA basis, which is constructed using similar patches extracted across different scales of the input image. The results demonstrate the super-resolving capability of the approach in real scenarios.