 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT is Robust! A Case Against Synonym-Based Adversarial Examples in Text Classification
Paper and Code
Sep 15, 2021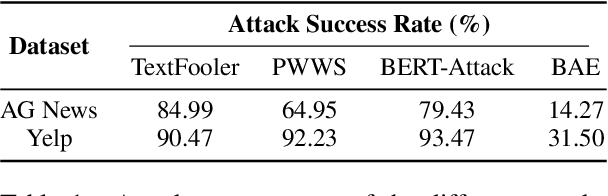
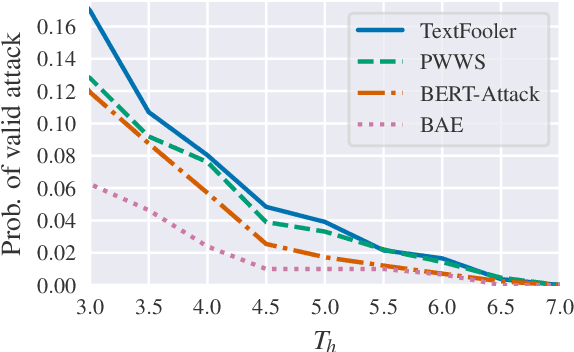

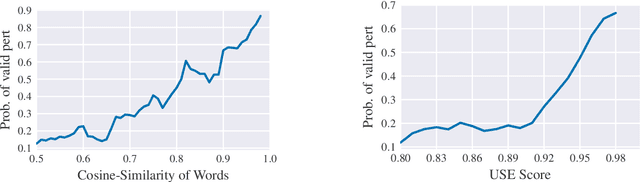
Deep Neural Networks have taken Natural Language Processing by storm. While this led to incredible improvements across many tasks, it also initiated a new research field, questioning the robustness of these neural networks by attacking them. In this paper, we investigate four word substitution-based attacks on BERT. We combine a human evaluation of individual word substitutions and a probabilistic analysis to show that between 96% and 99% of the analyzed attacks do not preserve semantics, indicating that their success is mainly based on feeding poor data to the model. To further confirm that, we introduce an efficient data augmentation procedure and show that many adversarial examples can be prevented by including data similar to the attacks during training. An additional post-processing step reduces the success rates of state-of-the-art attacks below 5%. Finally, by looking at more reasonable thresholds on constraints for word substitutions, we conclude that BERT is a lot more robust than research on attacks suggests.