 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Double Q-Learning for Continuous Reinforcement Learning
Sep 25, 2023

Majority of off-policy reinforcement learning algorithms use overestimation bias control techniques. Most of these techniques rooted in heuristics, primarily addressing the consequences of overestimation rather than its fundamental origins. In this work we present a novel approach to the bias correction, similar in spirit to Double Q-Learning. We propose using a policy in form of a mixture with two components. Each policy component is maximized and assessed by separate networks, which removes any basis for the overestimation bias. Our approach shows promising near-SOTA results on a small set of MuJoCo environments.
Automating Control of Overestimation Bias for Continuous Reinforcement Learning
Oct 26, 2021
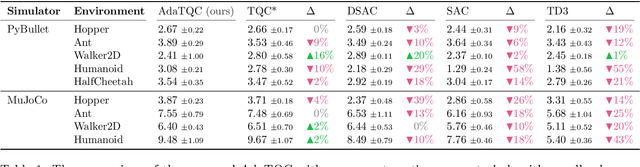

Bias correction techniques are used by most of the high-performing methods for off-policy reinforcement learning. However, these techniques rely on a pre-defined bias correction policy that is either not flexible enough or requires environment-specific tuning of hyperparameters. In this work, we present a simple data-driven approach for guiding bias correction. We demonstrate its effectiveness on the Truncated Quantile Critics -- a state-of-the-art continuous control algorithm. The proposed technique can adjust the bias correction across environments automatically. As a result, it eliminates the need for an extensive hyperparameter search, significantly reducing the actual number of interactions and computation.
Controlling Overestimation Bias with Truncated Mixture of Continuous Distributional Quantile Critics
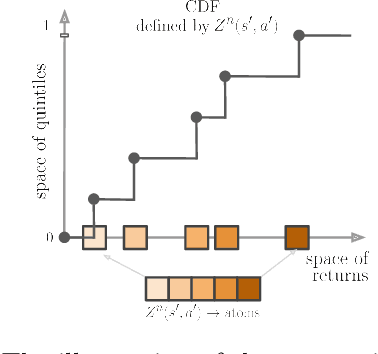
May 08, 2020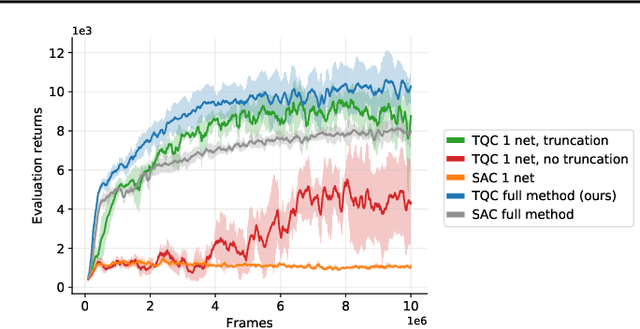

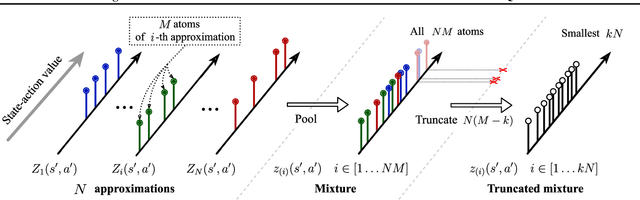
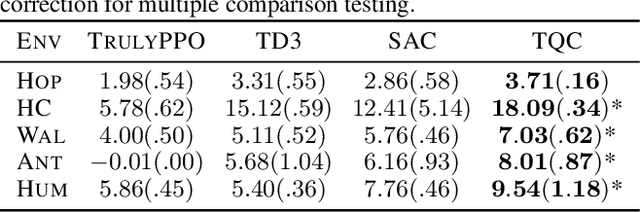
The overestimation bias is one of the major impediments to accurate off-policy learning. This paper investigates a novel way to alleviate the overestimation bias in a continuous control setting. Our method---Truncated Quantile Critics, TQC,---blends three ideas: distributional representation of a critic, truncation of critics prediction, and ensembling of multiple critics. Distributional representation and truncation allow for arbitrary granular overestimation control, while ensembling provides additional score improvements. TQC outperforms the current state of the art on all environments from the continuous control benchmark suite, demonstrating 25% improvement on the most challenging Humanoid environment.