Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Control of Overestimation Bias for Continuous Reinforcement Learning
Paper and Code
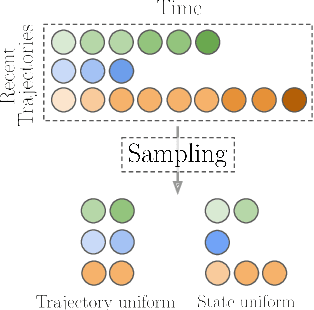
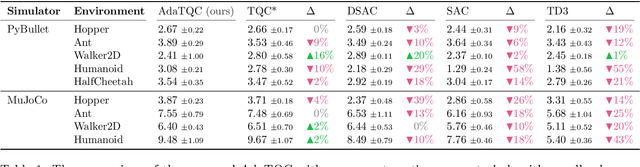
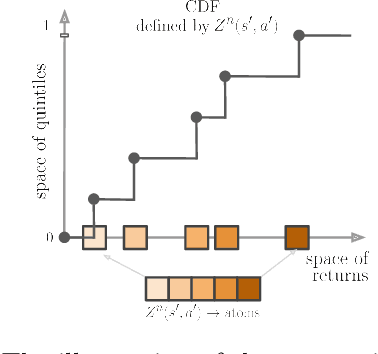

Bias correction techniques are used by most of the high-performing methods for off-policy reinforcement learning. However, these techniques rely on a pre-defined bias correction policy that is either not flexible enough or requires environment-specific tuning of hyperparameters. In this work, we present a simple data-driven approach for guiding bias correction. We demonstrate its effectiveness on the Truncated Quantile Critics -- a state-of-the-art continuous control algorithm. The proposed technique can adjust the bias correction across environments automatically. As a result, it eliminates the need for an extensive hyperparameter search, significantly reducing the actual number of interactions and computation.
View paper on