Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Incremental Learning for Deep Neural Networks
Paper and Code
Mar 27, 2018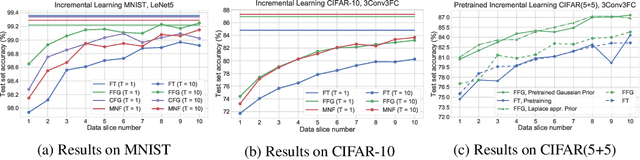
In industrial machine learning pipelines, data often arrive in parts. Particularly in the case of deep neural networks, it may be too expensive to train the model from scratch each time, so one would rather use a previously learned model and the new data to improve performance. However, deep neural networks are prone to getting stuck in a suboptimal solution when trained on only new data as compared to the full dataset. Our work focuses on a continuous learning setup where the task is always the same and new parts of data arrive sequentially. We apply a Bayesian approach to update the posterior approximation with each new piece of data and find this method to outperform the traditional approach in our experiments.
View paper on