 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming the Domain Gap in Neural Action Representations
Dec 23, 2021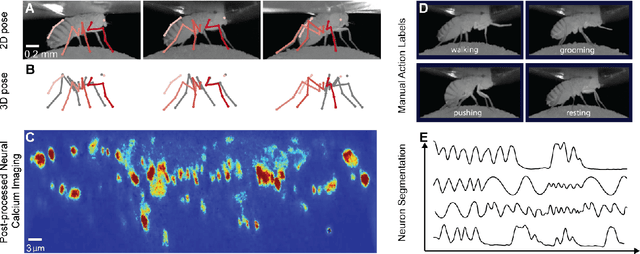
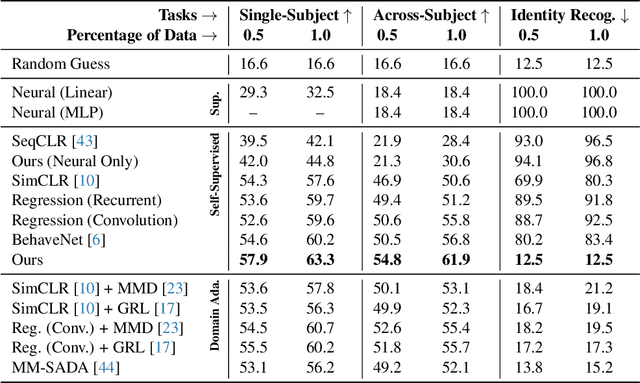
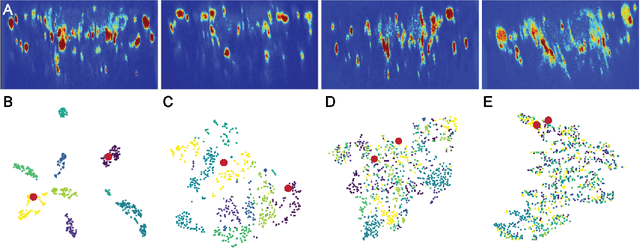
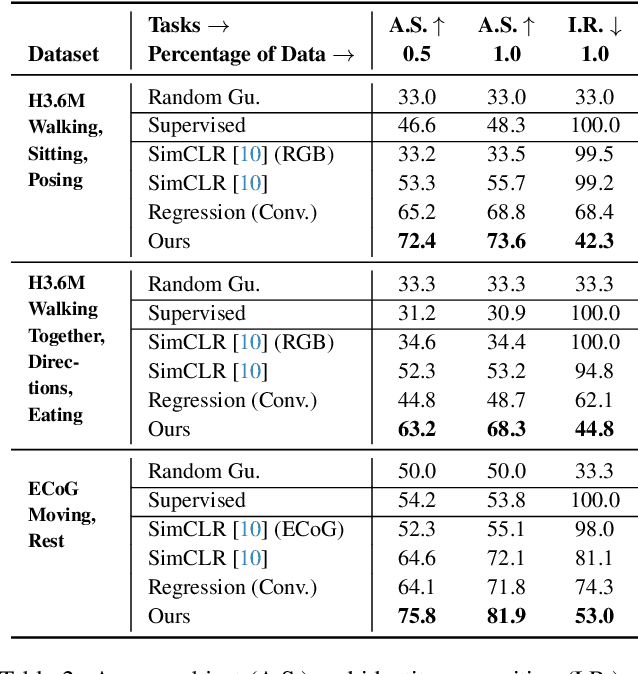
Relating animal behaviors to brain activity is a fundamental goal in neuroscience, with practical applications in building robust brain-machine interfaces. However, the domain gap between individuals is a major issue that prevents the training of general models that work on unlabeled subjects. Since 3D pose data can now be reliably extracted from multi-view video sequences without manual intervention, we propose to use it to guide the encoding of neural action representations together with a set of neural and behavioral augmentations exploiting the properties of microscopy imaging. To reduce the domain gap, during training, we swap neural and behavioral data across animals that seem to be performing similar actions. To demonstrate this, we test our methods on three very different multimodal datasets; one that features flies and their neural activity, one that contains human neural Electrocorticography (ECoG) data, and lastly the RGB video data of human activities from different viewpoints.
Overcoming the Domain Gap in Contrastive Learning of Neural Action Representations
Nov 29, 2021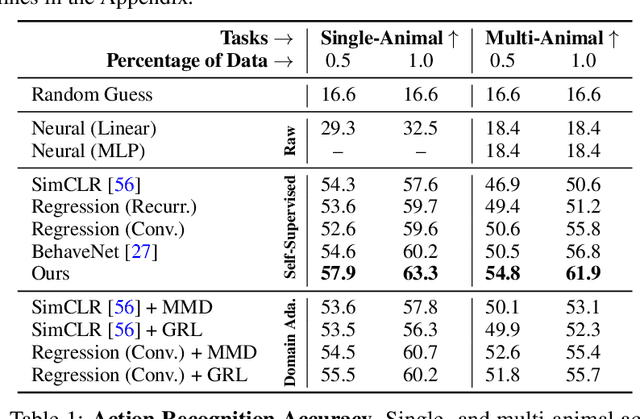
A fundamental goal in neuroscience is to understand the relationship between neural activity and behavior. For example, the ability to extract behavioral intentions from neural data, or neural decoding, is critical for developing effective brain machine interfaces. Although simple linear models have been applied to this challenge, they cannot identify important non-linear relationships. Thus, a self-supervised means of identifying non-linear relationships between neural dynamics and behavior, in order to compute neural representations, remains an important open problem. To address this challenge, we generated a new multimodal dataset consisting of the spontaneous behaviors generated by fruit flies, Drosophila melanogaster -- a popular model organism in neuroscience research. The dataset includes 3D markerless motion capture data from six camera views of the animal generating spontaneous actions, as well as synchronously acquired two-photon microscope images capturing the activity of descending neuron populations that are thought to drive actions. Standard contrastive learning and unsupervised domain adaptation techniques struggle to learn neural action representations (embeddings computed from the neural data describing action labels) due to large inter-animal differences in both neural and behavioral modalities. To overcome this deficiency, we developed simple yet effective augmentations that close the inter-animal domain gap, allowing us to extract behaviorally relevant, yet domain agnostic, information from neural data. This multimodal dataset and our new set of augmentations promise to accelerate the application of self-supervised learning methods in neuroscience.
Deformation-aware Unpaired Image Translation for Pose Estimation on Laboratory Animals
Jan 23, 2020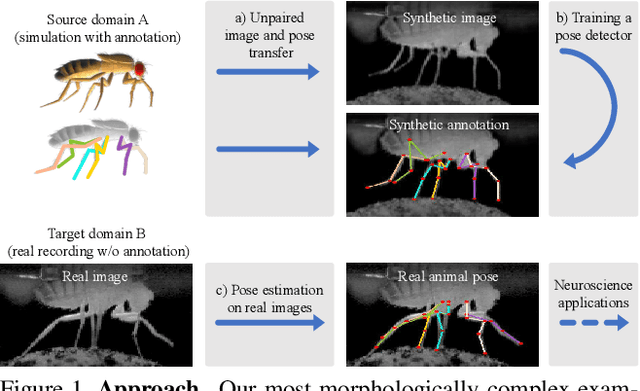
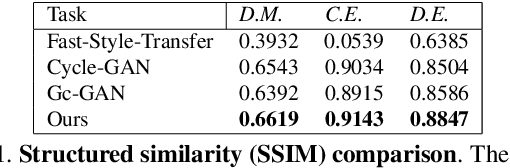

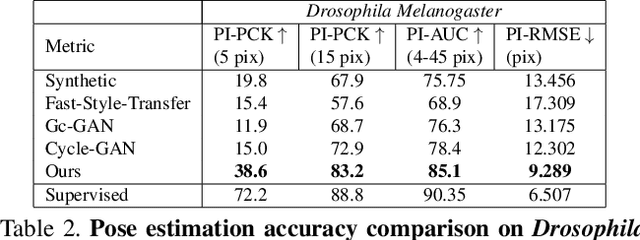
Our goal is to capture the pose of neuroscience model organisms, without using any manual supervision, to be able to study how neural circuits orchestrate behaviour. Human pose estimation attains remarkable accuracy when trained on real or simulated datasets consisting of millions of frames. However, for many applications simulated models are unrealistic and real training datasets with comprehensive annotations do not exist. We address this problem with a new sim2real domain transfer method. Our key contribution is the explicit and independent modeling of appearance, shape and poses in an unpaired image translation framework. Our model lets us train a pose estimator on the target domain by transferring readily available body keypoint locations from the source domain to generated target images. We compare our approach with existing domain transfer methods and demonstrate improved pose estimation accuracy on Drosophila melanogaster (fruit fly), Caenorhabditis elegans (worm) and Danio rerio (zebrafish), without requiring any manual annotation on the target domain and despite using simplistic off-the-shelf animal characters for simulation, or simple geometric shapes as models. Our new datasets, code, and trained models will be published to support future neuroscientific studies.
Gravity as a Reference for Estimating a Person's Height from Video
Oct 16, 2019
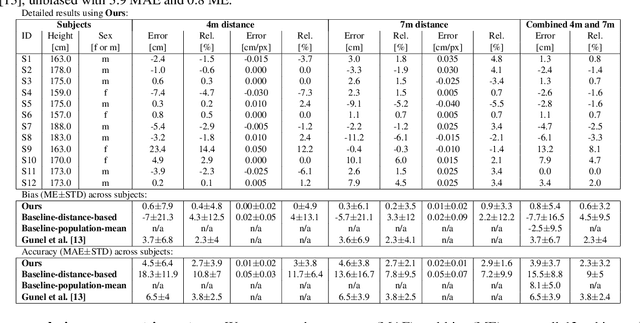


Estimating the metric height of a person from monocular imagery without additional assumptions is ill-posed. Existing solutions either require manual calibration of ground plane and camera geometry, special cameras, or reference objects of known size. We focus on motion cues and exploit gravity on earth as an omnipresent reference 'object' to translate acceleration, and subsequently height, measured in image-pixels to values in meters. We require videos of motion as input, where gravity is the only external force. This limitation is different to those of existing solutions that recover a person's height and, therefore, our method opens up new application fields. We show theoretically and empirically that a simple motion trajectory analysis suffices to translate from pixel measurements to the person's metric height, reaching a MAE of up to 3.9 cm on jumping motions, and that this works without camera and ground plane calibration.
What Face and Body Shapes Can Tell About Height
May 25, 2018



Recovering a person's height from a single image is important for virtual garment fitting, autonomous driving and surveillance, however, it is also very challenging due to the absence of absolute scale information. We tackle the rarely addressed case, where camera parameters and scene geometry is unknown. To nevertheless resolve the inherent scale ambiguity, we infer height from statistics that are intrinsic to human anatomy and can be estimated from images directly, such as articulated pose, bone length proportions, and facial features. Our contribution is twofold. First, we experiment with different machine learning models to capture the relation between image content and human height. Second, we show that performance is predominantly limited by dataset size and create a new dataset that is three magnitudes larger, by mining explicit height labels and propagating them to additional images through face recognition and assignment consistency. Our evaluation shows that monocular height estimation is possible with a MAE of 5.56cm.