 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Correlation Aggregation: on the Path to Better Graph Neural Networks
Paper and Code
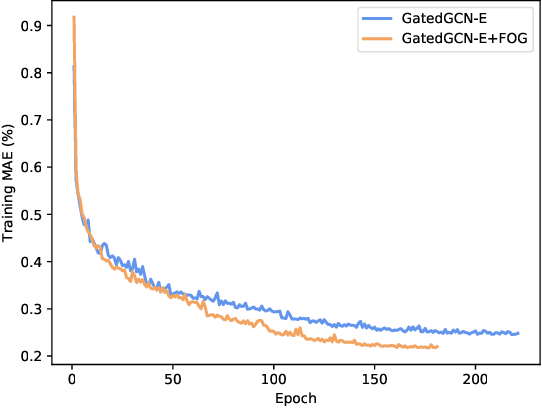

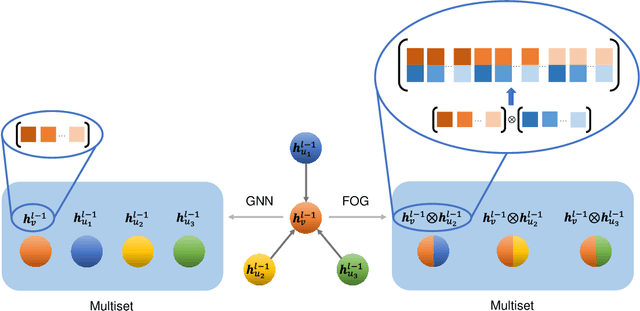
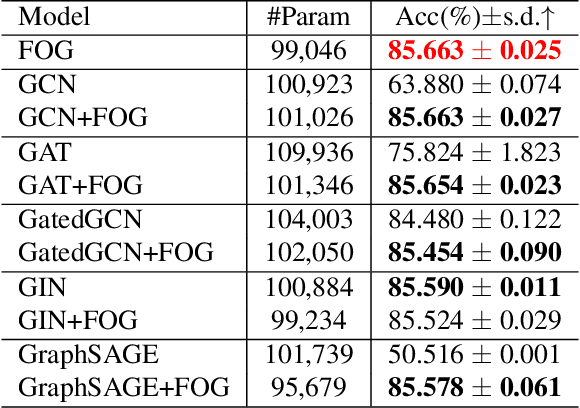
Prior to the introduction of Graph Neural Networks (GNNs), modeling and analyzing irregular data, particularly graphs, was thought to be the Achilles' heel of deep learning. The core concept of GNNs is to find a representation by recursively aggregating the representations of a central node and those of its neighbors. The core concept of GNNs is to find a representation by recursively aggregating the representations of a central node and those of its neighbor, and its success has been demonstrated by many GNNs' designs. However, most of them only focus on using the first-order information between a node and its neighbors. In this paper, we introduce a central node permutation variant function through a frustratingly simple and innocent-looking modification to the core operation of a GNN, namely the Feature cOrrelation aGgregation (FOG) module which learns the second-order information from feature correlation between a node and its neighbors in the pipeline. By adding FOG into existing variants of GNNs, we empirically verify this second-order information complements the features generated by original GNNs across a broad set of benchmarks. A tangible boost in performance of the model is observed where the model surpasses previous state-of-the-art results by a significant margin while employing fewer parameters. (e.g., 33.116% improvement on a real-world molecular dataset using graph convolutional networks).