 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Recurrent Attention Networks for Video Pedestrian Retrieval
Paper and Code
Oct 07, 2020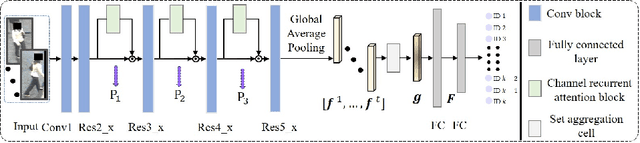
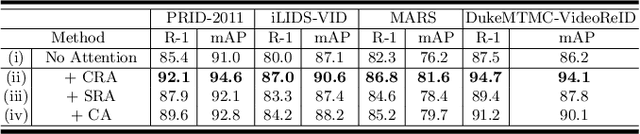

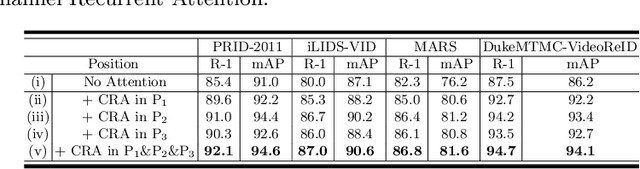
Full attention, which generates an attention value per element of the input feature maps, has been successfully demonstrated to be beneficial in visual tasks. In this work, we propose a fully attentional network, termed {\it channel recurrent attention network}, for the task of video pedestrian retrieval. The main attention unit, \textit{channel recurrent attention}, identifies attention maps at the frame level by jointly leveraging spatial and channel patterns via a recurrent neural network. This channel recurrent attention is designed to build a global receptive field by recurrently receiving and learning the spatial vectors. Then, a \textit{set aggregation} cell is employed to generate a compact video representation. Empirical experimental results demonstrate the superior performance of the proposed deep network, outperforming current state-of-the-art results across standard video person retrieval benchmarks, and a thorough ablation study shows the effectiveness of the proposed units.