 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Question Answering in Ophthalmology: A Progressive and Practical Perspective
Oct 22, 2024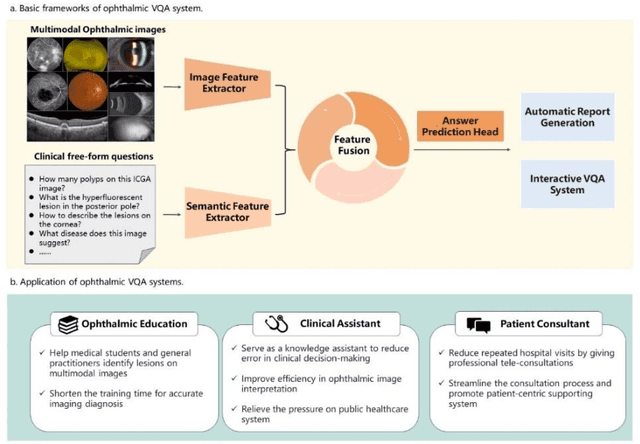
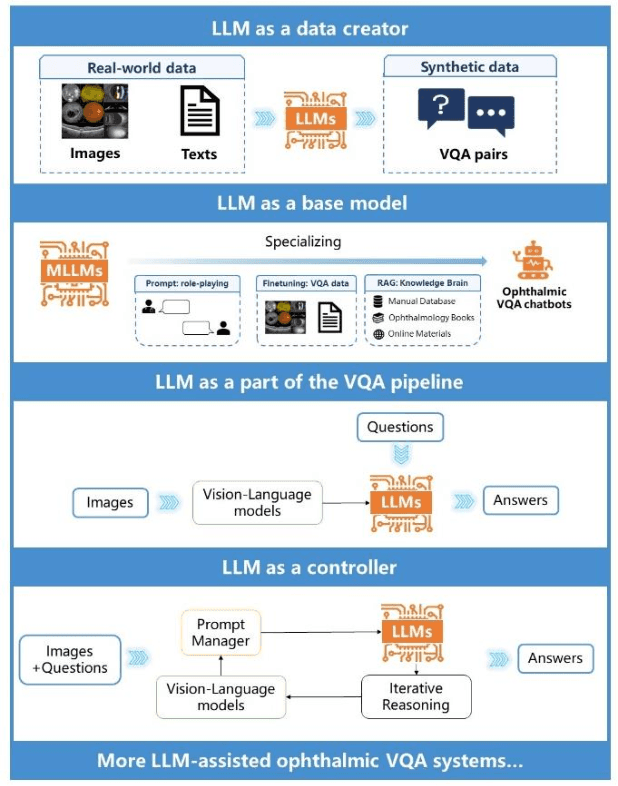
Accurate diagnosis of ophthalmic diseases relies heavily on the interpretation of multimodal ophthalmic images, a process often time-consuming and expertise-dependent. Visual Question Answering (VQA) presents a potential interdisciplinary solution by merging computer vision and natural language processing to comprehend and respond to queries about medical images. This review article explores the recent advancements and future prospects of VQA in ophthalmology from both theoretical and practical perspectives, aiming to provide eye care professionals with a deeper understanding and tools for leveraging the underlying models. Additionally, we discuss the promising trend of large language models (LLM) in enhancing various components of the VQA framework to adapt to multimodal ophthalmic tasks. Despite the promising outlook, ophthalmic VQA still faces several challenges, including the scarcity of annotated multimodal image datasets, the necessity of comprehensive and unified evaluation methods, and the obstacles to achieving effective real-world applications. This article highlights these challenges and clarifies future directions for advancing ophthalmic VQA with LLMs. The development of LLM-based ophthalmic VQA systems calls for collaborative efforts between medical professionals and AI experts to overcome existing obstacles and advance the diagnosis and care of eye diseases.
Choroidal Vessel Segmentation on Indocyanine Green Angiography Images via Human-in-the-Loop Labeling
Jun 04, 2024Human-in-the-loop (HITL) strategy has been recently introduced into the field of medical image processing. Indocyanine green angiography (ICGA) stands as a well-established examination for visualizing choroidal vasculature and detecting chorioretinal diseases. However, the intricate nature of choroidal vascular networks makes large-scale manual segmentation of ICGA images challenging. Thus, the study aims to develop a high-precision choroidal vessel segmentation model with limited labor using HITL framework. We utilized a multi-source ICGA dataset, including 55 degree view and ultra-widefield ICGA (UWF-ICGA) images for model development. The choroidal vessel network was pre-segmented by a pre-trained vessel segmentation model, and then manually modified by two ophthalmologists. Choroidal vascular diameter, density, complexity, tortuosity, and branching angle were automatically quantified based on the segmentation. We finally conducted four cycles of HITL. One hundred and fifty 55 degree view ICGA images were used for the first three cycles (50 images per cycle), and twenty UWF-ICGA images for the last cycle. The average time needed to manually correct a pre-segmented ICGA image per cycle reduced from 20 minutes to 1 minute. High segmentation accuracy has been achieved on both 55 degree view ICGA and UWF-ICGA images. Additionally, the multi-dimensional choroidal vascular parameters were significantly associated with various chorioretinal diseases. Our study not only demonstrated the feasibility of the HITL strategy in improving segmentation performance with reduced manual labeling, but also innovatively introduced several risk predictors for choroidal abnormalities.
Camera Adaptation for Fundus-Image-Based CVD Risk Estimation
Jun 18, 2022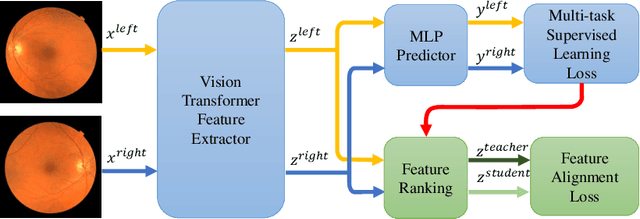
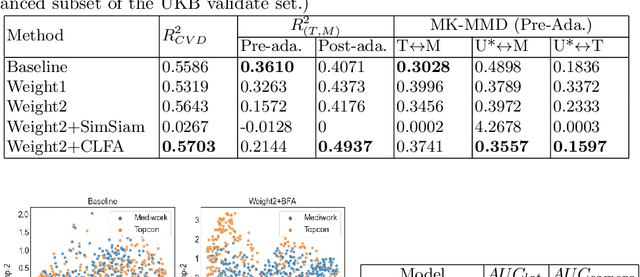
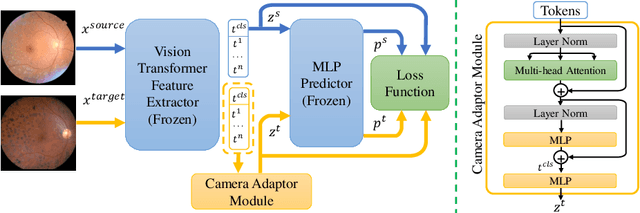

Recent studies have validated the association between cardiovascular disease (CVD) risk and retinal fundus images. Combining deep learning (DL) and portable fundus cameras will enable CVD risk estimation in various scenarios and improve healthcare democratization. However, there are still significant issues to be solved. One of the top priority issues is the different camera differences between the databases for research material and the samples in the production environment. Most high-quality retinography databases ready for research are collected from high-end fundus cameras, and there is a significant domain discrepancy between different cameras. To fully explore the domain discrepancy issue, we first collect a Fundus Camera Paired (FCP) dataset containing pair-wise fundus images captured by the high-end Topcon retinal camera and the low-end Mediwork portable fundus camera of the same patients. Then, we propose a cross-laterality feature alignment pre-training scheme and a self-attention camera adaptor module to improve the model robustness. The cross-laterality feature alignment training encourages the model to learn common knowledge from the same patient's left and right fundus images and improve model generalization. Meanwhile, the device adaptation module learns feature transformation from the target domain to the source domain. We conduct comprehensive experiments on both the UK Biobank database and our FCP data. The experimental results show that the CVD risk regression accuracy and the result consistency over two cameras are improved with our proposed method. The code is available here: \url{https://github.com/linzhlalala/CVD-risk-based-on-retinal-fundus-images}