 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera Adaptation for Fundus-Image-Based CVD Risk Estimation
Paper and Code
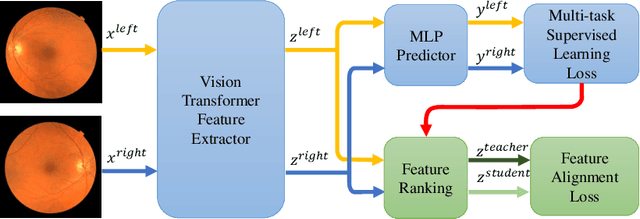
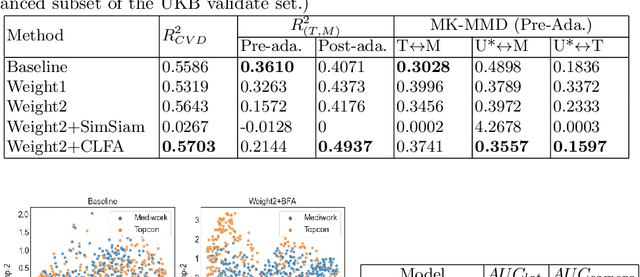
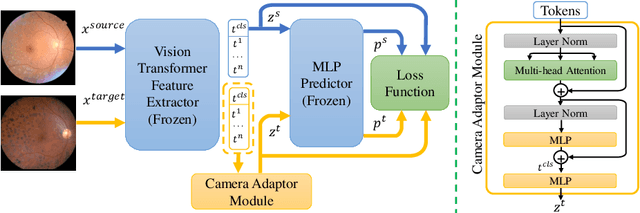

Recent studies have validated the association between cardiovascular disease (CVD) risk and retinal fundus images. Combining deep learning (DL) and portable fundus cameras will enable CVD risk estimation in various scenarios and improve healthcare democratization. However, there are still significant issues to be solved. One of the top priority issues is the different camera differences between the databases for research material and the samples in the production environment. Most high-quality retinography databases ready for research are collected from high-end fundus cameras, and there is a significant domain discrepancy between different cameras. To fully explore the domain discrepancy issue, we first collect a Fundus Camera Paired (FCP) dataset containing pair-wise fundus images captured by the high-end Topcon retinal camera and the low-end Mediwork portable fundus camera of the same patients. Then, we propose a cross-laterality feature alignment pre-training scheme and a self-attention camera adaptor module to improve the model robustness. The cross-laterality feature alignment training encourages the model to learn common knowledge from the same patient's left and right fundus images and improve model generalization. Meanwhile, the device adaptation module learns feature transformation from the target domain to the source domain. We conduct comprehensive experiments on both the UK Biobank database and our FCP data. The experimental results show that the CVD risk regression accuracy and the result consistency over two cameras are improved with our proposed method. The code is available here: \url{https://github.com/linzhlalala/CVD-risk-based-on-retinal-fundus-images}