 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTL: Transfer Learning Nonlinear Plasma Dynamic Transitions in Low Dimensional Embeddings via Deep Neural Networks
Apr 26, 2024Deep learning algorithms provide a new paradigm to study high-dimensional dynamical behaviors, such as those in fusion plasma systems. Development of novel model reduction methods, coupled with detection of abnormal modes with plasma physics, opens a unique opportunity for building efficient models to identify plasma instabilities for real-time control. Our Fusion Transfer Learning (FTL) model demonstrates success in reconstructing nonlinear kink mode structures by learning from a limited amount of nonlinear simulation data. The knowledge transfer process leverages a pre-trained neural encoder-decoder network, initially trained on linear simulations, to effectively capture nonlinear dynamics. The low-dimensional embeddings extract the coherent structures of interest, while preserving the inherent dynamics of the complex system. Experimental results highlight FTL's capacity to capture transitional behaviors and dynamical features in plasma dynamics -- a task often challenging for conventional methods. The model developed in this study is generalizable and can be extended broadly through transfer learning to address various magnetohydrodynamics (MHD) modes.
Camera Adaptation for Fundus-Image-Based CVD Risk Estimation
Jun 18, 2022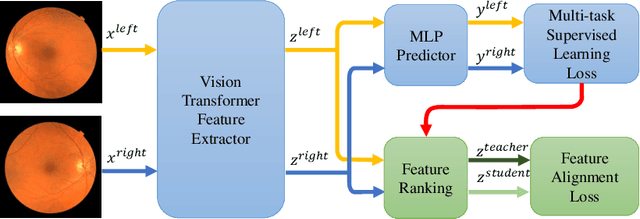
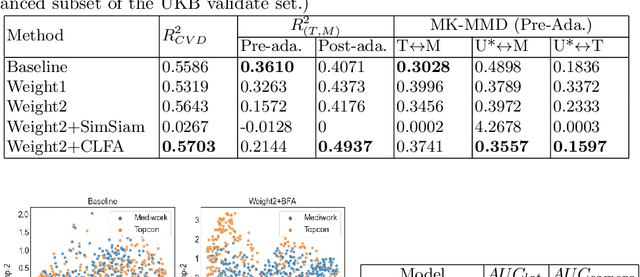
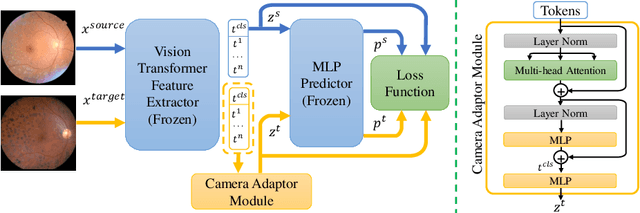

Recent studies have validated the association between cardiovascular disease (CVD) risk and retinal fundus images. Combining deep learning (DL) and portable fundus cameras will enable CVD risk estimation in various scenarios and improve healthcare democratization. However, there are still significant issues to be solved. One of the top priority issues is the different camera differences between the databases for research material and the samples in the production environment. Most high-quality retinography databases ready for research are collected from high-end fundus cameras, and there is a significant domain discrepancy between different cameras. To fully explore the domain discrepancy issue, we first collect a Fundus Camera Paired (FCP) dataset containing pair-wise fundus images captured by the high-end Topcon retinal camera and the low-end Mediwork portable fundus camera of the same patients. Then, we propose a cross-laterality feature alignment pre-training scheme and a self-attention camera adaptor module to improve the model robustness. The cross-laterality feature alignment training encourages the model to learn common knowledge from the same patient's left and right fundus images and improve model generalization. Meanwhile, the device adaptation module learns feature transformation from the target domain to the source domain. We conduct comprehensive experiments on both the UK Biobank database and our FCP data. The experimental results show that the CVD risk regression accuracy and the result consistency over two cameras are improved with our proposed method. The code is available here: \url{https://github.com/linzhlalala/CVD-risk-based-on-retinal-fundus-images}
Medical Visual Question Answering: A Survey
Nov 19, 2021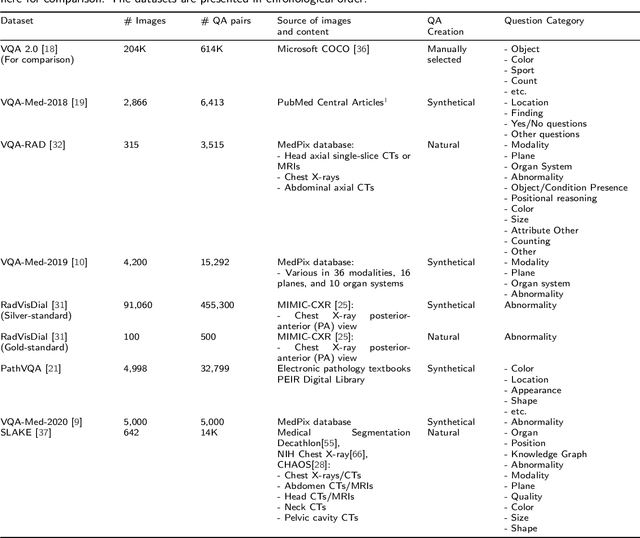
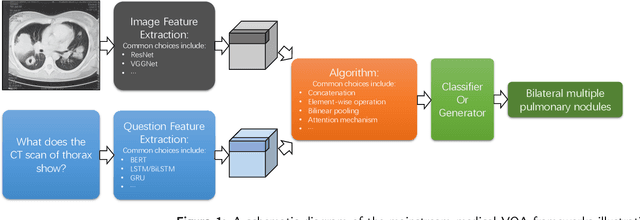
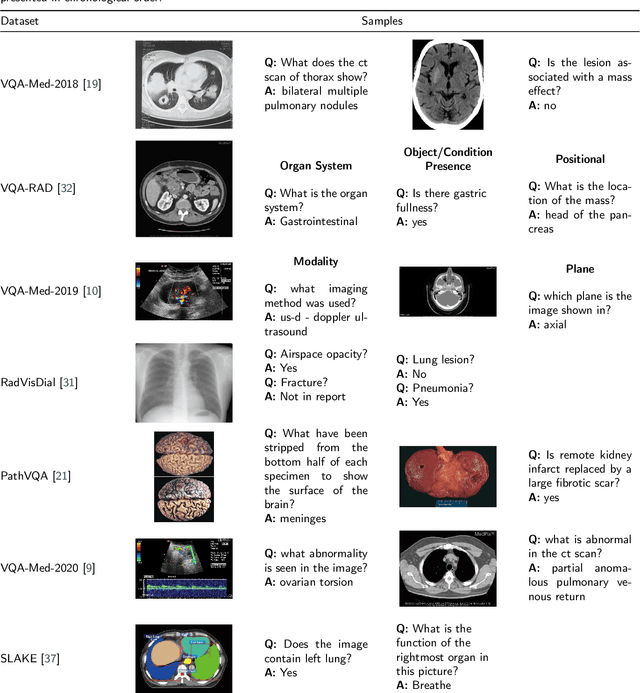
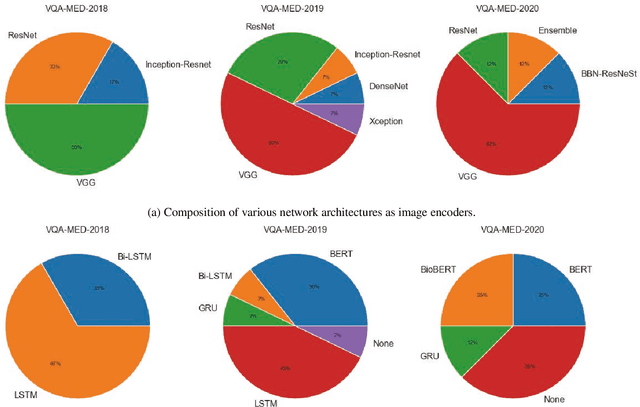
Medical Visual Question Answering (VQA) is a combination of medical artificial intelligence and popular VQA challenges. Given a medical image and a clinically relevant question in natural language, the medical VQA system is expected to predict a plausible and convincing answer. Although the general-domain VQA has been extensively studied, the medical VQA still needs specific investigation and exploration due to its task features. In the first part of this survey, we cover and discuss the publicly available medical VQA datasets up to date about the data source, data quantity, and task feature. In the second part, we review the approaches used in medical VQA tasks. In the last part, we analyze some medical-specific challenges for the field and discuss future research directions.