 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning through Creation: A Hash-Free Framework for On-the-Fly Category Discovery
Mar 17, 2026On-the-Fly Category Discovery (OCD) aims to recognize known classes while simultaneously discovering emerging novel categories during inference, using supervision only from known classes during offline training. Existing approaches rely either on fixed label supervision or on diffusion-based augmentations to enhance the backbone, yet none of them explicitly train the model to perform the discovery task required at test time. It is fundamentally unreasonable to expect a model optimized on limited labeled data to carry out a qualitatively different discovery objective during inference. This mismatch creates a clear optimization misalignment between the offline learning stage and the online discovery stage. In addition, prior methods often depend on hash-based encodings or severe feature compression, which further limits representational capacity. To address these issues, we propose Learning through Creation (LTC), a fully feature-based and hash-free framework that injects novel-category awareness directly into offline learning. At its core is a lightweight, online pseudo-unknown generator driven by kernel-energy minimization and entropy maximization (MKEE). Unlike previous methods that generate synthetic samples once before training, our generator evolves jointly with the model dynamics and synthesizes pseudo-novel instances on the fly at negligible cost. These samples are incorporated through a dual max-margin objective with adaptive thresholding, strengthening the model's ability to delineate and detect unknown regions through explicit creation. Extensive experiments across seven benchmarks show that LTC consistently outperforms prior work, achieving improvements ranging from 1.5 percent to 13.1 percent in all-class accuracy. The code is available at https://github.com/brandinzhang/LTC
TALON: Test-time Adaptive Learning for On-the-Fly Category Discovery
Mar 09, 2026On-the-fly category discovery (OCD) aims to recognize known categories while simultaneously discovering novel ones from an unlabeled online stream, using a model trained only on labeled data. Existing approaches freeze the feature extractor trained offline and employ a hash-based framework that quantizes features into binary codes as class prototypes. However, discovering novel categories with a fixed knowledge base is counterintuitive, as the learning potential of incoming data is entirely neglected. In addition, feature quantization introduces information loss, diminishes representational expressiveness, and amplifies intra-class variance. It often results in category explosion, where a single class is fragmented into multiple pseudo-classes. To overcome these limitations, we propose a test-time adaptation framework that enables learning through discovery. It incorporates two complementary strategies: a semantic-aware prototype update and a stable test-time encoder update. The former dynamically refines class prototypes to enhance classification, whereas the latter integrates new information directly into the parameter space. Together, these components allow the model to continuously expand its knowledge base with newly encountered samples. Furthermore, we introduce a margin-aware logit calibration in the offline stage to enlarge inter-class margins and improve intra-class compactness, thereby reserving embedding space for future class discovery. Experiments on standard OCD benchmarks demonstrate that our method substantially outperforms existing hash-based state-of-the-art approaches, yielding notable improvements in novel-class accuracy and effectively mitigating category explosion. The code is publicly available at \textcolor{blue}{https://github.com/ynanwu/TALON}.
RFM-Editing: Rectified Flow Matching for Text-guided Audio Editing
Sep 17, 2025Diffusion models have shown remarkable progress in text-to-audio generation. However, text-guided audio editing remains in its early stages. This task focuses on modifying the target content within an audio signal while preserving the rest, thus demanding precise localization and faithful editing according to the text prompt. Existing training-based and zero-shot methods that rely on full-caption or costly optimization often struggle with complex editing or lack practicality. In this work, we propose a novel end-to-end efficient rectified flow matching-based diffusion framework for audio editing, and construct a dataset featuring overlapping multi-event audio to support training and benchmarking in complex scenarios. Experiments show that our model achieves faithful semantic alignment without requiring auxiliary captions or masks, while maintaining competitive editing quality across metrics.
Teacher-Guided Pseudo Supervision and Cross-Modal Alignment for Audio-Visual Video Parsing
Sep 17, 2025Weakly-supervised audio-visual video parsing (AVVP) seeks to detect audible, visible, and audio-visual events without temporal annotations. Previous work has emphasized refining global predictions through contrastive or collaborative learning, but neglected stable segment-level supervision and class-aware cross-modal alignment. To address this, we propose two strategies: (1) an exponential moving average (EMA)-guided pseudo supervision framework that generates reliable segment-level masks via adaptive thresholds or top-k selection, offering stable temporal guidance beyond video-level labels; and (2) a class-aware cross-modal agreement (CMA) loss that aligns audio and visual embeddings at reliable segment-class pairs, ensuring consistency across modalities while preserving temporal structure. Evaluations on LLP and UnAV-100 datasets shows that our method achieves state-of-the-art (SOTA) performance across multiple metrics.
TEn-CATS: Text-Enriched Audio-Visual Video Parsing with Multi-Scale Category-Aware Temporal Graph
Sep 04, 2025Audio-Visual Video Parsing (AVVP) task aims to identify event categories and their occurrence times in a given video with weakly supervised labels. Existing methods typically fall into two categories: (i) designing enhanced architectures based on attention mechanism for better temporal modeling, and (ii) generating richer pseudo-labels to compensate for the absence of frame-level annotations. However, the first type methods treat noisy segment-level pseudo labels as reliable supervision and the second type methods let indiscriminate attention spread them across all frames, the initial errors are repeatedly amplified during training. To address this issue, we propose a method that combines the Bi-Directional Text Fusion (BiT) module and Category-Aware Temporal Graph (CATS) module. Specifically, we integrate the strengths and complementarity of the two previous research directions. We first perform semantic injection and dynamic calibration on audio and visual modality features through the BiT module, to locate and purify cleaner and richer semantic cues. Then, we leverage the CATS module for semantic propagation and connection to enable precise semantic information dissemination across time. Experimental results demonstrate that our proposed method achieves state-of-the-art (SOTA) performance in multiple key indicators on two benchmark datasets, LLP and UnAV-100.
When Trackers Date Fish: A Benchmark and Framework for Underwater Multiple Fish Tracking
Jul 08, 2025Multiple object tracking (MOT) technology has made significant progress in terrestrial applications, but underwater tracking scenarios remain underexplored despite their importance to marine ecology and aquaculture. We present Multiple Fish Tracking Dataset 2025 (MFT25), the first comprehensive dataset specifically designed for underwater multiple fish tracking, featuring 15 diverse video sequences with 408,578 meticulously annotated bounding boxes across 48,066 frames. Our dataset captures various underwater environments, fish species, and challenging conditions including occlusions, similar appearances, and erratic motion patterns. Additionally, we introduce Scale-aware and Unscented Tracker (SU-T), a specialized tracking framework featuring an Unscented Kalman Filter (UKF) optimized for non-linear fish swimming patterns and a novel Fish-Intersection-over-Union (FishIoU) matching that accounts for the unique morphological characteristics of aquatic species. Extensive experiments demonstrate that our SU-T baseline achieves state-of-the-art performance on MFT25, with 34.1 HOTA and 44.6 IDF1, while revealing fundamental differences between fish tracking and terrestrial object tracking scenarios. MFT25 establishes a robust foundation for advancing research in underwater tracking systems with important applications in marine biology, aquaculture monitoring, and ecological conservation. The dataset and codes are released at https://vranlee.github.io/SU-T/.
CM-PIE: Cross-modal perception for interactive-enhanced audio-visual video parsing
Oct 11, 2023Audio-visual video parsing is the task of categorizing a video at the segment level with weak labels, and predicting them as audible or visible events. Recent methods for this task leverage the attention mechanism to capture the semantic correlations among the whole video across the audio-visual modalities. However, these approaches have overlooked the importance of individual segments within a video and the relationship among them, and tend to rely on a single modality when learning features. In this paper, we propose a novel interactive-enhanced cross-modal perception method~(CM-PIE), which can learn fine-grained features by applying a segment-based attention module. Furthermore, a cross-modal aggregation block is introduced to jointly optimize the semantic representation of audio and visual signals by enhancing inter-modal interactions. The experimental results show that our model offers improved parsing performance on the Look, Listen, and Parse dataset compared to other methods.
A Review of Computer Vision Technologies for Fish Tracking
Oct 11, 2021
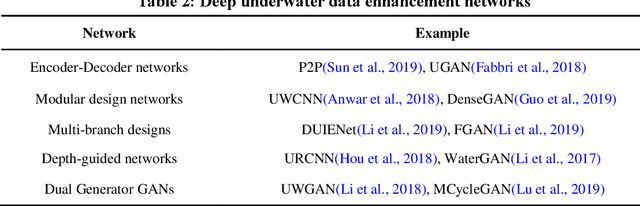
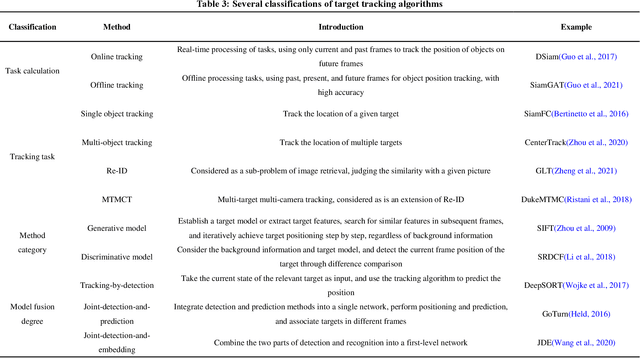
Fish tracking based on computer vision is a complex and challenging task in fishery production and ecological studies. Most of the applications of fish tracking use classic filtering algorithms, which lack in accuracy and efficiency. To solve this issue, deep learning methods utilized deep neural networks to extract the features, which achieve a good performance in the fish tracking. Some one-stage detection algorithms have gradually been adopted in this area for the real-time applications. The transfer learning to fish target is the current development direction. At present, fish tracking technology is not enough to cover actual application requirements. According to the literature data collected by us, there has not been any extensive review about vision-based fish tracking in the community. In this paper, we introduced the development and application prospects of fish tracking technology in last ten years. Firstly, we introduced the open source datasets of fish, and summarized the preprocessing technologies of underwater images. Secondly, we analyzed the detection and tracking algorithms for fish, and sorted out some transferable frontier tracking model. Thirdly, we listed the actual applications, metrics and bottlenecks of the fish tracking such as occlusion and multi-scale. Finally, we give the discussion for fish tracking datasets, solutions of the bottlenecks, and improvements. We expect that our work can help the fish tracking models to achieve higher accuracy and robustness.
SOTR: Segmenting Objects with Transformers
Aug 17, 2021

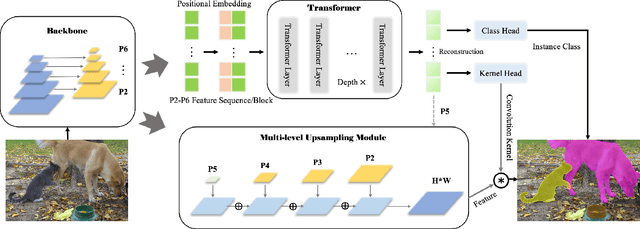
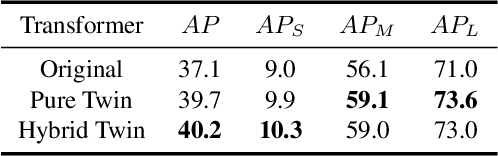
Most recent transformer-based models show impressive performance on vision tasks, even better than Convolution Neural Networks (CNN). In this work, we present a novel, flexible, and effective transformer-based model for high-quality instance segmentation. The proposed method, Segmenting Objects with TRansformers (SOTR), simplifies the segmentation pipeline, building on an alternative CNN backbone appended with two parallel subtasks: (1) predicting per-instance category via transformer and (2) dynamically generating segmentation mask with the multi-level upsampling module. SOTR can effectively extract lower-level feature representations and capture long-range context dependencies by Feature Pyramid Network (FPN) and twin transformer, respectively. Meanwhile, compared with the original transformer, the proposed twin transformer is time- and resource-efficient since only a row and a column attention are involved to encode pixels. Moreover, SOTR is easy to be incorporated with various CNN backbones and transformer model variants to make considerable improvements for the segmentation accuracy and training convergence. Extensive experiments show that our SOTR performs well on the MS COCO dataset and surpasses state-of-the-art instance segmentation approaches. We hope our simple but strong framework could serve as a preferment baseline for instance-level recognition. Our code is available at https://github.com/easton-cau/SOTR.
LeafMask: Towards Greater Accuracy on Leaf Segmentation
Aug 08, 2021
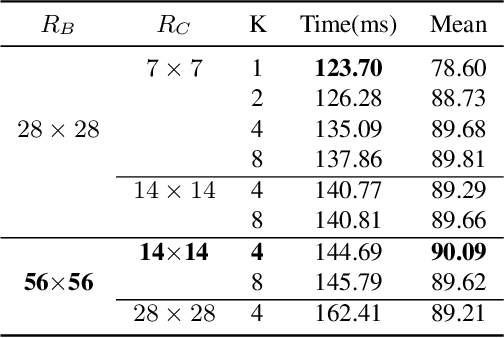
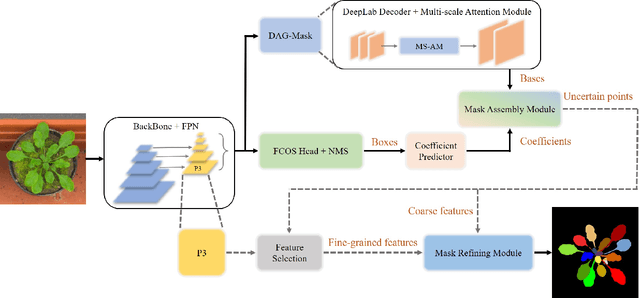
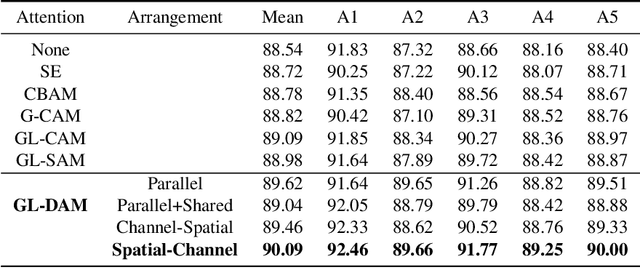
Leaf segmentation is the most direct and effective way for high-throughput plant phenotype data analysis and quantitative researches of complex traits. Currently, the primary goal of plant phenotyping is to raise the accuracy of the autonomous phenotypic measurement. In this work, we present the LeafMask neural network, a new end-to-end model to delineate each leaf region and count the number of leaves, with two main components: 1) the mask assembly module merging position-sensitive bases of each predicted box after non-maximum suppression (NMS) and corresponding coefficients to generate original masks; 2) the mask refining module elaborating leaf boundaries from the mask assembly module by the point selection strategy and predictor. In addition, we also design a novel and flexible multi-scale attention module for the dual attention-guided mask (DAG-Mask) branch to effectively enhance information expression and produce more accurate bases. Our main contribution is to generate the final improved masks by combining the mask assembly module with the mask refining module under the anchor-free instance segmentation paradigm. We validate our LeafMask through extensive experiments on Leaf Segmentation Challenge (LSC) dataset. Our proposed model achieves the 90.09% BestDice score outperforming other state-of-the-art approaches.