 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyncTrack: Rhythmic Stability and Synchronization in Multi-Track Music Generation
Mar 01, 2026Multi-track music generation has garnered significant research interest due to its precise mixing and remixing capabilities. However, existing models often overlook essential attributes such as rhythmic stability and synchronization, leading to a focus on differences between tracks rather than their inherent properties. In this paper, we introduce SyncTrack, a synchronous multi-track waveform music generation model designed to capture the unique characteristics of multi-track music. SyncTrack features a novel architecture that includes track-shared modules to establish a common rhythm across all tracks and track-specific modules to accommodate diverse timbres and pitch ranges. Each track-shared module employs two cross-track attention mechanisms to synchronize rhythmic information, while each track-specific module utilizes learnable instrument priors to better represent timbre and other unique features. Additionally, we enhance the evaluation of multi-track music quality by introducing rhythmic consistency through three novel metrics: Inner-track Rhythmic Stability (IRS), Cross-track Beat Synchronization (CBS), and Cross-track Beat Dispersion (CBD). Experiments demonstrate that SyncTrack significantly improves the multi-track music quality by enhancing rhythmic consistency.
Transfer learning for improved generalizability in causal physics-informed neural networks for beam simulations
Nov 01, 2023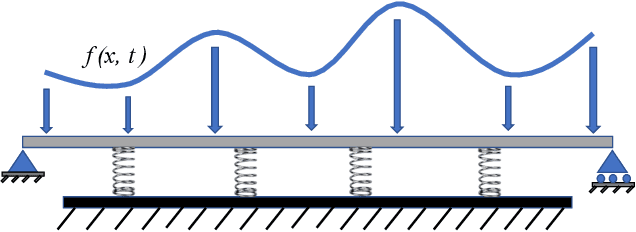

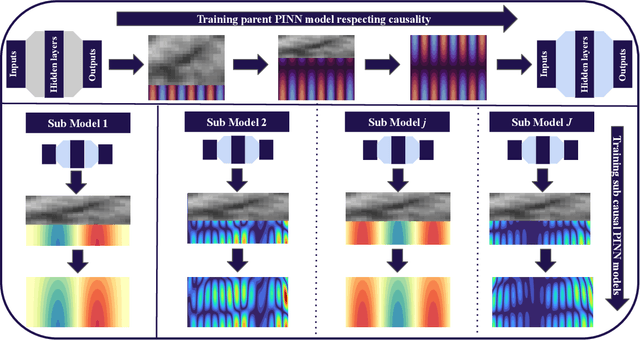

This paper introduces a novel methodology for simulating the dynamics of beams on elastic foundations. Specifically, Euler-Bernoulli and Timoshenko beam models on the Winkler foundation are simulated using a transfer learning approach within a causality-respecting physics-informed neural network (PINN) framework. Conventional PINNs encounter challenges in handling large space-time domains, even for problems with closed-form analytical solutions. A causality-respecting PINN loss function is employed to overcome this limitation, effectively capturing the underlying physics. However, it is observed that the causality-respecting PINN lacks generalizability. We propose using solutions to similar problems instead of training from scratch by employing transfer learning while adhering to causality to accelerate convergence and ensure accurate results across diverse scenarios. Numerical experiments on the Euler-Bernoulli beam highlight the efficacy of the proposed approach for various initial conditions, including those with noise in the initial data. Furthermore, the potential of the proposed method is demonstrated for the Timoshenko beam in an extended spatial and temporal domain. Several comparisons suggest that the proposed method accurately captures the inherent dynamics, outperforming the state-of-the-art physics-informed methods under standard $L^2$-norm metric and accelerating convergence.
Neural oscillators for generalization of physics-informed machine learning
Aug 17, 2023
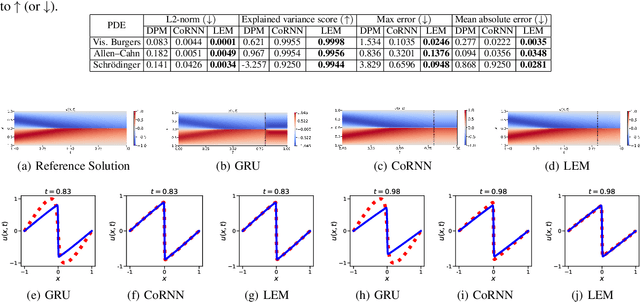


A primary challenge of physics-informed machine learning (PIML) is its generalization beyond the training domain, especially when dealing with complex physical problems represented by partial differential equations (PDEs). This paper aims to enhance the generalization capabilities of PIML, facilitating practical, real-world applications where accurate predictions in unexplored regions are crucial. We leverage the inherent causality and temporal sequential characteristics of PDE solutions to fuse PIML models with recurrent neural architectures based on systems of ordinary differential equations, referred to as neural oscillators. Through effectively capturing long-time dependencies and mitigating the exploding and vanishing gradient problem, neural oscillators foster improved generalization in PIML tasks. Extensive experimentation involving time-dependent nonlinear PDEs and biharmonic beam equations demonstrates the efficacy of the proposed approach. Incorporating neural oscillators outperforms existing state-of-the-art methods on benchmark problems across various metrics. Consequently, the proposed method improves the generalization capabilities of PIML, providing accurate solutions for extrapolation and prediction beyond the training data.
LMBot: Distilling Graph Knowledge into Language Model for Graph-less Deployment in Twitter Bot Detection
Jul 03, 2023As malicious actors employ increasingly advanced and widespread bots to disseminate misinformation and manipulate public opinion, the detection of Twitter bots has become a crucial task. Though graph-based Twitter bot detection methods achieve state-of-the-art performance, we find that their inference depends on the neighbor users multi-hop away from the targets, and fetching neighbors is time-consuming and may introduce bias. At the same time, we find that after finetuning on Twitter bot detection, pretrained language models achieve competitive performance and do not require a graph structure during deployment. Inspired by this finding, we propose a novel bot detection framework LMBot that distills the knowledge of graph neural networks (GNNs) into language models (LMs) for graph-less deployment in Twitter bot detection to combat the challenge of data dependency. Moreover, LMBot is compatible with graph-based and graph-less datasets. Specifically, we first represent each user as a textual sequence and feed them into the LM for domain adaptation. For graph-based datasets, the output of LMs provides input features for the GNN, enabling it to optimize for bot detection and distill knowledge back to the LM in an iterative, mutually enhancing process. Armed with the LM, we can perform graph-less inference, which resolves the graph data dependency and sampling bias issues. For datasets without graph structure, we simply replace the GNN with an MLP, which has also shown strong performance. Our experiments demonstrate that LMBot achieves state-of-the-art performance on four Twitter bot detection benchmarks. Extensive studies also show that LMBot is more robust, versatile, and efficient compared to graph-based Twitter bot detection methods.
Physics-informed machine learning for moving load problems
Apr 01, 2023This paper presents a new approach to simulate forward and inverse problems of moving loads using physics-informed machine learning (PIML). Physics-informed neural networks (PINNs) utilize the underlying physics of moving load problems and aim to predict the deflection of beams and the magnitude of the loads. The mathematical representation of the moving load considered in this work involves a Dirac delta function, to capture the effect of the load moving across the structure. Approximating the Dirac delta function with PINNs is challenging because of its instantaneous change of output at a single point, causing difficulty in the convergence of the loss function. We propose to approximate the Dirac delta function with a Gaussian function. The incorporated Gaussian function physical equations are used in the physics-informed neural architecture to simulate beam deflections and to predict the magnitude of the load. Numerical results show that PIML is an effective method for simulating the forward and inverse problems for the considered model of a moving load.
Physics-informed neural networks for solving forward and inverse problems in complex beam systems
Mar 02, 2023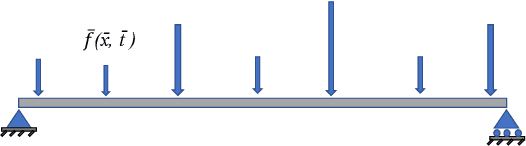
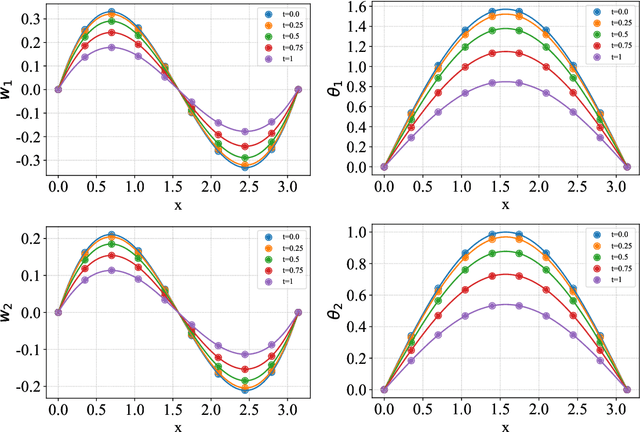
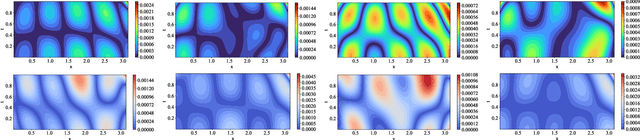
This paper proposes a new framework using physics-informed neural networks (PINNs) to simulate complex structural systems that consist of single and double beams based on Euler-Bernoulli and Timoshenko theory, where the double beams are connected with a Winkler foundation. In particular, forward and inverse problems for the Euler-Bernoulli and Timoshenko partial differential equations (PDEs) are solved using nondimensional equations with the physics-informed loss function. Higher-order complex beam PDEs are efficiently solved for forward problems to compute the transverse displacements and cross-sectional rotations with less than 1e-3 percent error. Furthermore, inverse problems are robustly solved to determine the unknown dimensionless model parameters and applied force in the entire space-time domain, even in the case of noisy data. The results suggest that PINNs are a promising strategy for solving problems in engineering structures and machines involving beam systems.
GraTO: Graph Neural Network Framework Tackling Over-smoothing with Neural Architecture Search
Aug 18, 2022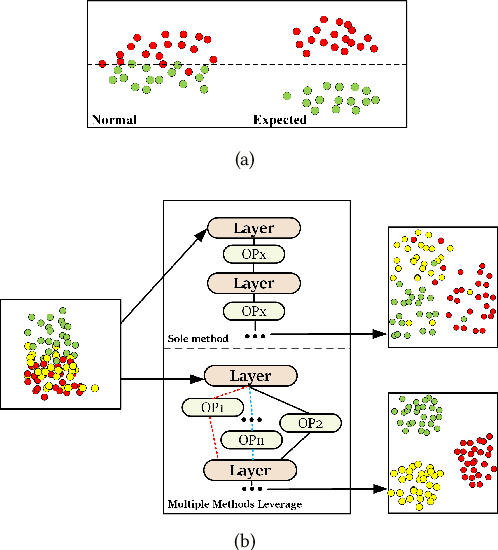

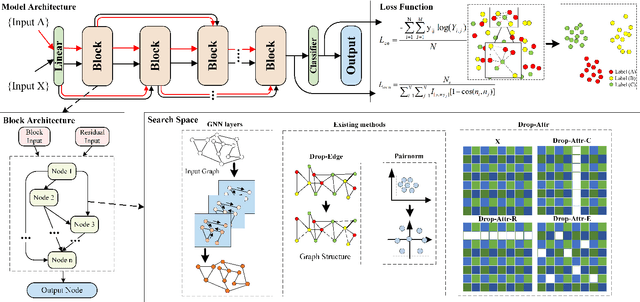

Current Graph Neural Networks (GNNs) suffer from the over-smoothing problem, which results in indistinguishable node representations and low model performance with more GNN layers. Many methods have been put forward to tackle this problem in recent years. However, existing tackling over-smoothing methods emphasize model performance and neglect the over-smoothness of node representations. Additional, different approaches are applied one at a time, while there lacks an overall framework to jointly leverage multiple solutions to the over-smoothing challenge. To solve these problems, we propose GraTO, a framework based on neural architecture search to automatically search for GNNs architecture. GraTO adopts a novel loss function to facilitate striking a balance between model performance and representation smoothness. In addition to existing methods, our search space also includes DropAttribute, a novel scheme for alleviating the over-smoothing challenge, to fully leverage diverse solutions. We conduct extensive experiments on six real-world datasets to evaluate GraTo, which demonstrates that GraTo outperforms baselines in the over-smoothing metrics and achieves competitive performance in accuracy. GraTO is especially effective and robust with increasing numbers of GNN layers. Further experiments bear out the quality of node representations learned with GraTO and the effectiveness of model architecture. We make cide of GraTo available at Github (\url{https://github.com/fxsxjtu/GraTO}).
TwiBot-22: Towards Graph-Based Twitter Bot Detection
Jun 12, 2022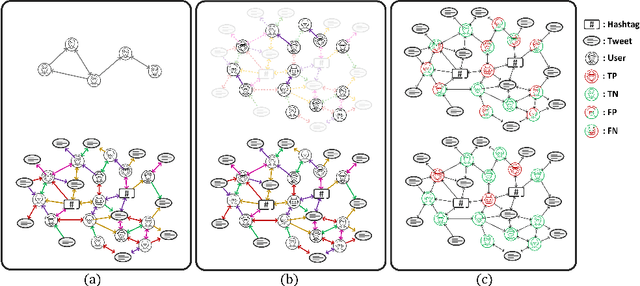
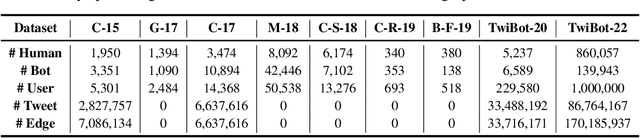
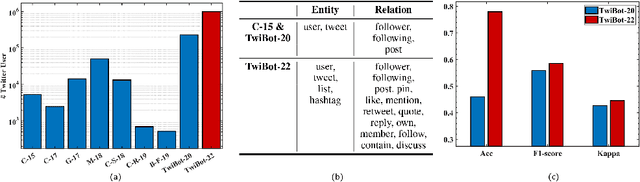
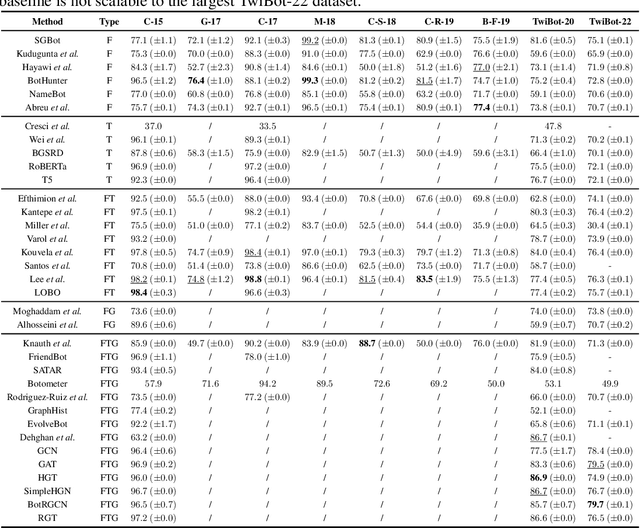
Twitter bot detection has become an increasingly important task to combat misinformation, facilitate social media moderation, and preserve the integrity of the online discourse. State-of-the-art bot detection methods generally leverage the graph structure of the Twitter network, and they exhibit promising performance when confronting novel Twitter bots that traditional methods fail to detect. However, very few of the existing Twitter bot detection datasets are graph-based, and even these few graph-based datasets suffer from limited dataset scale, incomplete graph structure, as well as low annotation quality. In fact, the lack of a large-scale graph-based Twitter bot detection benchmark that addresses these issues has seriously hindered the development and evaluation of novel graph-based bot detection approaches. In this paper, we propose TwiBot-22, a comprehensive graph-based Twitter bot detection benchmark that presents the largest dataset to date, provides diversified entities and relations on the Twitter network, and has considerably better annotation quality than existing datasets. In addition, we re-implement 35 representative Twitter bot detection baselines and evaluate them on 9 datasets, including TwiBot-22, to promote a fair comparison of model performance and a holistic understanding of research progress. To facilitate further research, we consolidate all implemented codes and datasets into the TwiBot-22 evaluation framework, where researchers could consistently evaluate new models and datasets. The TwiBot-22 Twitter bot detection benchmark and evaluation framework are publicly available at https://twibot22.github.io/