 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAERO: Autonomous Evolutionary Reasoning Optimization via Endogenous Dual-Loop Feedback
Feb 03, 2026Large Language Models (LLMs) have achieved significant success in complex reasoning but remain bottlenecked by reliance on expert-annotated data and external verifiers. While existing self-evolution paradigms aim to bypass these constraints, they often fail to identify the optimal learning zone and risk reinforcing collective hallucinations and incorrect priors through flawed internal feedback. To address these challenges, we propose \underline{A}utonomous \underline{E}volutionary \underline{R}easoning \underline{O}ptimization (AERO), an unsupervised framework that achieves autonomous reasoning evolution by internalizing self-questioning, answering, and criticism within a synergistic dual-loop system. Inspired by the \textit{Zone of Proximal Development (ZPD)} theory, AERO utilizes entropy-based positioning to target the ``solvability gap'' and employs Independent Counterfactual Correction for robust verification. Furthermore, we introduce a Staggered Training Strategy to synchronize capability growth across functional roles and prevent curriculum collapse. Extensive evaluations across nine benchmarks spanning three domains demonstrate that AERO achieves average performance improvements of 4.57\% on Qwen3-4B-Base and 5.10\% on Qwen3-8B-Base, outperforming competitive baselines. Code is available at https://github.com/mira-ai-lab/AERO.
$\textbf{AGT$^{AO}$}$: Robust and Stabilized LLM Unlearning via Adversarial Gating Training with Adaptive Orthogonality
Feb 02, 2026While Large Language Models (LLMs) have achieved remarkable capabilities, they unintentionally memorize sensitive data, posing critical privacy and security risks. Machine unlearning is pivotal for mitigating these risks, yet existing paradigms face a fundamental dilemma: aggressive unlearning often induces catastrophic forgetting that degrades model utility, whereas conservative strategies risk superficial forgetting, leaving models vulnerable to adversarial recovery. To address this trade-off, we propose $\textbf{AGT$^{AO}$}$ (Adversarial Gating Training with Adaptive Orthogonality), a unified framework designed to reconcile robust erasure with utility preservation. Specifically, our approach introduces $\textbf{Adaptive Orthogonality (AO)}$ to dynamically mitigate geometric gradient conflicts between forgetting and retention objectives, thereby minimizing unintended knowledge degradation. Concurrently, $\textbf{Adversarial Gating Training (AGT)}$ formulates unlearning as a latent-space min-max game, employing a curriculum-based gating mechanism to simulate and counter internal recovery attempts. Extensive experiments demonstrate that $\textbf{AGT$^{AO}$}$ achieves a superior trade-off between unlearning efficacy (KUR $\approx$ 0.01) and model utility (MMLU 58.30). Code is available at https://github.com/TiezMind/AGT-unlearning.
Deliberation on Priors: Trustworthy Reasoning of Large Language Models on Knowledge Graphs
May 21, 2025Knowledge graph-based retrieval-augmented generation seeks to mitigate hallucinations in Large Language Models (LLMs) caused by insufficient or outdated knowledge. However, existing methods often fail to fully exploit the prior knowledge embedded in knowledge graphs (KGs), particularly their structural information and explicit or implicit constraints. The former can enhance the faithfulness of LLMs' reasoning, while the latter can improve the reliability of response generation. Motivated by these, we propose a trustworthy reasoning framework, termed Deliberation over Priors (DP), which sufficiently utilizes the priors contained in KGs. Specifically, DP adopts a progressive knowledge distillation strategy that integrates structural priors into LLMs through a combination of supervised fine-tuning and Kahneman-Tversky optimization, thereby improving the faithfulness of relation path generation. Furthermore, our framework employs a reasoning-introspection strategy, which guides LLMs to perform refined reasoning verification based on extracted constraint priors, ensuring the reliability of response generation. Extensive experiments on three benchmark datasets demonstrate that DP achieves new state-of-the-art performance, especially a Hit@1 improvement of 13% on the ComplexWebQuestions dataset, and generates highly trustworthy responses. We also conduct various analyses to verify its flexibility and practicality. The code is available at https://github.com/reml-group/Deliberation-on-Priors.
FortisAVQA and MAVEN: a Benchmark Dataset and Debiasing Framework for Robust Multimodal Reasoning
Apr 02, 2025
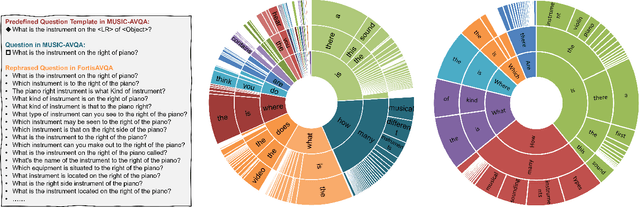
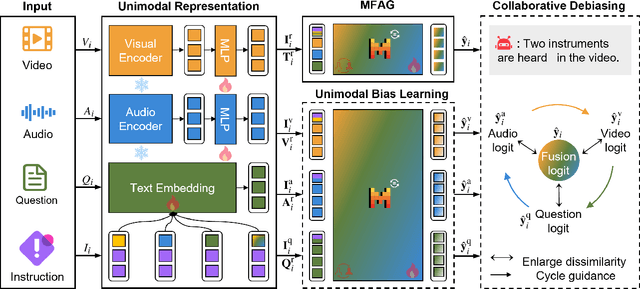
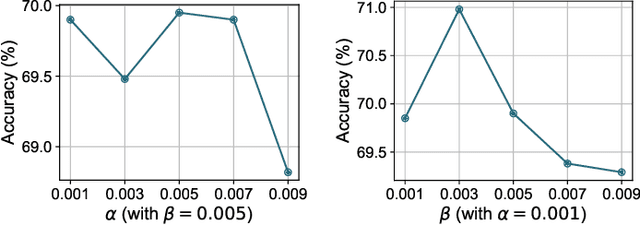
Audio-Visual Question Answering (AVQA) is a challenging multimodal reasoning task requiring intelligent systems to answer natural language queries based on paired audio-video inputs accurately. However, existing AVQA approaches often suffer from overfitting to dataset biases, leading to poor robustness. Moreover, current datasets may not effectively diagnose these methods. To address these challenges, we first introduce a novel dataset, FortisAVQA, constructed in two stages: (1) rephrasing questions in the test split of the public MUSIC-AVQA dataset and (2) introducing distribution shifts across questions. The first stage expands the test space with greater diversity, while the second enables a refined robustness evaluation across rare, frequent, and overall question distributions. Second, we introduce a robust Multimodal Audio-Visual Epistemic Network (MAVEN) that leverages a multifaceted cycle collaborative debiasing strategy to mitigate bias learning. Experimental results demonstrate that our architecture achieves state-of-the-art performance on FortisAVQA, with a notable improvement of 7.81\%. Extensive ablation studies on both datasets validate the effectiveness of our debiasing components. Additionally, our evaluation reveals the limited robustness of existing multimodal QA methods. We also verify the plug-and-play capability of our strategy by integrating it with various baseline models across both datasets. Our dataset and code are available at https://github.com/reml-group/fortisavqa.
Debate on Graph: a Flexible and Reliable Reasoning Framework for Large Language Models
Sep 05, 2024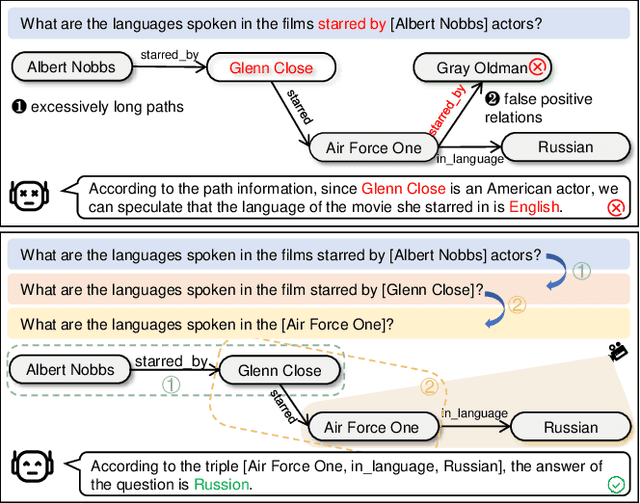
Large Language Models (LLMs) may suffer from hallucinations in real-world applications due to the lack of relevant knowledge. In contrast, knowledge graphs encompass extensive, multi-relational structures that store a vast array of symbolic facts. Consequently, integrating LLMs with knowledge graphs has been extensively explored, with Knowledge Graph Question Answering (KGQA) serving as a critical touchstone for the integration. This task requires LLMs to answer natural language questions by retrieving relevant triples from knowledge graphs. However, existing methods face two significant challenges: \textit{excessively long reasoning paths distracting from the answer generation}, and \textit{false-positive relations hindering the path refinement}. In this paper, we propose an iterative interactive KGQA framework that leverages the interactive learning capabilities of LLMs to perform reasoning and Debating over Graphs (DoG). Specifically, DoG employs a subgraph-focusing mechanism, allowing LLMs to perform answer trying after each reasoning step, thereby mitigating the impact of lengthy reasoning paths. On the other hand, DoG utilizes a multi-role debate team to gradually simplify complex questions, reducing the influence of false-positive relations. This debate mechanism ensures the reliability of the reasoning process. Experimental results on five public datasets demonstrate the effectiveness and superiority of our architecture. Notably, DoG outperforms the state-of-the-art method ToG by 23.7\% and 9.1\% in accuracy on WebQuestions and GrailQA, respectively. Furthermore, the integration experiments with various LLMs on the mentioned datasets highlight the flexibility of DoG. Code is available at \url{https://github.com/reml-group/DoG}.
Adaptive Tuning of Robotic Polishing Skills based on Force Feedback Model
Oct 23, 2023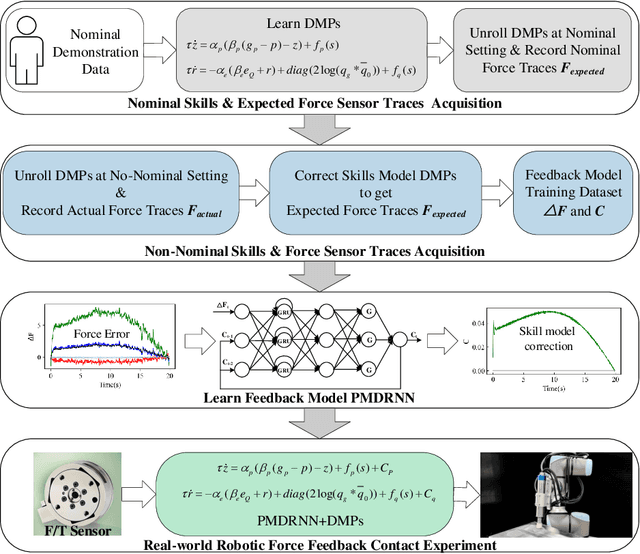
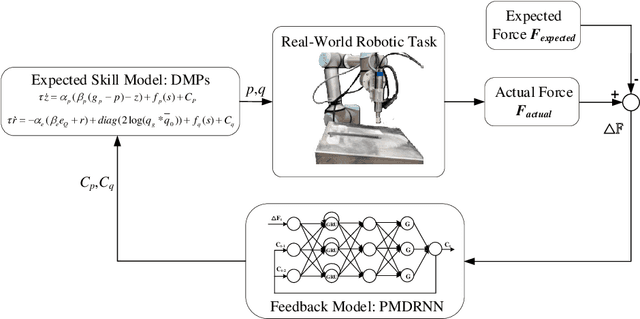
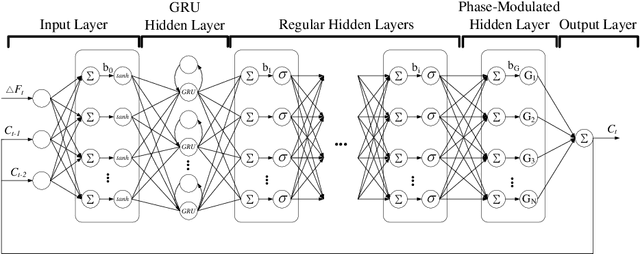

Acquiring human skills offers an efficient approach to tackle complex task planning challenges. When performing a learned skill model for a continuous contact task, such as robot polishing in an uncertain environment, the robot needs to be able to adaptively modify the skill model to suit the environment and perform the desired task. The environmental perturbation of the polishing task is mainly reflected in the variation of contact force. Therefore, adjusting the task skill model by providing feedback on the contact force deviation is an effective way to meet the task requirements. In this study, a phase-modulated diagonal recurrent neural network (PMDRNN) is proposed for force feedback model learning in the robotic polishing task. The contact between the tool and the workpiece in the polishing task can be considered a dynamic system. In comparison to the existing feedforward neural network phase-modulated neural network (PMNN), PMDRNN combines the diagonal recurrent network structure with the phase-modulated neural network layer to improve the learning performance of the feedback model for dynamic systems. Specifically, data from real-world robot polishing experiments are used to learn the feedback model. PMDRNN demonstrates a significant reduction in the training error of the feedback model when compared to PMNN. Building upon this, the combination of PMDRNN and dynamic movement primitives (DMPs) can be used for real-time adjustment of skills for polishing tasks and effectively improve the robustness of the task skill model. Finally, real-world robotic polishing experiments are conducted to demonstrate the effectiveness of the approach.