 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Identity Technologies for LLMs: Fingerprinting and Watermarking across Datasets, Models, and Generated Content
May 28, 2026This paper presents a survey and taxonomy of LLM fingerprinting and watermarking for identity, ownership verification, provenance, and generated-content attribution. Large language models (LLMs) require substantial investments in data, computation, and expertise, and are increasingly deployed in high-stakes settings, making it critical to protect LLM-related assets and trace their origins. Existing work has rapidly expanded across dataset provenance, model ownership, and generated-content detection, but the field remains fragmented: fingerprinting and watermarking are often used inconsistently, and methods are typically studied within isolated asset-specific settings. To address this gap, we introduce implicit identity as a unifying abstraction for verifiable but not directly observable identity signals in LLM systems. We distinguish fingerprinting as non-intrusive identity derived from intrinsic characteristics, and watermarking as intrusive identity deliberately embedded into data, models, or generated content. We then propose a lifecycle-based taxonomy that organises techniques across datasets, models, and generated content, and further separates them by verification semantics: similarity-based attribution and keyed verification. Finally, we establish an evaluation framework centred on identifiability, robustness, and deployability, summarising representative metrics under realistic access and transformation regimes. By unifying terminology, lifecycle stages, and evaluation objectives, this survey provides a structured foundation for studying LLM identity technologies and for developing more reliable mechanisms for asset protection and provenance.
Understanding Generalization through Decision Pattern Shift
May 13, 2026Understanding why deep neural networks (DNNs) fail to generalize to unseen samples remains a long-standing challenge. Existing studies mainly examine changes in externally observable factors such as data, representations, or outputs, yet offer limited insight into how a model's internal decision mechanism evolves from training to test. To address this gap, we introduce Decision Pattern Shift (DPS), a new perspective that defines generalization through the stability of internal decision patterns and quantifies failure as their deviation from those learned during training. Specifically, we represent each sample's decision pattern as a GradCAM-based channel-contribution vector, which captures how feature channels collectively support a prediction, and we propose the DPS metric to measure its discrepancy from the class-average pattern. Empirical analyses across multiple datasets and architectures show that, (i) decision patterns form a highly structured, class-consistent space with strong intra-class cohesion and low inter-class confusion, enabling direct analysis of a model's decision logic; (ii) the DPS magnitude correlates linearly with the generalization gap (nearly all Pearson r > 0.8), revealing generalization as a systematic drift in the model's internal decision mechanism; (iii) the DPS spectrum organizes diverse generalization degradation scenarios (covering ideal generalization, in-distribution degradation, domain shift, out-of-distribution, and shortcut learning) into a continuous trajectory, providing a unified explanation of their failure modes. These findings open up new possibilities for early generalization-risk detection, failure-mode diagnosis, and channel-level defect localization.
The Interaction Bottleneck of Deep Neural Networks: Discovery, Proof, and Modulation
Dec 21, 2025Understanding what kinds of cooperative structures deep neural networks (DNNs) can represent remains a fundamental yet insufficiently understood problem. In this work, we treat interactions as the fundamental units of such structure and investigate a largely unexplored question: how DNNs encode interactions under different levels of contextual complexity, and how these microscopic interaction patterns shape macroscopic representation capacity. To quantify this complexity, we use multi-order interactions [57], where each order reflects the amount of contextual information required to evaluate the joint interaction utility of a variable pair. This formulation enables a stratified analysis of cooperative patterns learned by DNNs. Building on this formulation, we develop a comprehensive study of interaction structure in DNNs. (i) We empirically discover a universal interaction bottleneck: across architectures and tasks, DNNs easily learn low-order and high-order interactions but consistently under-represent mid-order ones. (ii) We theoretically explain this bottleneck by proving that mid-order interactions incur the highest contextual variability, yielding large gradient variance and making them intrinsically difficult to learn. (iii) We further modulate the bottleneck by introducing losses that steer models toward emphasizing interactions of selected orders. Finally, we connect microscopic interaction structures with macroscopic representational behavior: low-order-emphasized models exhibit stronger generalization and robustness, whereas high-order-emphasized models demonstrate greater structural modeling and fitting capability. Together, these results uncover an inherent representational bias in modern DNNs and establish interaction order as a powerful lens for interpreting and guiding deep representations.
Attribution Explanations for Deep Neural Networks: A Theoretical Perspective
Aug 11, 2025Attribution explanation is a typical approach for explaining deep neural networks (DNNs), inferring an importance or contribution score for each input variable to the final output. In recent years, numerous attribution methods have been developed to explain DNNs. However, a persistent concern remains unresolved, i.e., whether and which attribution methods faithfully reflect the actual contribution of input variables to the decision-making process. The faithfulness issue undermines the reliability and practical utility of attribution explanations. We argue that these concerns stem from three core challenges. First, difficulties arise in comparing attribution methods due to their unstructured heterogeneity, differences in heuristics, formulations, and implementations that lack a unified organization. Second, most methods lack solid theoretical underpinnings, with their rationales remaining absent, ambiguous, or unverified. Third, empirically evaluating faithfulness is challenging without ground truth. Recent theoretical advances provide a promising way to tackle these challenges, attracting increasing attention. We summarize these developments, with emphasis on three key directions: (i) Theoretical unification, which uncovers commonalities and differences among methods, enabling systematic comparisons; (ii) Theoretical rationale, clarifying the foundations of existing methods; (iii) Theoretical evaluation, rigorously proving whether methods satisfy faithfulness principles. Beyond a comprehensive review, we provide insights into how these studies help deepen theoretical understanding, inform method selection, and inspire new attribution methods. We conclude with a discussion of promising open problems for further work.
Deliberation on Priors: Trustworthy Reasoning of Large Language Models on Knowledge Graphs
May 21, 2025Knowledge graph-based retrieval-augmented generation seeks to mitigate hallucinations in Large Language Models (LLMs) caused by insufficient or outdated knowledge. However, existing methods often fail to fully exploit the prior knowledge embedded in knowledge graphs (KGs), particularly their structural information and explicit or implicit constraints. The former can enhance the faithfulness of LLMs' reasoning, while the latter can improve the reliability of response generation. Motivated by these, we propose a trustworthy reasoning framework, termed Deliberation over Priors (DP), which sufficiently utilizes the priors contained in KGs. Specifically, DP adopts a progressive knowledge distillation strategy that integrates structural priors into LLMs through a combination of supervised fine-tuning and Kahneman-Tversky optimization, thereby improving the faithfulness of relation path generation. Furthermore, our framework employs a reasoning-introspection strategy, which guides LLMs to perform refined reasoning verification based on extracted constraint priors, ensuring the reliability of response generation. Extensive experiments on three benchmark datasets demonstrate that DP achieves new state-of-the-art performance, especially a Hit@1 improvement of 13% on the ComplexWebQuestions dataset, and generates highly trustworthy responses. We also conduct various analyses to verify its flexibility and practicality. The code is available at https://github.com/reml-group/Deliberation-on-Priors.
Debate on Graph: a Flexible and Reliable Reasoning Framework for Large Language Models
Sep 05, 2024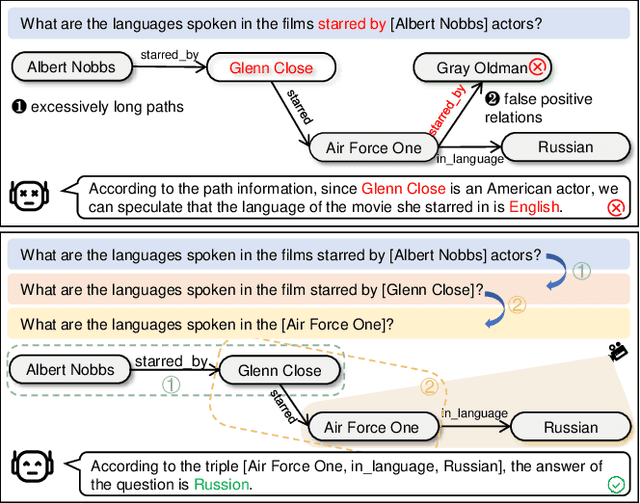
Large Language Models (LLMs) may suffer from hallucinations in real-world applications due to the lack of relevant knowledge. In contrast, knowledge graphs encompass extensive, multi-relational structures that store a vast array of symbolic facts. Consequently, integrating LLMs with knowledge graphs has been extensively explored, with Knowledge Graph Question Answering (KGQA) serving as a critical touchstone for the integration. This task requires LLMs to answer natural language questions by retrieving relevant triples from knowledge graphs. However, existing methods face two significant challenges: \textit{excessively long reasoning paths distracting from the answer generation}, and \textit{false-positive relations hindering the path refinement}. In this paper, we propose an iterative interactive KGQA framework that leverages the interactive learning capabilities of LLMs to perform reasoning and Debating over Graphs (DoG). Specifically, DoG employs a subgraph-focusing mechanism, allowing LLMs to perform answer trying after each reasoning step, thereby mitigating the impact of lengthy reasoning paths. On the other hand, DoG utilizes a multi-role debate team to gradually simplify complex questions, reducing the influence of false-positive relations. This debate mechanism ensures the reliability of the reasoning process. Experimental results on five public datasets demonstrate the effectiveness and superiority of our architecture. Notably, DoG outperforms the state-of-the-art method ToG by 23.7\% and 9.1\% in accuracy on WebQuestions and GrailQA, respectively. Furthermore, the integration experiments with various LLMs on the mentioned datasets highlight the flexibility of DoG. Code is available at \url{https://github.com/reml-group/DoG}.
Look, Listen, and Answer: Overcoming Biases for Audio-Visual Question Answering
Apr 18, 2024



Audio-Visual Question Answering (AVQA) is a complex multi-modal reasoning task, demanding intelligent systems to accurately respond to natural language queries based on audio-video input pairs. Nevertheless, prevalent AVQA approaches are prone to overlearning dataset biases, resulting in poor robustness. Furthermore, current datasets may not provide a precise diagnostic for these methods. To tackle these challenges, firstly, we propose a novel dataset, \textit{MUSIC-AVQA-R}, crafted in two steps: rephrasing questions within the test split of a public dataset (\textit{MUSIC-AVQA}) and subsequently introducing distribution shifts to split questions. The former leads to a large, diverse test space, while the latter results in a comprehensive robustness evaluation on rare, frequent, and overall questions. Secondly, we propose a robust architecture that utilizes a multifaceted cycle collaborative debiasing strategy to overcome bias learning. Experimental results show that this architecture achieves state-of-the-art performance on both datasets, especially obtaining a significant improvement of 9.68\% on the proposed dataset. Extensive ablation experiments are conducted on these two datasets to validate the effectiveness of the debiasing strategy. Additionally, we highlight the limited robustness of existing multi-modal QA methods through the evaluation on our dataset.
Robust Visual Question Answering: Datasets, Methods, and Future Challenges
Jul 21, 2023Visual question answering requires a system to provide an accurate natural language answer given an image and a natural language question. However, it is widely recognized that previous generic VQA methods often exhibit a tendency to memorize biases present in the training data rather than learning proper behaviors, such as grounding images before predicting answers. Therefore, these methods usually achieve high in-distribution but poor out-of-distribution performance. In recent years, various datasets and debiasing methods have been proposed to evaluate and enhance the VQA robustness, respectively. This paper provides the first comprehensive survey focused on this emerging fashion. Specifically, we first provide an overview of the development process of datasets from in-distribution and out-of-distribution perspectives. Then, we examine the evaluation metrics employed by these datasets. Thirdly, we propose a typology that presents the development process, similarities and differences, robustness comparison, and technical features of existing debiasing methods. Furthermore, we analyze and discuss the robustness of representative vision-and-language pre-training models on VQA. Finally, through a thorough review of the available literature and experimental analysis, we discuss the key areas for future research from various viewpoints.
Curvature Regularization to Prevent Distortion in Graph Embedding
Nov 28, 2020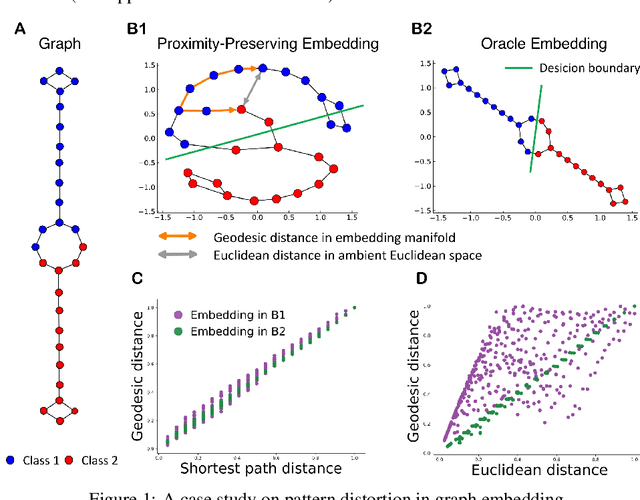
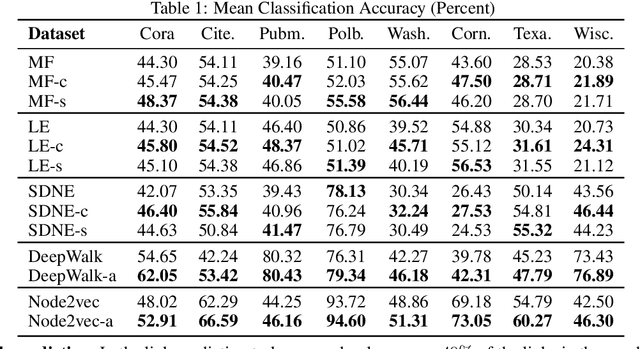
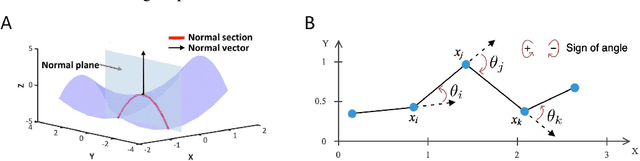
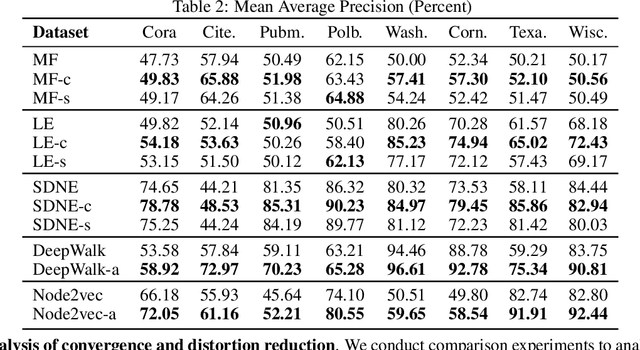
Recent research on graph embedding has achieved success in various applications. Most graph embedding methods preserve the proximity in a graph into a manifold in an embedding space. We argue an important but neglected problem about this proximity-preserving strategy: Graph topology patterns, while preserved well into an embedding manifold by preserving proximity, may distort in the ambient embedding Euclidean space, and hence to detect them becomes difficult for machine learning models. To address the problem, we propose curvature regularization, to enforce flatness for embedding manifolds, thereby preventing the distortion. We present a novel angle-based sectional curvature, termed ABS curvature, and accordingly three kinds of curvature regularization to induce flat embedding manifolds during graph embedding. We integrate curvature regularization into five popular proximity-preserving embedding methods, and empirical results in two applications show significant improvements on a wide range of open graph datasets.
Geom-GCN: Geometric Graph Convolutional Networks
Feb 14, 2020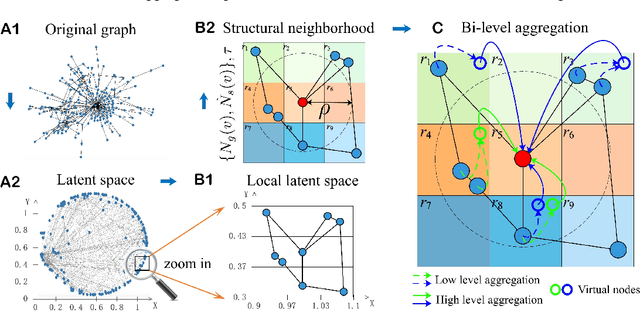
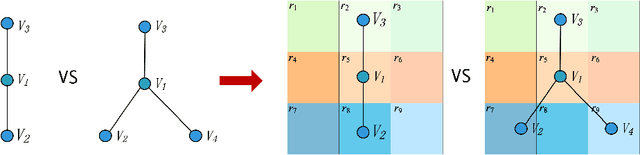
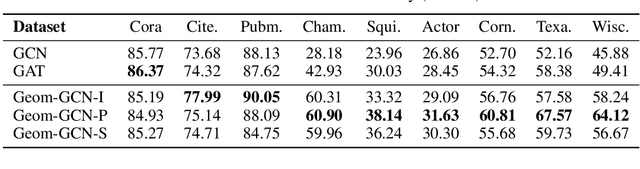
Message-passing neural networks (MPNNs) have been successfully applied to representation learning on graphs in a variety of real-world applications. However, two fundamental weaknesses of MPNNs' aggregators limit their ability to represent graph-structured data: losing the structural information of nodes in neighborhoods and lacking the ability to capture long-range dependencies in disassortative graphs. Few studies have noticed the weaknesses from different perspectives. From the observations on classical neural network and network geometry, we propose a novel geometric aggregation scheme for graph neural networks to overcome the two weaknesses. The behind basic idea is the aggregation on a graph can benefit from a continuous space underlying the graph. The proposed aggregation scheme is permutation-invariant and consists of three modules, node embedding, structural neighborhood, and bi-level aggregation. We also present an implementation of the scheme in graph convolutional networks, termed Geom-GCN (Geometric Graph Convolutional Networks), to perform transductive learning on graphs. Experimental results show the proposed Geom-GCN achieved state-of-the-art performance on a wide range of open datasets of graphs. Code is available at https://github.com/graphdml-uiuc-jlu/geom-gcn.