 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Training Dialogue Data from Large Language Model based Task Bots
Mar 02, 2026Large Language Models (LLMs) have been widely adopted to enhance Task-Oriented Dialogue Systems (TODS) by modeling complex language patterns and delivering contextually appropriate responses. However, this integration introduces significant privacy risks, as LLMs, functioning as soft knowledge bases that compress extensive training data into rich knowledge representations, can inadvertently memorize training dialogue data containing not only identifiable information such as phone numbers but also entire dialogue-level events like complete travel schedules. Despite the critical nature of this privacy concern, how LLM memorization is inherited in developing task bots remains unexplored. In this work, we address this gap through a systematic quantitative study that involves evaluating existing training data extraction attacks, analyzing key characteristics of task-oriented dialogue modeling that render existing methods ineffective, and proposing novel attack techniques tailored for LLM-based TODS that enhance both response sampling and membership inference. Experimental results demonstrate the effectiveness of our proposed data extraction attack. Our method can extract thousands of training labels of dialogue states with best-case precision exceeding 70%. Furthermore, we provide an in-depth analysis of training data memorization in LLM-based TODS by identifying and quantifying key influencing factors and discussing targeted mitigation strategies.
FloCA: Towards Faithful and Logically Consistent Flowchart Reasoning
Feb 15, 2026Flowchart-oriented dialogue (FOD) systems aim to guide users through multi-turn decision-making or operational procedures by following a domain-specific flowchart to achieve a task goal. In this work, we formalize flowchart reasoning in FOD as grounding user input to flowchart nodes at each dialogue turn while ensuring node transition is consistent with the correct flowchart path. Despite recent advances of LLMs in task-oriented dialogue systems, adapting them to FOD still faces two limitations: (1) LLMs lack an explicit mechanism to represent and reason over flowchart topology, and (2) they are prone to hallucinations, leading to unfaithful flowchart reasoning. To address these limitations, we propose FloCA, a zero-shot flowchart-oriented conversational agent. FloCA uses an LLM for intent understanding and response generation while delegating flowchart reasoning to an external tool that performs topology-constrained graph execution, ensuring faithful and logically consistent node transitions across dialogue turns. We further introduce an evaluation framework with an LLM-based user simulator and five new metrics covering reasoning accuracy and interaction efficiency. Extensive experiments on FLODIAL and PFDial datasets highlight the bottlenecks of existing LLM-based methods and demonstrate the superiority of FloCA. Our codes are available at https://github.com/Jinzi-Zou/FloCA-flowchart-reasoning.
A Theoretical Analysis of Detecting Large Model-Generated Time Series
Nov 12, 2025Motivated by the increasing risks of data misuse and fabrication, we investigate the problem of identifying synthetic time series generated by Time-Series Large Models (TSLMs) in this work. While there are extensive researches on detecting model generated text, we find that these existing methods are not applicable to time series data due to the fundamental modality difference, as time series usually have lower information density and smoother probability distributions than text data, which limit the discriminative power of token-based detectors. To address this issue, we examine the subtle distributional differences between real and model-generated time series and propose the contraction hypothesis, which states that model-generated time series, unlike real ones, exhibit progressively decreasing uncertainty under recursive forecasting. We formally prove this hypothesis under theoretical assumptions on model behavior and time series structure. Model-generated time series exhibit progressively concentrated distributions under recursive forecasting, leading to uncertainty contraction. We provide empirical validation of the hypothesis across diverse datasets. Building on this insight, we introduce the Uncertainty Contraction Estimator (UCE), a white-box detector that aggregates uncertainty metrics over successive prefixes to identify TSLM-generated time series. Extensive experiments on 32 datasets show that UCE consistently outperforms state-of-the-art baselines, offering a reliable and generalizable solution for detecting model-generated time series.
How Vital is the Jurisprudential Relevance: Law Article Intervened Legal Case Retrieval and Matching
Feb 25, 2025



Legal case retrieval (LCR) aims to automatically scour for comparable legal cases based on a given query, which is crucial for offering relevant precedents to support the judgment in intelligent legal systems. Due to similar goals, it is often associated with a similar case matching (LCM) task. To address them, a daunting challenge is assessing the uniquely defined legal-rational similarity within the judicial domain, which distinctly deviates from the semantic similarities in general text retrieval. Past works either tagged domain-specific factors or incorporated reference laws to capture legal-rational information. However, their heavy reliance on expert or unrealistic assumptions restricts their practical applicability in real-world scenarios. In this paper, we propose an end-to-end model named LCM-LAI to solve the above challenges. Through meticulous theoretical analysis, LCM-LAI employs a dependent multi-task learning framework to capture legal-rational information within legal cases by a law article prediction (LAP) sub-task, without any additional assumptions in inference. Besides, LCM-LAI proposes an article-aware attention mechanism to evaluate the legal-rational similarity between across-case sentences based on law distribution, which is more effective than conventional semantic similarity. Weperform a series of exhaustive experiments including two different tasks involving four real-world datasets. Results demonstrate that LCM-LAI achieves state-of-the-art performance.
Distinguish Confusion in Legal Judgment Prediction via Revised Relation Knowledge
Aug 18, 2024

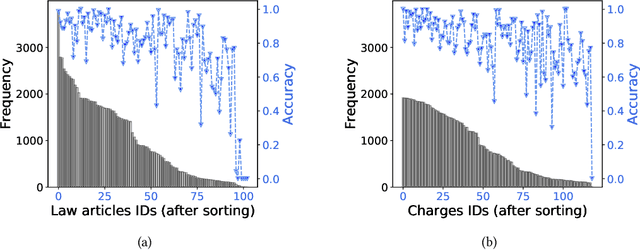
Legal Judgment Prediction (LJP) aims to automatically predict a law case's judgment results based on the text description of its facts. In practice, the confusing law articles (or charges) problem frequently occurs, reflecting that the law cases applicable to similar articles (or charges) tend to be misjudged. Although some recent works based on prior knowledge solve this issue well, they ignore that confusion also occurs between law articles with a high posterior semantic similarity due to the data imbalance problem instead of only between the prior highly similar ones, which is this work's further finding. This paper proposes an end-to-end model named \textit{D-LADAN} to solve the above challenges. On the one hand, D-LADAN constructs a graph among law articles based on their text definition and proposes a graph distillation operation (GDO) to distinguish the ones with a high prior semantic similarity. On the other hand, D-LADAN presents a novel momentum-updated memory mechanism to dynamically sense the posterior similarity between law articles (or charges) and a weighted GDO to adaptively capture the distinctions for revising the inductive bias caused by the data imbalance problem. We perform extensive experiments to demonstrate that D-LADAN significantly outperforms state-of-the-art methods in accuracy and robustness.
Representation Learning of Tangled Key-Value Sequence Data for Early Classification
Apr 11, 2024



Key-value sequence data has become ubiquitous and naturally appears in a variety of real-world applications, ranging from the user-product purchasing sequences in e-commerce, to network packet sequences forwarded by routers in networking. Classifying these key-value sequences is important in many scenarios such as user profiling and malicious applications identification. In many time-sensitive scenarios, besides the requirement of classifying a key-value sequence accurately, it is also desired to classify a key-value sequence early, in order to respond fast. However, these two goals are conflicting in nature, and it is challenging to achieve them simultaneously. In this work, we formulate a novel tangled key-value sequence early classification problem, where a tangled key-value sequence is a mixture of several concurrent key-value sequences with different keys. The goal is to classify each individual key-value sequence sharing a same key both accurately and early. To address this problem, we propose a novel method, i.e., Key-Value sequence Early Co-classification (KVEC), which leverages both inner- and inter-correlations of items in a tangled key-value sequence through key correlation and value correlation to learn a better sequence representation. Meanwhile, a time-aware halting policy decides when to stop the ongoing key-value sequence and classify it based on current sequence representation. Experiments on both real-world and synthetic datasets demonstrate that our method outperforms the state-of-the-art baselines significantly. KVEC improves the prediction accuracy by up to $4.7 - 17.5\%$ under the same prediction earliness condition, and improves the harmonic mean of accuracy and earliness by up to $3.7 - 14.0\%$.
Robust Visual Question Answering: Datasets, Methods, and Future Challenges
Jul 21, 2023Visual question answering requires a system to provide an accurate natural language answer given an image and a natural language question. However, it is widely recognized that previous generic VQA methods often exhibit a tendency to memorize biases present in the training data rather than learning proper behaviors, such as grounding images before predicting answers. Therefore, these methods usually achieve high in-distribution but poor out-of-distribution performance. In recent years, various datasets and debiasing methods have been proposed to evaluate and enhance the VQA robustness, respectively. This paper provides the first comprehensive survey focused on this emerging fashion. Specifically, we first provide an overview of the development process of datasets from in-distribution and out-of-distribution perspectives. Then, we examine the evaluation metrics employed by these datasets. Thirdly, we propose a typology that presents the development process, similarities and differences, robustness comparison, and technical features of existing debiasing methods. Furthermore, we analyze and discuss the robustness of representative vision-and-language pre-training models on VQA. Finally, through a thorough review of the available literature and experimental analysis, we discuss the key areas for future research from various viewpoints.
Mitigating Language Model Hallucination with Interactive Question-Knowledge Alignment
May 23, 2023Despite the remarkable recent advances in language models, they still struggle with the hallucination problem and can generate misleading and unsupported responses. A common approach to mitigate the hallucination issue is retrieving and incorporating supporting evidence from a knowledge base. However, user questions usually do not align well with the stored knowledge, as they are unaware of the information available before asking questions. This misalignment can limit the language model's ability to locate and utilize the knowledge, potentially forcing it to hallucinate by ignoring or overriding the retrieved evidence. To address this issue, we introduce MixAlign, a framework that interacts with both the user and the knowledge base to obtain and integrate clarifications on how the user question relates to the stored information. MixAlign employs a language model to achieve automatic question-knowledge alignment and, if necessary, further enhances this alignment through human user clarifications. Experimental results demonstrate significant improvements over state-of-the-art methods, showcasing the effectiveness of MixAlign in mitigating language model hallucination.
Multi-Action Dialog Policy Learning from Logged User Feedback
Feb 27, 2023Multi-action dialog policy, which generates multiple atomic dialog actions per turn, has been widely applied in task-oriented dialog systems to provide expressive and efficient system responses. Existing policy models usually imitate action combinations from the labeled multi-action dialog examples. Due to data limitations, they generalize poorly toward unseen dialog flows. While reinforcement learning-based methods are proposed to incorporate the service ratings from real users and user simulators as external supervision signals, they suffer from sparse and less credible dialog-level rewards. To cope with this problem, we explore to improve multi-action dialog policy learning with explicit and implicit turn-level user feedback received for historical predictions (i.e., logged user feedback) that are cost-efficient to collect and faithful to real-world scenarios. The task is challenging since the logged user feedback provides only partial label feedback limited to the particular historical dialog actions predicted by the agent. To fully exploit such feedback information, we propose BanditMatch, which addresses the task from a feedback-enhanced semi-supervised learning perspective with a hybrid objective of semi-supervised learning and bandit learning. BanditMatch integrates pseudo-labeling methods to better explore the action space through constructing full label feedback. Extensive experiments show that our BanditMatch outperforms the state-of-the-art methods by generating more concise and informative responses. The source code and the appendix of this paper can be obtained from https://github.com/ShuoZhangXJTU/BanditMatch.
Fast Gumbel-Max Sketch and its Applications
Feb 10, 2023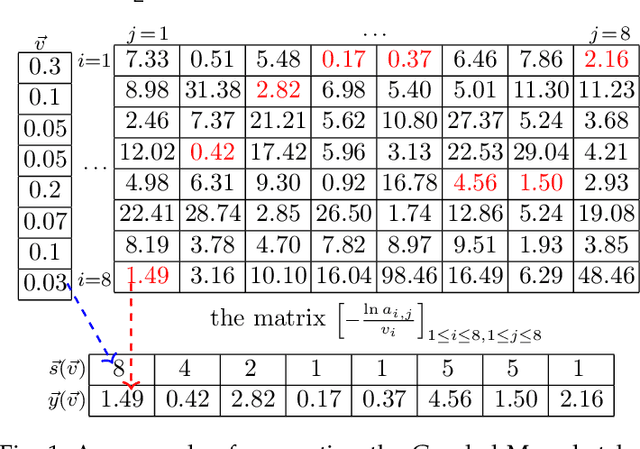
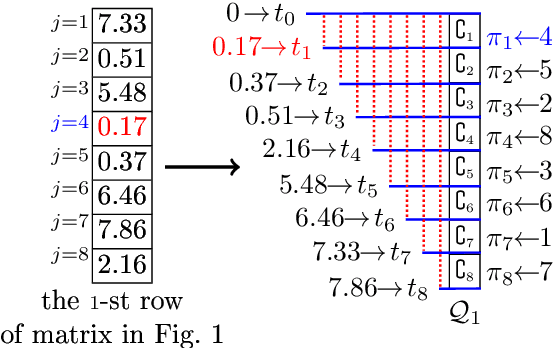
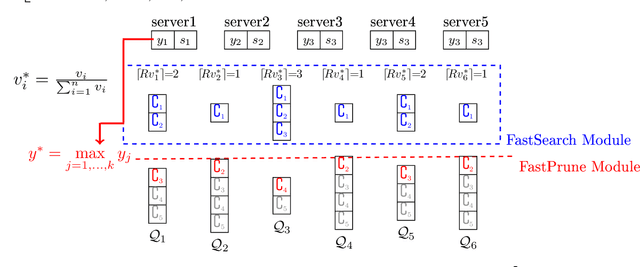
The well-known Gumbel-Max Trick for sampling elements from a categorical distribution (or more generally a non-negative vector) and its variants have been widely used in areas such as machine learning and information retrieval. To sample a random element $i$ in proportion to its positive weight $v_i$, the Gumbel-Max Trick first computes a Gumbel random variable $g_i$ for each positive weight element $i$, and then samples the element $i$ with the largest value of $g_i+\ln v_i$. Recently, applications including similarity estimation and weighted cardinality estimation require to generate $k$ independent Gumbel-Max variables from high dimensional vectors. However, it is computationally expensive for a large $k$ (e.g., hundreds or even thousands) when using the traditional Gumbel-Max Trick. To solve this problem, we propose a novel algorithm, FastGM, which reduces the time complexity from $O(kn^+)$ to $O(k \ln k + n^+)$, where $n^+$ is the number of positive elements in the vector of interest. FastGM stops the procedure of Gumbel random variables computing for many elements, especially for those with small weights. We perform experiments on a variety of real-world datasets and the experimental results demonstrate that FastGM is orders of magnitude faster than state-of-the-art methods without sacrificing accuracy or incurring additional expenses.