 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Language Representation with Constructional Information for Natural Language Understanding
Jun 05, 2023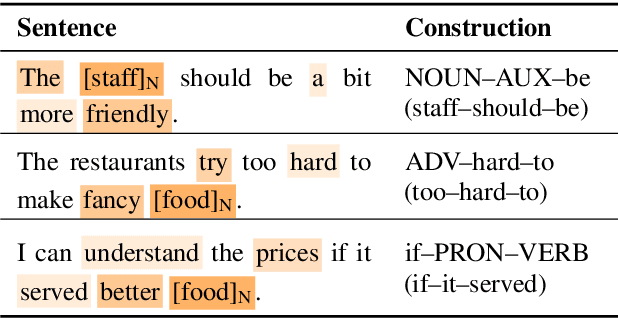
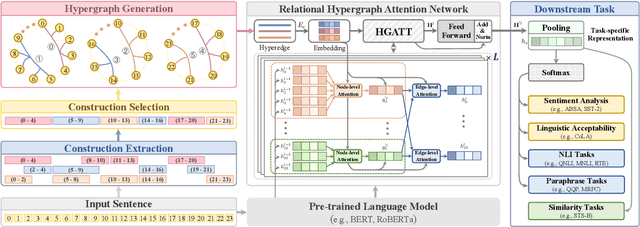
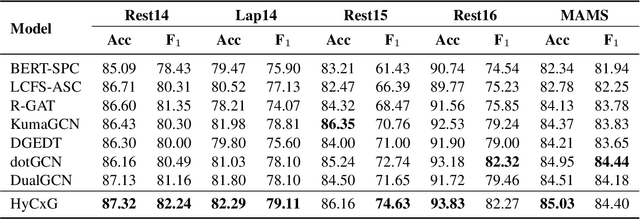
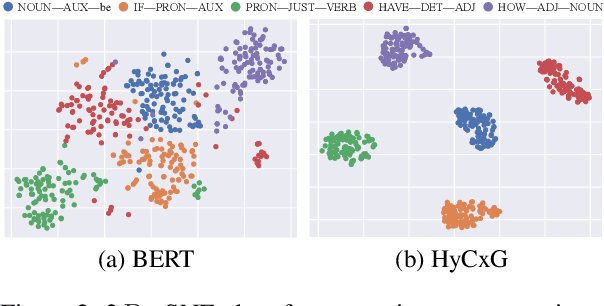
Natural language understanding (NLU) is an essential branch of natural language processing, which relies on representations generated by pre-trained language models (PLMs). However, PLMs primarily focus on acquiring lexico-semantic information, while they may be unable to adequately handle the meaning of constructions. To address this issue, we introduce construction grammar (CxG), which highlights the pairings of form and meaning, to enrich language representation. We adopt usage-based construction grammar as the basis of our work, which is highly compatible with statistical models such as PLMs. Then a HyCxG framework is proposed to enhance language representation through a three-stage solution. First, all constructions are extracted from sentences via a slot-constraints approach. As constructions can overlap with each other, bringing redundancy and imbalance, we formulate the conditional max coverage problem for selecting the discriminative constructions. Finally, we propose a relational hypergraph attention network to acquire representation from constructional information by capturing high-order word interactions among constructions. Extensive experiments demonstrate the superiority of the proposed model on a variety of NLU tasks.
Multi-Action Dialog Policy Learning from Logged User Feedback
Feb 27, 2023Multi-action dialog policy, which generates multiple atomic dialog actions per turn, has been widely applied in task-oriented dialog systems to provide expressive and efficient system responses. Existing policy models usually imitate action combinations from the labeled multi-action dialog examples. Due to data limitations, they generalize poorly toward unseen dialog flows. While reinforcement learning-based methods are proposed to incorporate the service ratings from real users and user simulators as external supervision signals, they suffer from sparse and less credible dialog-level rewards. To cope with this problem, we explore to improve multi-action dialog policy learning with explicit and implicit turn-level user feedback received for historical predictions (i.e., logged user feedback) that are cost-efficient to collect and faithful to real-world scenarios. The task is challenging since the logged user feedback provides only partial label feedback limited to the particular historical dialog actions predicted by the agent. To fully exploit such feedback information, we propose BanditMatch, which addresses the task from a feedback-enhanced semi-supervised learning perspective with a hybrid objective of semi-supervised learning and bandit learning. BanditMatch integrates pseudo-labeling methods to better explore the action space through constructing full label feedback. Extensive experiments show that our BanditMatch outperforms the state-of-the-art methods by generating more concise and informative responses. The source code and the appendix of this paper can be obtained from https://github.com/ShuoZhangXJTU/BanditMatch.