 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical Analysis of Detecting Large Model-Generated Time Series
Nov 12, 2025Motivated by the increasing risks of data misuse and fabrication, we investigate the problem of identifying synthetic time series generated by Time-Series Large Models (TSLMs) in this work. While there are extensive researches on detecting model generated text, we find that these existing methods are not applicable to time series data due to the fundamental modality difference, as time series usually have lower information density and smoother probability distributions than text data, which limit the discriminative power of token-based detectors. To address this issue, we examine the subtle distributional differences between real and model-generated time series and propose the contraction hypothesis, which states that model-generated time series, unlike real ones, exhibit progressively decreasing uncertainty under recursive forecasting. We formally prove this hypothesis under theoretical assumptions on model behavior and time series structure. Model-generated time series exhibit progressively concentrated distributions under recursive forecasting, leading to uncertainty contraction. We provide empirical validation of the hypothesis across diverse datasets. Building on this insight, we introduce the Uncertainty Contraction Estimator (UCE), a white-box detector that aggregates uncertainty metrics over successive prefixes to identify TSLM-generated time series. Extensive experiments on 32 datasets show that UCE consistently outperforms state-of-the-art baselines, offering a reliable and generalizable solution for detecting model-generated time series.
Deliberation on Priors: Trustworthy Reasoning of Large Language Models on Knowledge Graphs
May 21, 2025Knowledge graph-based retrieval-augmented generation seeks to mitigate hallucinations in Large Language Models (LLMs) caused by insufficient or outdated knowledge. However, existing methods often fail to fully exploit the prior knowledge embedded in knowledge graphs (KGs), particularly their structural information and explicit or implicit constraints. The former can enhance the faithfulness of LLMs' reasoning, while the latter can improve the reliability of response generation. Motivated by these, we propose a trustworthy reasoning framework, termed Deliberation over Priors (DP), which sufficiently utilizes the priors contained in KGs. Specifically, DP adopts a progressive knowledge distillation strategy that integrates structural priors into LLMs through a combination of supervised fine-tuning and Kahneman-Tversky optimization, thereby improving the faithfulness of relation path generation. Furthermore, our framework employs a reasoning-introspection strategy, which guides LLMs to perform refined reasoning verification based on extracted constraint priors, ensuring the reliability of response generation. Extensive experiments on three benchmark datasets demonstrate that DP achieves new state-of-the-art performance, especially a Hit@1 improvement of 13% on the ComplexWebQuestions dataset, and generates highly trustworthy responses. We also conduct various analyses to verify its flexibility and practicality. The code is available at https://github.com/reml-group/Deliberation-on-Priors.
LightPROF: A Lightweight Reasoning Framework for Large Language Model on Knowledge Graph
Apr 04, 2025



Large Language Models (LLMs) have impressive capabilities in text understanding and zero-shot reasoning. However, delays in knowledge updates may cause them to reason incorrectly or produce harmful results. Knowledge Graphs (KGs) provide rich and reliable contextual information for the reasoning process of LLMs by structurally organizing and connecting a wide range of entities and relations. Existing KG-based LLM reasoning methods only inject KGs' knowledge into prompts in a textual form, ignoring its structural information. Moreover, they mostly rely on close-source models or open-source models with large parameters, which poses challenges to high resource consumption. To address this, we propose a novel Lightweight and efficient Prompt learning-ReasOning Framework for KGQA (LightPROF), which leverages the full potential of LLMs to tackle complex reasoning tasks in a parameter-efficient manner. Specifically, LightPROF follows a "Retrieve-Embed-Reason process", first accurately, and stably retrieving the corresponding reasoning graph from the KG through retrieval module. Next, through a Transformer-based Knowledge Adapter, it finely extracts and integrates factual and structural information from the KG, then maps this information to the LLM's token embedding space, creating an LLM-friendly prompt to be used by the LLM for the final reasoning. Additionally, LightPROF only requires training Knowledge Adapter and can be compatible with any open-source LLM. Extensive experiments on two public KGQA benchmarks demonstrate that LightPROF achieves superior performance with small-scale LLMs. Furthermore, LightPROF shows significant advantages in terms of input token count and reasoning time.
FortisAVQA and MAVEN: a Benchmark Dataset and Debiasing Framework for Robust Multimodal Reasoning
Apr 02, 2025
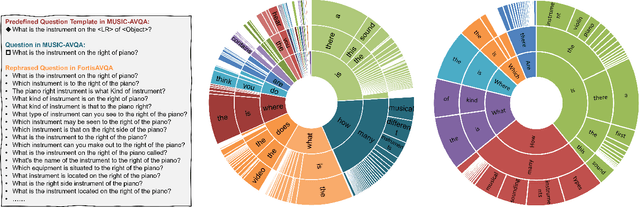
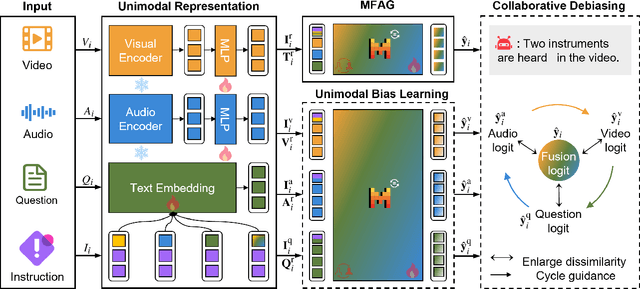
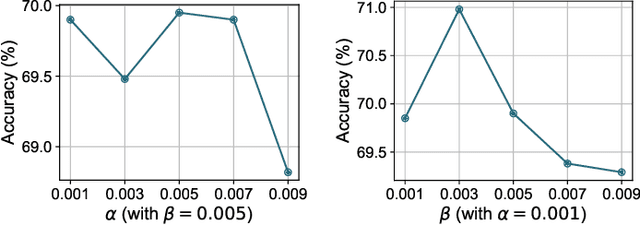
Audio-Visual Question Answering (AVQA) is a challenging multimodal reasoning task requiring intelligent systems to answer natural language queries based on paired audio-video inputs accurately. However, existing AVQA approaches often suffer from overfitting to dataset biases, leading to poor robustness. Moreover, current datasets may not effectively diagnose these methods. To address these challenges, we first introduce a novel dataset, FortisAVQA, constructed in two stages: (1) rephrasing questions in the test split of the public MUSIC-AVQA dataset and (2) introducing distribution shifts across questions. The first stage expands the test space with greater diversity, while the second enables a refined robustness evaluation across rare, frequent, and overall question distributions. Second, we introduce a robust Multimodal Audio-Visual Epistemic Network (MAVEN) that leverages a multifaceted cycle collaborative debiasing strategy to mitigate bias learning. Experimental results demonstrate that our architecture achieves state-of-the-art performance on FortisAVQA, with a notable improvement of 7.81\%. Extensive ablation studies on both datasets validate the effectiveness of our debiasing components. Additionally, our evaluation reveals the limited robustness of existing multimodal QA methods. We also verify the plug-and-play capability of our strategy by integrating it with various baseline models across both datasets. Our dataset and code are available at https://github.com/reml-group/fortisavqa.
How Vital is the Jurisprudential Relevance: Law Article Intervened Legal Case Retrieval and Matching
Feb 25, 2025



Legal case retrieval (LCR) aims to automatically scour for comparable legal cases based on a given query, which is crucial for offering relevant precedents to support the judgment in intelligent legal systems. Due to similar goals, it is often associated with a similar case matching (LCM) task. To address them, a daunting challenge is assessing the uniquely defined legal-rational similarity within the judicial domain, which distinctly deviates from the semantic similarities in general text retrieval. Past works either tagged domain-specific factors or incorporated reference laws to capture legal-rational information. However, their heavy reliance on expert or unrealistic assumptions restricts their practical applicability in real-world scenarios. In this paper, we propose an end-to-end model named LCM-LAI to solve the above challenges. Through meticulous theoretical analysis, LCM-LAI employs a dependent multi-task learning framework to capture legal-rational information within legal cases by a law article prediction (LAP) sub-task, without any additional assumptions in inference. Besides, LCM-LAI proposes an article-aware attention mechanism to evaluate the legal-rational similarity between across-case sentences based on law distribution, which is more effective than conventional semantic similarity. Weperform a series of exhaustive experiments including two different tasks involving four real-world datasets. Results demonstrate that LCM-LAI achieves state-of-the-art performance.
Debate on Graph: a Flexible and Reliable Reasoning Framework for Large Language Models
Sep 05, 2024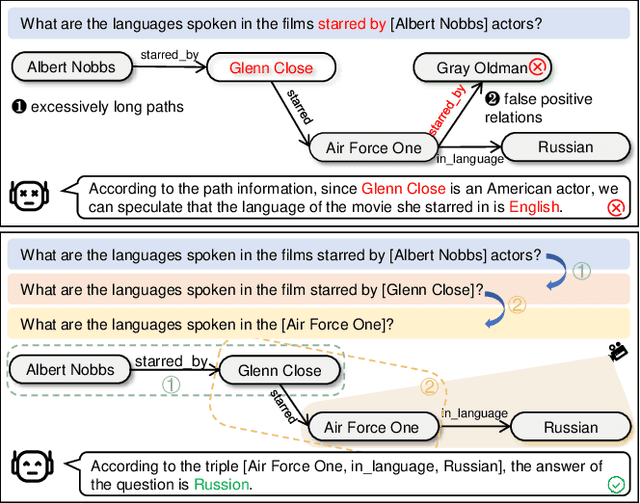
Large Language Models (LLMs) may suffer from hallucinations in real-world applications due to the lack of relevant knowledge. In contrast, knowledge graphs encompass extensive, multi-relational structures that store a vast array of symbolic facts. Consequently, integrating LLMs with knowledge graphs has been extensively explored, with Knowledge Graph Question Answering (KGQA) serving as a critical touchstone for the integration. This task requires LLMs to answer natural language questions by retrieving relevant triples from knowledge graphs. However, existing methods face two significant challenges: \textit{excessively long reasoning paths distracting from the answer generation}, and \textit{false-positive relations hindering the path refinement}. In this paper, we propose an iterative interactive KGQA framework that leverages the interactive learning capabilities of LLMs to perform reasoning and Debating over Graphs (DoG). Specifically, DoG employs a subgraph-focusing mechanism, allowing LLMs to perform answer trying after each reasoning step, thereby mitigating the impact of lengthy reasoning paths. On the other hand, DoG utilizes a multi-role debate team to gradually simplify complex questions, reducing the influence of false-positive relations. This debate mechanism ensures the reliability of the reasoning process. Experimental results on five public datasets demonstrate the effectiveness and superiority of our architecture. Notably, DoG outperforms the state-of-the-art method ToG by 23.7\% and 9.1\% in accuracy on WebQuestions and GrailQA, respectively. Furthermore, the integration experiments with various LLMs on the mentioned datasets highlight the flexibility of DoG. Code is available at \url{https://github.com/reml-group/DoG}.
Distinguish Confusion in Legal Judgment Prediction via Revised Relation Knowledge
Aug 18, 2024
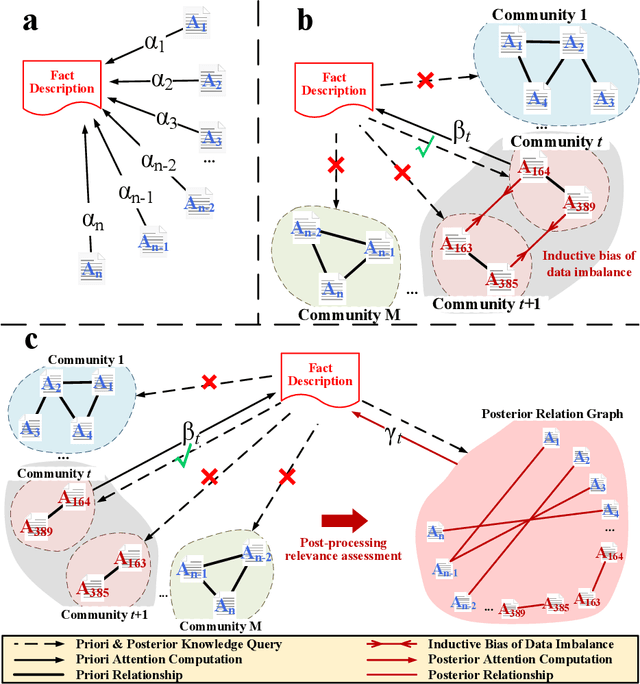

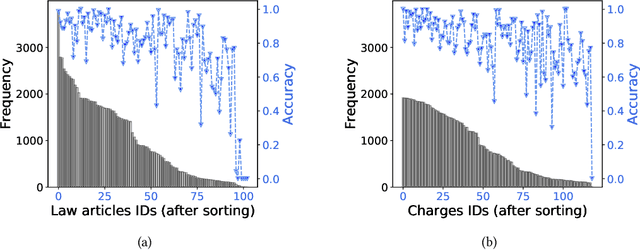
Legal Judgment Prediction (LJP) aims to automatically predict a law case's judgment results based on the text description of its facts. In practice, the confusing law articles (or charges) problem frequently occurs, reflecting that the law cases applicable to similar articles (or charges) tend to be misjudged. Although some recent works based on prior knowledge solve this issue well, they ignore that confusion also occurs between law articles with a high posterior semantic similarity due to the data imbalance problem instead of only between the prior highly similar ones, which is this work's further finding. This paper proposes an end-to-end model named \textit{D-LADAN} to solve the above challenges. On the one hand, D-LADAN constructs a graph among law articles based on their text definition and proposes a graph distillation operation (GDO) to distinguish the ones with a high prior semantic similarity. On the other hand, D-LADAN presents a novel momentum-updated memory mechanism to dynamically sense the posterior similarity between law articles (or charges) and a weighted GDO to adaptively capture the distinctions for revising the inductive bias caused by the data imbalance problem. We perform extensive experiments to demonstrate that D-LADAN significantly outperforms state-of-the-art methods in accuracy and robustness.
Look, Listen, and Answer: Overcoming Biases for Audio-Visual Question Answering
Apr 18, 2024



Audio-Visual Question Answering (AVQA) is a complex multi-modal reasoning task, demanding intelligent systems to accurately respond to natural language queries based on audio-video input pairs. Nevertheless, prevalent AVQA approaches are prone to overlearning dataset biases, resulting in poor robustness. Furthermore, current datasets may not provide a precise diagnostic for these methods. To tackle these challenges, firstly, we propose a novel dataset, \textit{MUSIC-AVQA-R}, crafted in two steps: rephrasing questions within the test split of a public dataset (\textit{MUSIC-AVQA}) and subsequently introducing distribution shifts to split questions. The former leads to a large, diverse test space, while the latter results in a comprehensive robustness evaluation on rare, frequent, and overall questions. Secondly, we propose a robust architecture that utilizes a multifaceted cycle collaborative debiasing strategy to overcome bias learning. Experimental results show that this architecture achieves state-of-the-art performance on both datasets, especially obtaining a significant improvement of 9.68\% on the proposed dataset. Extensive ablation experiments are conducted on these two datasets to validate the effectiveness of the debiasing strategy. Additionally, we highlight the limited robustness of existing multi-modal QA methods through the evaluation on our dataset.
Representation Learning of Tangled Key-Value Sequence Data for Early Classification
Apr 11, 2024



Key-value sequence data has become ubiquitous and naturally appears in a variety of real-world applications, ranging from the user-product purchasing sequences in e-commerce, to network packet sequences forwarded by routers in networking. Classifying these key-value sequences is important in many scenarios such as user profiling and malicious applications identification. In many time-sensitive scenarios, besides the requirement of classifying a key-value sequence accurately, it is also desired to classify a key-value sequence early, in order to respond fast. However, these two goals are conflicting in nature, and it is challenging to achieve them simultaneously. In this work, we formulate a novel tangled key-value sequence early classification problem, where a tangled key-value sequence is a mixture of several concurrent key-value sequences with different keys. The goal is to classify each individual key-value sequence sharing a same key both accurately and early. To address this problem, we propose a novel method, i.e., Key-Value sequence Early Co-classification (KVEC), which leverages both inner- and inter-correlations of items in a tangled key-value sequence through key correlation and value correlation to learn a better sequence representation. Meanwhile, a time-aware halting policy decides when to stop the ongoing key-value sequence and classify it based on current sequence representation. Experiments on both real-world and synthetic datasets demonstrate that our method outperforms the state-of-the-art baselines significantly. KVEC improves the prediction accuracy by up to $4.7 - 17.5\%$ under the same prediction earliness condition, and improves the harmonic mean of accuracy and earliness by up to $3.7 - 14.0\%$.
Robust Visual Question Answering: Datasets, Methods, and Future Challenges
Jul 21, 2023Visual question answering requires a system to provide an accurate natural language answer given an image and a natural language question. However, it is widely recognized that previous generic VQA methods often exhibit a tendency to memorize biases present in the training data rather than learning proper behaviors, such as grounding images before predicting answers. Therefore, these methods usually achieve high in-distribution but poor out-of-distribution performance. In recent years, various datasets and debiasing methods have been proposed to evaluate and enhance the VQA robustness, respectively. This paper provides the first comprehensive survey focused on this emerging fashion. Specifically, we first provide an overview of the development process of datasets from in-distribution and out-of-distribution perspectives. Then, we examine the evaluation metrics employed by these datasets. Thirdly, we propose a typology that presents the development process, similarities and differences, robustness comparison, and technical features of existing debiasing methods. Furthermore, we analyze and discuss the robustness of representative vision-and-language pre-training models on VQA. Finally, through a thorough review of the available literature and experimental analysis, we discuss the key areas for future research from various viewpoints.