 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinguish Confusion in Legal Judgment Prediction via Revised Relation Knowledge
Aug 18, 2024
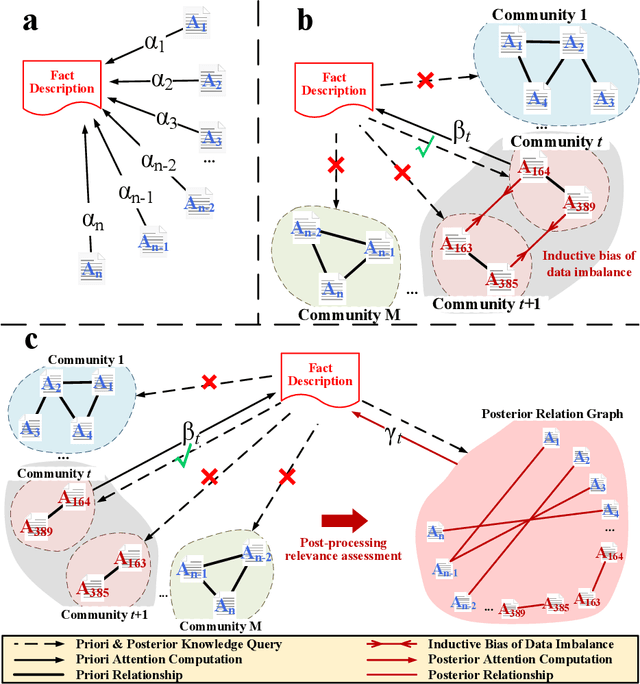

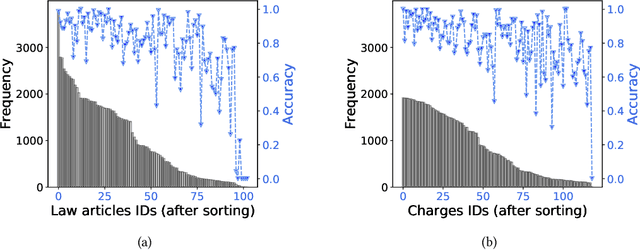
Legal Judgment Prediction (LJP) aims to automatically predict a law case's judgment results based on the text description of its facts. In practice, the confusing law articles (or charges) problem frequently occurs, reflecting that the law cases applicable to similar articles (or charges) tend to be misjudged. Although some recent works based on prior knowledge solve this issue well, they ignore that confusion also occurs between law articles with a high posterior semantic similarity due to the data imbalance problem instead of only between the prior highly similar ones, which is this work's further finding. This paper proposes an end-to-end model named \textit{D-LADAN} to solve the above challenges. On the one hand, D-LADAN constructs a graph among law articles based on their text definition and proposes a graph distillation operation (GDO) to distinguish the ones with a high prior semantic similarity. On the other hand, D-LADAN presents a novel momentum-updated memory mechanism to dynamically sense the posterior similarity between law articles (or charges) and a weighted GDO to adaptively capture the distinctions for revising the inductive bias caused by the data imbalance problem. We perform extensive experiments to demonstrate that D-LADAN significantly outperforms state-of-the-art methods in accuracy and robustness.
Federated Learning over Coupled Graphs
Jan 26, 2023Graphs are widely used to represent the relations among entities. When one owns the complete data, an entire graph can be easily built, therefore performing analysis on the graph is straightforward. However, in many scenarios, it is impractical to centralize the data due to data privacy concerns. An organization or party only keeps a part of the whole graph data, i.e., graph data is isolated from different parties. Recently, Federated Learning (FL) has been proposed to solve the data isolation issue, mainly for Euclidean data. It is still a challenge to apply FL on graph data because graphs contain topological information which is notorious for its non-IID nature and is hard to partition. In this work, we propose a novel FL framework for graph data, FedCog, to efficiently handle coupled graphs that are a kind of distributed graph data, but widely exist in a variety of real-world applications such as mobile carriers' communication networks and banks' transaction networks. We theoretically prove the correctness and security of FedCog. Experimental results demonstrate that our method FedCog significantly outperforms traditional FL methods on graphs. Remarkably, our FedCog improves the accuracy of node classification tasks by up to 14.7%.
Node Classification on Graphs with Few-Shot Novel Labels via Meta Transformed Network Embedding
Jul 06, 2020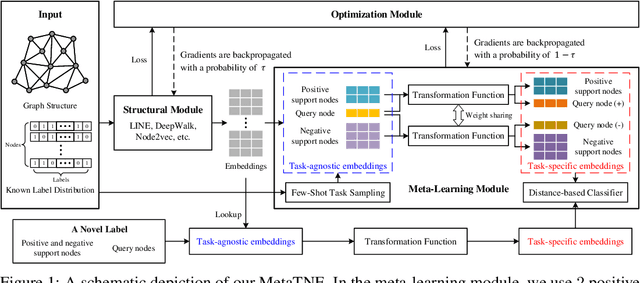
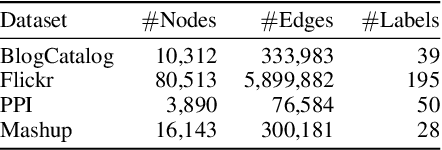
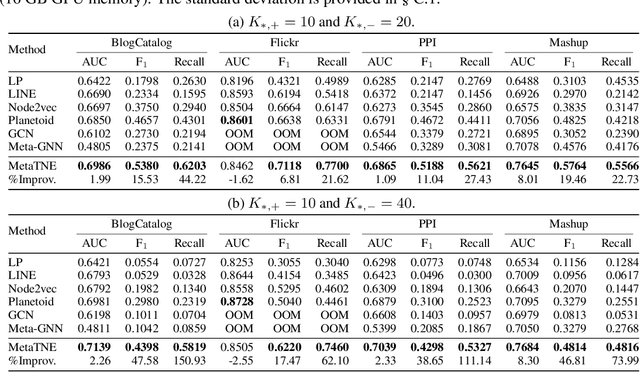
We study the problem of node classification on graphs with few-shot novel labels, which has two distinctive properties: (1) There are novel labels to emerge in the graph; (2) The novel labels have only a few representative nodes for training a classifier. The study of this problem is instructive and corresponds to many applications such as recommendations for newly formed groups with only a few users in online social networks. To cope with this problem, we propose a novel Meta Transformed Network Embedding framework (MetaTNE), which consists of three modules: (1) A \emph{structural module} provides each node a latent representation according to the graph structure. (2) A \emph{meta-learning module} captures the relationships between the graph structure and the node labels as prior knowledge in a meta-learning manner. Additionally, we introduce an \emph{embedding transformation function} that remedies the deficiency of the straightforward use of meta-learning. Inherently, the meta-learned prior knowledge can be used to facilitate the learning of few-shot novel labels. (3) An \emph{optimization module} employs a simple yet effective scheduling strategy to train the above two modules with a balance between graph structure learning and meta-learning. Experiments on four real-world datasets show that MetaTNE brings a huge improvement over the state-of-the-art methods.
Meta Reinforcement Learning with Task Embedding and Shared Policy
Jun 04, 2019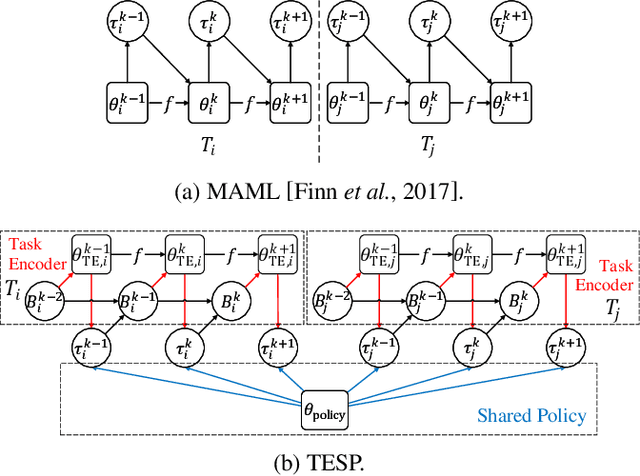
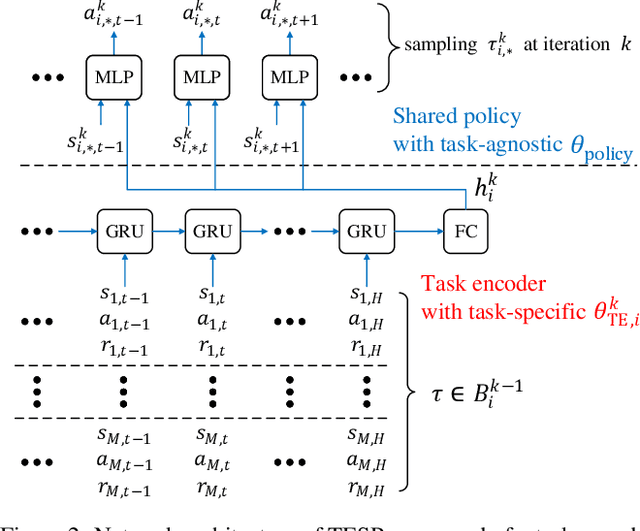
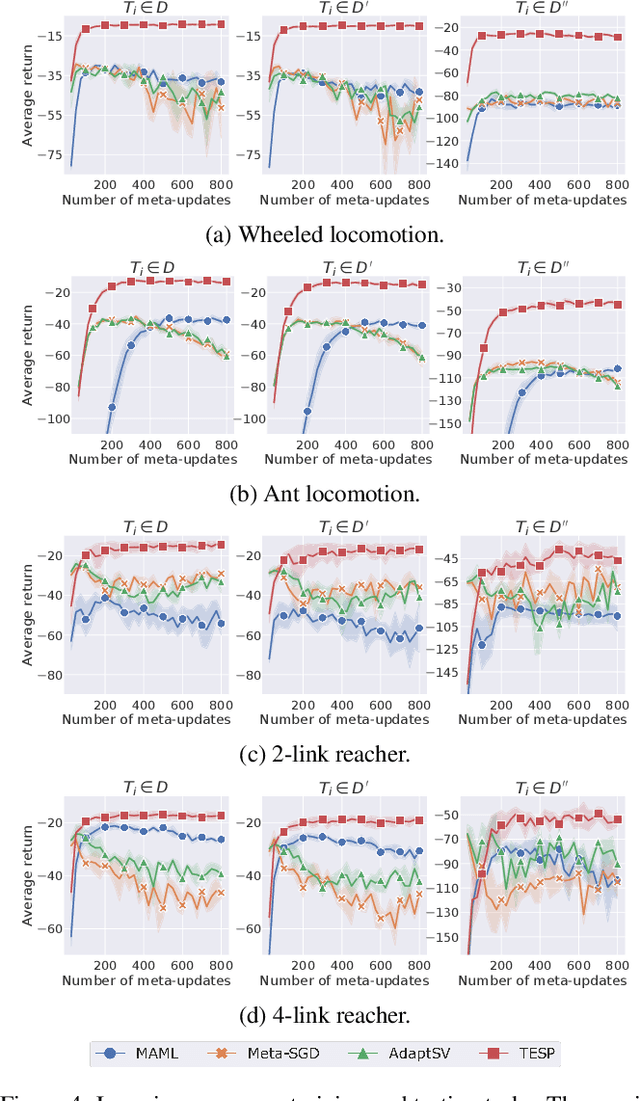
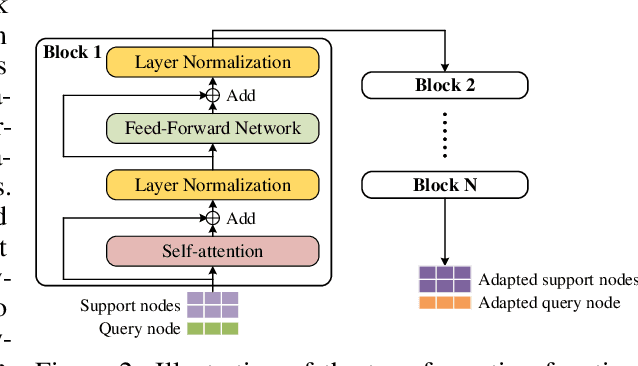
Despite significant progress, deep reinforcement learning (RL) suffers from data-inefficiency and limited generalization. Recent efforts apply meta-learning to learn a meta-learner from a set of RL tasks such that a novel but related task could be solved quickly. Though specific in some ways, different tasks in meta-RL are generally similar at a high level. However, most meta-RL methods do not explicitly and adequately model the specific and shared information among different tasks, which limits their ability to learn training tasks and to generalize to novel tasks. In this paper, we propose to capture the shared information on the one hand and meta-learn how to quickly abstract the specific information about a task on the other hand. Methodologically, we train an SGD meta-learner to quickly optimize a task encoder for each task, which generates a task embedding based on past experience. Meanwhile, we learn a policy which is shared across all tasks and conditioned on task embeddings. Empirical results on four simulated tasks demonstrate that our method has better learning capacity on both training and novel tasks and attains up to 3 to 4 times higher returns compared to baselines.