 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Reinforcement Learning with Task Embedding and Shared Policy
Paper and Code
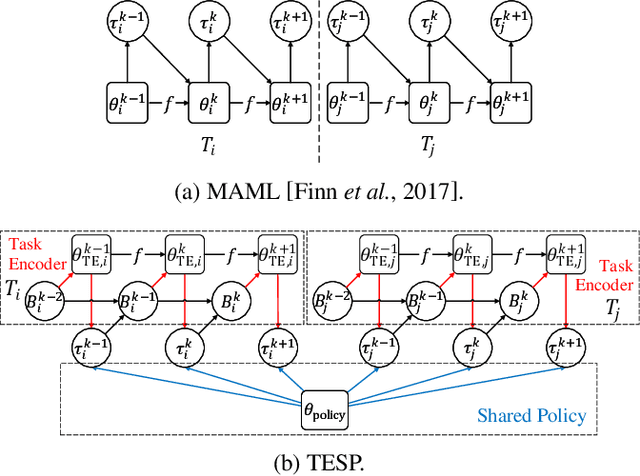
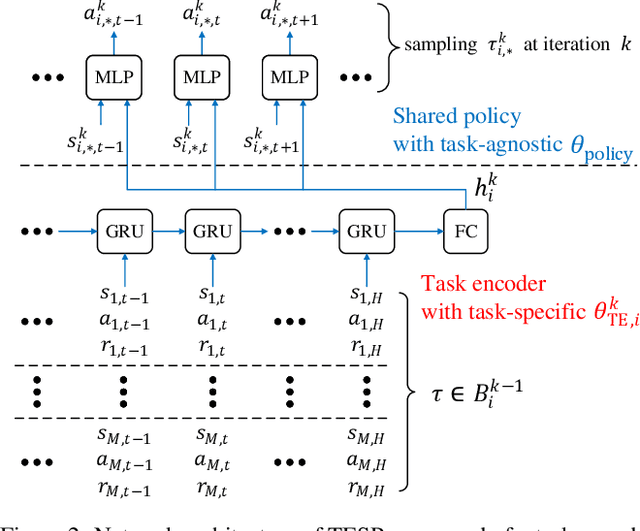
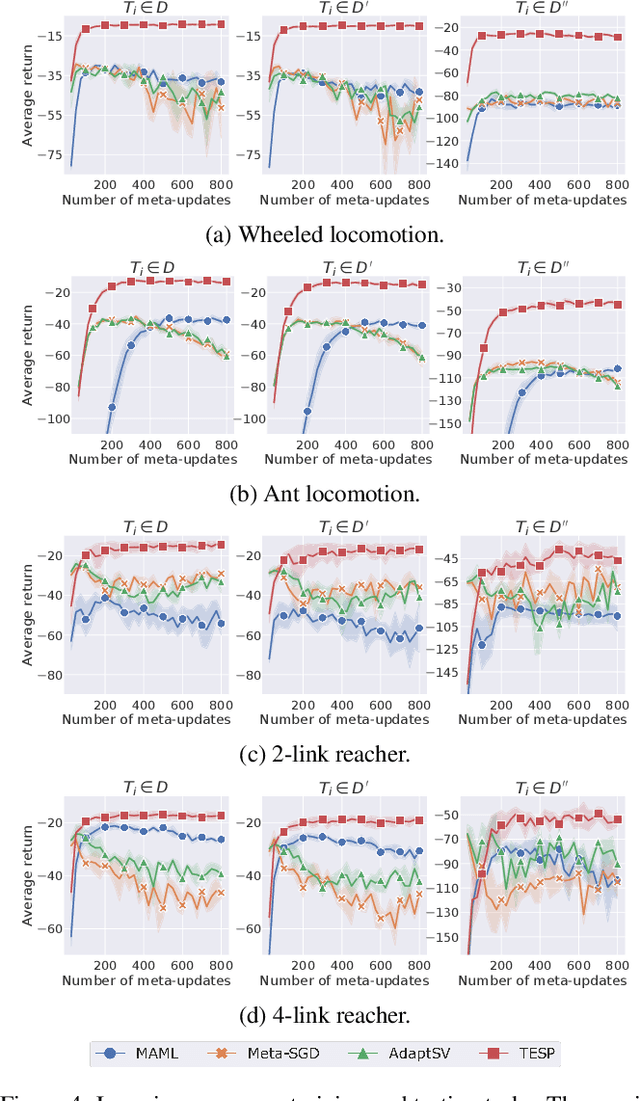
Despite significant progress, deep reinforcement learning (RL) suffers from data-inefficiency and limited generalization. Recent efforts apply meta-learning to learn a meta-learner from a set of RL tasks such that a novel but related task could be solved quickly. Though specific in some ways, different tasks in meta-RL are generally similar at a high level. However, most meta-RL methods do not explicitly and adequately model the specific and shared information among different tasks, which limits their ability to learn training tasks and to generalize to novel tasks. In this paper, we propose to capture the shared information on the one hand and meta-learn how to quickly abstract the specific information about a task on the other hand. Methodologically, we train an SGD meta-learner to quickly optimize a task encoder for each task, which generates a task embedding based on past experience. Meanwhile, we learn a policy which is shared across all tasks and conditioned on task embeddings. Empirical results on four simulated tasks demonstrate that our method has better learning capacity on both training and novel tasks and attains up to 3 to 4 times higher returns compared to baselines.