 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Should Memory Stay Silent: Measuring Memory-Use Boundaries in Memory-Augmented Conversational Agents
Jun 04, 2026Long-term memory enables language model agents to support personalized interactions, but it remains unclear when available memories warrant integration into responses. Existing memory evaluations emphasize retrieval accuracy and downstream task utility, while overlooking whether retrieved sensitive memory content is warranted in the current turn. We introduce RBI-Eval, a controlled measurement study built around a probe set that compares model behavior with and without access to sensitive memory under identical benign prompts. We evaluate four base LLMs against a matched no-memory reference across four memory-access settings: full-context exposure and three retrieval systems. Our results reveal substantial behavioral divergence. With memory available, the separation score for sensitive-memory integration decreases by 8.9\%--26.6\% relative to the matched no-memory reference for GPT-5.4-mini, but by 51.1\%--82.9\% for Claude-Sonnet-4.6, DeepSeek-V4-Flash, and Qwen3.5-9B. Control experiments on DeepSeek and GPT-5.4-mini show this effect is specific to sensitive content, rather than general personalization. Retrieval systems reduce exposure but do not eliminate integration once sensitive memory reaches the generator. These findings suggest safe personalization requires memory-aware decisions at both retrieval and generation time.
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
Enhancing Zero-Shot Time Series Forecasting in Off-the-Shelf LLMs via Noise Injection
Dec 23, 2025



Large Language Models (LLMs) have demonstrated effectiveness as zero-shot time series (TS) forecasters. The key challenge lies in tokenizing TS data into textual representations that align with LLMs' pre-trained knowledge. While existing work often relies on fine-tuning specialized modules to bridge this gap, a distinct, yet challenging, paradigm aims to leverage truly off-the-shelf LLMs without any fine-tuning whatsoever, relying solely on strategic tokenization of numerical sequences. The performance of these fully frozen models is acutely sensitive to the textual representation of the input data, as their parameters cannot adapt to distribution shifts. In this paper, we introduce a simple yet highly effective strategy to overcome this brittleness: injecting noise into the raw time series before tokenization. This non-invasive intervention acts as a form of inference-time augmentation, compelling the frozen LLM to extrapolate based on robust underlying temporal patterns rather than superficial numerical artifacts. We theoretically analyze this phenomenon and empirically validate its effectiveness across diverse benchmarks. Notably, to fully eliminate potential biases from data contamination during LLM pre-training, we introduce two novel TS datasets that fall outside all utilized LLMs' pre-training scopes, and consistently observe improved performance. This study provides a further step in directly leveraging off-the-shelf LLMs for time series forecasting.
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025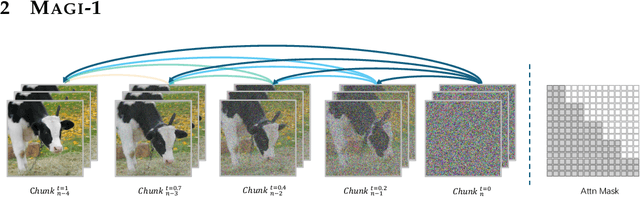
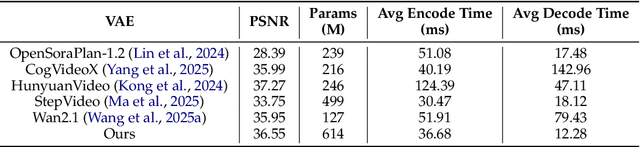
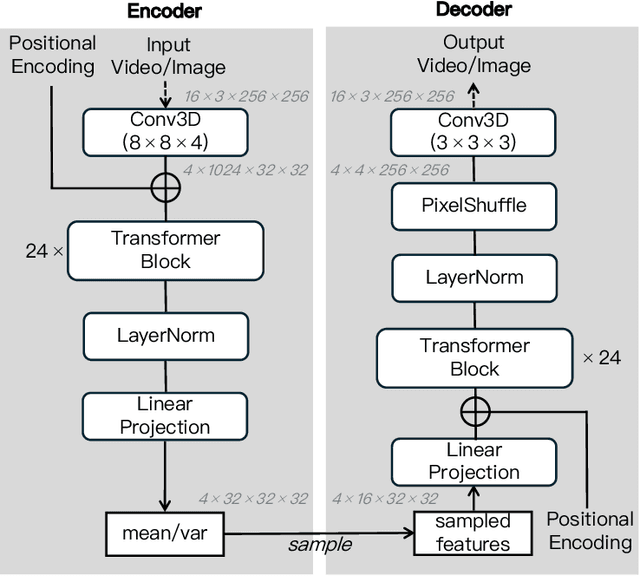
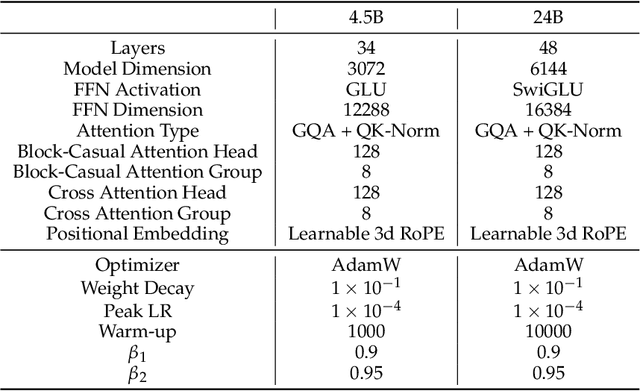
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
Dual-Splitting Conformal Prediction for Multi-Step Time Series Forecasting
Mar 27, 2025Time series forecasting is crucial for applications like resource scheduling and risk management, where multi-step predictions provide a comprehensive view of future trends. Uncertainty Quantification (UQ) is a mainstream approach for addressing forecasting uncertainties, with Conformal Prediction (CP) gaining attention due to its model-agnostic nature and statistical guarantees. However, most variants of CP are designed for single-step predictions and face challenges in multi-step scenarios, such as reliance on real-time data and limited scalability. This highlights the need for CP methods specifically tailored to multi-step forecasting. We propose the Dual-Splitting Conformal Prediction (DSCP) method, a novel CP approach designed to capture inherent dependencies within time-series data for multi-step forecasting. Experimental results on real-world datasets from four different domains demonstrate that the proposed DSCP significantly outperforms existing CP variants in terms of the Winkler Score, achieving a performance improvement of up to 23.59% compared to state-of-the-art methods. Furthermore, we deployed the DSCP approach for renewable energy generation and IT load forecasting in power management of a real-world trajectory-based application, achieving an 11.25% reduction in carbon emissions through predictive optimization of data center operations and controls.
Look, Listen, and Answer: Overcoming Biases for Audio-Visual Question Answering
Apr 18, 2024



Audio-Visual Question Answering (AVQA) is a complex multi-modal reasoning task, demanding intelligent systems to accurately respond to natural language queries based on audio-video input pairs. Nevertheless, prevalent AVQA approaches are prone to overlearning dataset biases, resulting in poor robustness. Furthermore, current datasets may not provide a precise diagnostic for these methods. To tackle these challenges, firstly, we propose a novel dataset, \textit{MUSIC-AVQA-R}, crafted in two steps: rephrasing questions within the test split of a public dataset (\textit{MUSIC-AVQA}) and subsequently introducing distribution shifts to split questions. The former leads to a large, diverse test space, while the latter results in a comprehensive robustness evaluation on rare, frequent, and overall questions. Secondly, we propose a robust architecture that utilizes a multifaceted cycle collaborative debiasing strategy to overcome bias learning. Experimental results show that this architecture achieves state-of-the-art performance on both datasets, especially obtaining a significant improvement of 9.68\% on the proposed dataset. Extensive ablation experiments are conducted on these two datasets to validate the effectiveness of the debiasing strategy. Additionally, we highlight the limited robustness of existing multi-modal QA methods through the evaluation on our dataset.
AR Visualization System for Ship Detection and Recognition Based on AI
Nov 21, 2023
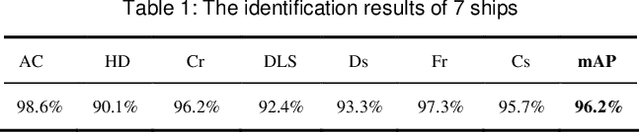
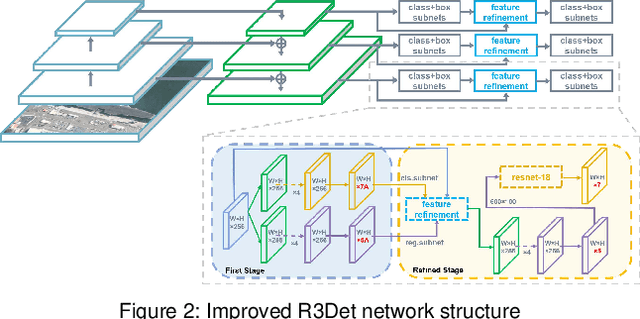
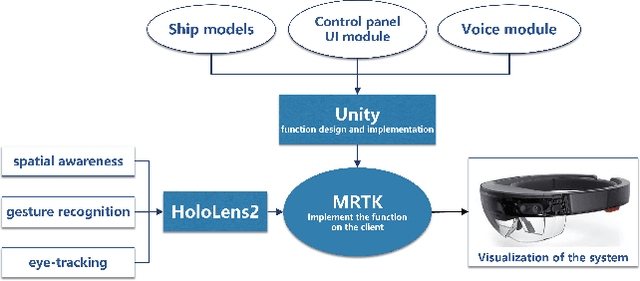
Augmented reality technology has been widely used in industrial design interaction, exhibition guide, information retrieval and other fields. The combination of artificial intelligence and augmented reality technology has also become a future development trend. This project is an AR visualization system for ship detection and recognition based on AI, which mainly includes three parts: artificial intelligence module, Unity development module and Hololens2AR module. This project is based on R3Det algorithm to complete the detection and recognition of ships in remote sensing images. The recognition rate of model detection trained on RTX 2080Ti can reach 96%. Then, the 3D model of the ship is obtained by ship categories and information and generated in the virtual scene. At the same time, voice module and UI interaction module are added. Finally, we completed the deployment of the project on Hololens2 through MRTK. The system realizes the fusion of computer vision and augmented reality technology, which maps the results of object detection to the AR field, and makes a brave step toward the future technological trend and intelligent application.
Adaptive loose optimization for robust question answering
May 06, 2023



Question answering methods are well-known for leveraging data bias, such as the language prior in visual question answering and the position bias in machine reading comprehension (extractive question answering). Current debiasing methods often come at the cost of significant in-distribution performance to achieve favorable out-of-distribution generalizability, while non-debiasing methods sacrifice a considerable amount of out-of-distribution performance in order to obtain high in-distribution performance. Therefore, it is challenging for them to deal with the complicated changing real-world situations. In this paper, we propose a simple yet effective novel loss function with adaptive loose optimization, which seeks to make the best of both worlds for question answering. Our main technical contribution is to reduce the loss adaptively according to the ratio between the previous and current optimization state on mini-batch training data. This loose optimization can be used to prevent non-debiasing methods from overlearning data bias while enabling debiasing methods to maintain slight bias learning. Experiments on the visual question answering datasets, including VQA v2, VQA-CP v1, VQA-CP v2, GQA-OOD, and the extractive question answering dataset SQuAD demonstrate that our approach enables QA methods to obtain state-of-the-art in- and out-of-distribution performance in most cases. The source code has been released publicly in \url{https://github.com/reml-group/ALO}.
Futures Quantitative Investment with Heterogeneous Continual Graph Neural Network
Mar 29, 2023
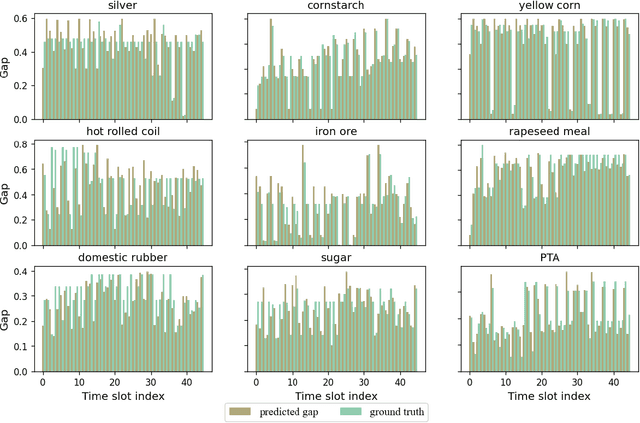
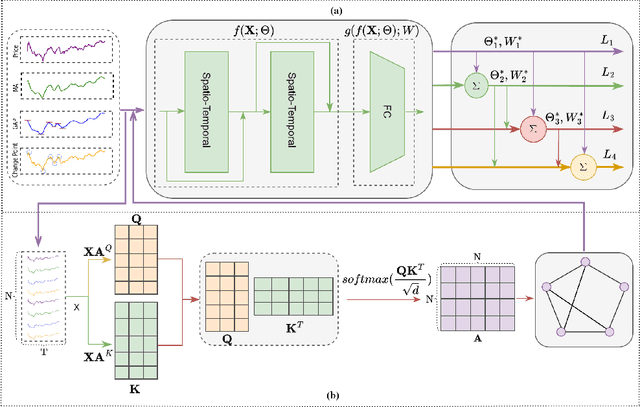
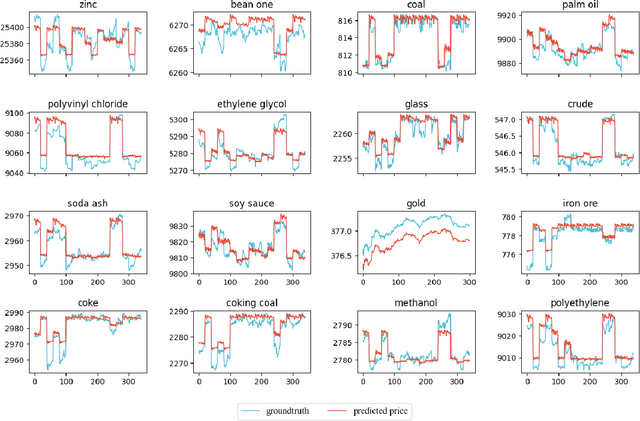
It is a challenging problem to predict trends of futures prices with traditional econometric models as one needs to consider not only futures' historical data but also correlations among different futures. Spatial-temporal graph neural networks (STGNNs) have great advantages in dealing with such kind of spatial-temporal data. However, we cannot directly apply STGNNs to high-frequency future data because future investors have to consider both the long-term and short-term characteristics when doing decision-making. To capture both the long-term and short-term features, we exploit more label information by designing four heterogeneous tasks: price regression, price moving average regression, price gap regression (within a short interval), and change-point detection, which involve both long-term and short-term scenes. To make full use of these labels, we train our model in a continual manner. Traditional continual GNNs define the gradient of prices as the parameter important to overcome catastrophic forgetting (CF). Unfortunately, the losses of the four heterogeneous tasks lie in different spaces. Hence it is improper to calculate the parameter importance with their losses. We propose to calculate parameter importance with mutual information between original observations and the extracted features. The empirical results based on 49 commodity futures demonstrate that our model has higher prediction performance on capturing long-term or short-term dynamic change.
Speaker Change Detection for Transformer Transducer ASR
Feb 16, 2023Speaker change detection (SCD) is an important feature that improves the readability of the recognized words from an automatic speech recognition (ASR) system by breaking the word sequence into paragraphs at speaker change points. Existing SCD solutions either require additional ensemble for the time based decisions and recognized word sequences, or implement a tight integration between ASR and SCD, limiting the potential optimum performance for both tasks. To address these issues, we propose a novel framework for the SCD task, where an additional SCD module is built on top of an existing Transformer Transducer ASR (TT-ASR) network. Two variants of the SCD network are explored in this framework that naturally estimate speaker change probability for each word, while allowing the ASR and SCD to have independent optimization scheme for the best performance. Experiments show that our methods can significantly improve the F1 score on LibriCSS and Microsoft call center data sets without ASR degradation, compared with a joint SCD and ASR baseline.