 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Adaptive One-Class Classifier Fusion with Dynamic $\ell$p-Norm Constraints for Robust Anomaly Detection
Nov 20, 2024


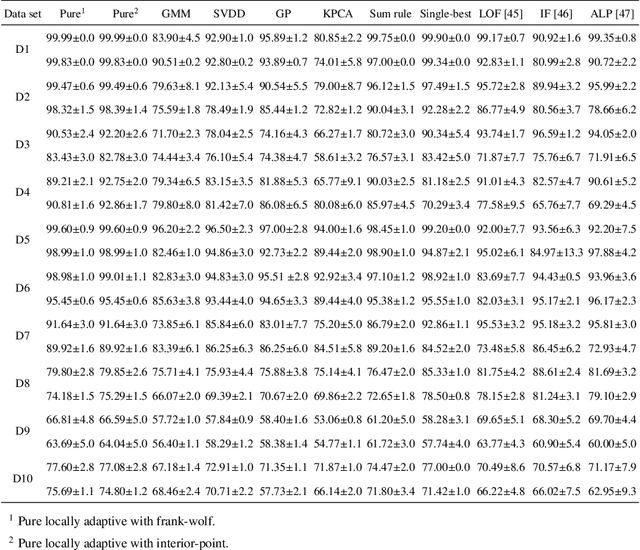
This paper presents a novel approach to one-class classifier fusion through locally adaptive learning with dynamic $\ell$p-norm constraints. We introduce a framework that dynamically adjusts fusion weights based on local data characteristics, addressing fundamental challenges in ensemble-based anomaly detection. Our method incorporates an interior-point optimization technique that significantly improves computational efficiency compared to traditional Frank-Wolfe approaches, achieving up to 19-fold speed improvements in complex scenarios. The framework is extensively evaluated on standard UCI benchmark datasets and specialized temporal sequence datasets, demonstrating superior performance across diverse anomaly types. Statistical validation through Skillings-Mack tests confirms our method's significant advantages over existing approaches, with consistent top rankings in both pure and non-pure learning scenarios. The framework's ability to adapt to local data patterns while maintaining computational efficiency makes it particularly valuable for real-time applications where rapid and accurate anomaly detection is crucial.
Interpretable Responsibility Sharing as a Heuristic for Task and Motion Planning
Sep 09, 2024
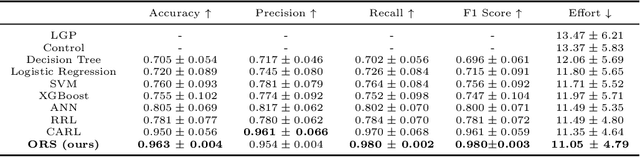

This article introduces a novel heuristic for Task and Motion Planning (TAMP) named Interpretable Responsibility Sharing (IRS), which enhances planning efficiency in domestic robots by leveraging human-constructed environments and inherent biases. Utilizing auxiliary objects (e.g., trays and pitchers), which are commonly found in household settings, IRS systematically incorporates these elements to simplify and optimize task execution. The heuristic is rooted in the novel concept of Responsibility Sharing (RS), where auxiliary objects share the task's responsibility with the embodied agent, dividing complex tasks into manageable sub-problems. This division not only reflects human usage patterns but also aids robots in navigating and manipulating within human spaces more effectively. By integrating Optimized Rule Synthesis (ORS) for decision-making, IRS ensures that the use of auxiliary objects is both strategic and context-aware, thereby improving the interpretability and effectiveness of robotic planning. Experiments conducted across various household tasks demonstrate that IRS significantly outperforms traditional methods by reducing the effort required in task execution and enhancing the overall decision-making process. This approach not only aligns with human intuitive methods but also offers a scalable solution adaptable to diverse domestic environments. Code is available at https://github.com/asyncs/IRS.
CUER: Corrected Uniform Experience Replay for Off-Policy Continuous Deep Reinforcement Learning Algorithms
Jun 13, 2024


The utilization of the experience replay mechanism enables agents to effectively leverage their experiences on several occasions. In previous studies, the sampling probability of the transitions was modified based on their relative significance. The process of reassigning sample probabilities for every transition in the replay buffer after each iteration is considered extremely inefficient. Hence, in order to enhance computing efficiency, experience replay prioritization algorithms reassess the importance of a transition as it is sampled. However, the relative importance of the transitions undergoes dynamic adjustments when the agent's policy and value function are iteratively updated. Furthermore, experience replay is a mechanism that retains the transitions generated by the agent's past policies, which could potentially diverge significantly from the agent's most recent policy. An increased deviation from the agent's most recent policy results in a greater frequency of off-policy updates, which has a negative impact on the agent's performance. In this paper, we develop a novel algorithm, Corrected Uniform Experience Replay (CUER), which stochastically samples the stored experience while considering the fairness among all other experiences without ignoring the dynamic nature of the transition importance by making sampled state distribution more on-policy. CUER provides promising improvements for off-policy continuous control algorithms in terms of sample efficiency, final performance, and stability of the policy during the training.
FViT-Grasp: Grasping Objects With Using Fast Vision Transformers
Nov 23, 2023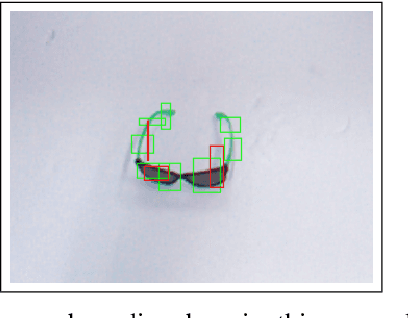
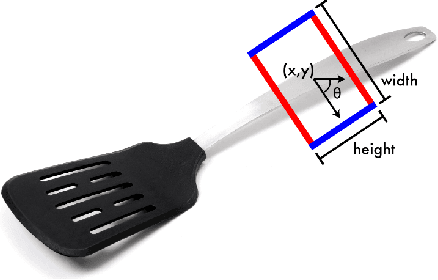
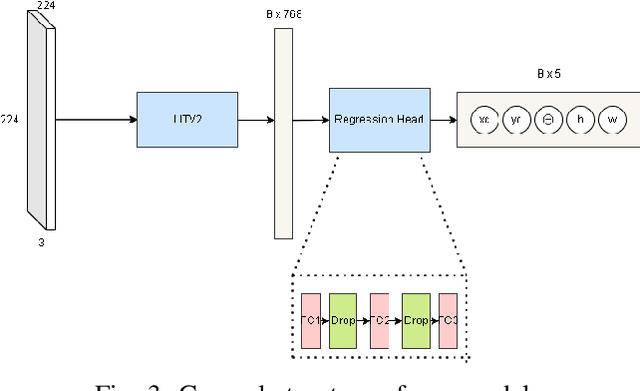
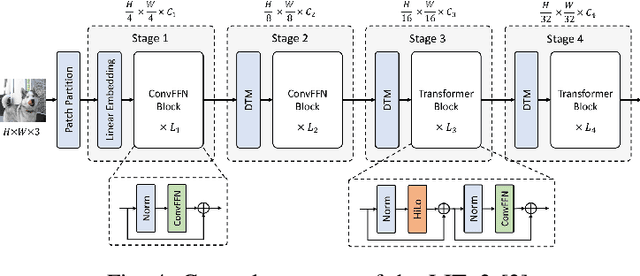
This study addresses the challenge of manipulation, a prominent issue in robotics. We have devised a novel methodology for swiftly and precisely identifying the optimal grasp point for a robot to manipulate an object. Our approach leverages a Fast Vision Transformer (FViT), a type of neural network designed for processing visual data and predicting the most suitable grasp location. Demonstrating state-of-the-art performance in terms of speed while maintaining a high level of accuracy, our method holds promise for potential deployment in real-time robotic grasping applications. We believe that this study provides a baseline for future research in vision-based robotic grasp applications. Its high speed and accuracy bring researchers closer to real-life applications.