 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Adaptive One-Class Classifier Fusion with Dynamic $\ell$p-Norm Constraints for Robust Anomaly Detection
Nov 20, 2024


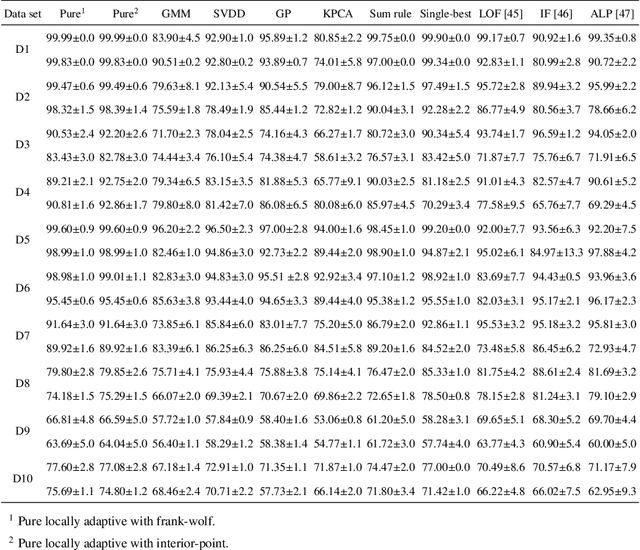
This paper presents a novel approach to one-class classifier fusion through locally adaptive learning with dynamic $\ell$p-norm constraints. We introduce a framework that dynamically adjusts fusion weights based on local data characteristics, addressing fundamental challenges in ensemble-based anomaly detection. Our method incorporates an interior-point optimization technique that significantly improves computational efficiency compared to traditional Frank-Wolfe approaches, achieving up to 19-fold speed improvements in complex scenarios. The framework is extensively evaluated on standard UCI benchmark datasets and specialized temporal sequence datasets, demonstrating superior performance across diverse anomaly types. Statistical validation through Skillings-Mack tests confirms our method's significant advantages over existing approaches, with consistent top rankings in both pure and non-pure learning scenarios. The framework's ability to adapt to local data patterns while maintaining computational efficiency makes it particularly valuable for real-time applications where rapid and accurate anomaly detection is crucial.
Lp-Norm Constrained One-Class Classifier Combination
Dec 25, 2023Classifier fusion is established as an effective methodology for boosting performance in different settings and one-class classification is no exception. In this study, we consider the one-class classifier fusion problem by modelling the sparsity/uniformity of the ensemble. To this end, we formulate a convex objective function to learn the weights in a linear ensemble model and impose a variable Lp-norm constraint on the weight vector. The vector-norm constraint enables the model to adapt to the intrinsic uniformity/sparsity of the ensemble in the space of base learners and acts as a (soft) classifier selection mechanism by shaping the relative magnitudes of fusion weights. Drawing on the Frank-Wolfe algorithm, we then present an effective approach to solve the formulated convex constrained optimisation problem efficiently. We evaluate the proposed one-class classifier combination approach on multiple data sets from diverse application domains and illustrate its merits in comparison to the existing approaches.
Unknown Face Presentation Attack Detection via Localised Learning of Multiple Kernels
Apr 22, 2022
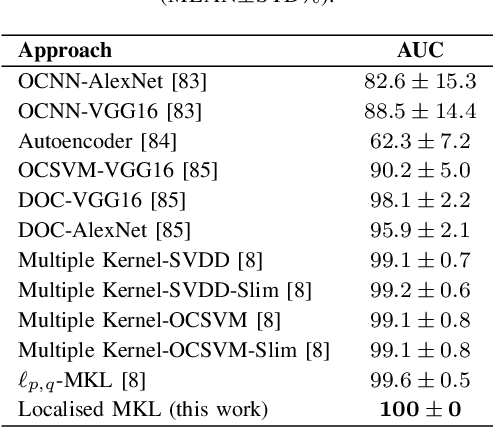


The paper studies face spoofing, a.k.a. presentation attack detection (PAD) in the demanding scenarios of unknown types of attack. While earlier studies have revealed the benefits of ensemble methods, and in particular, a multiple kernel learning approach to the problem, one limitation of such techniques is that they typically treat the entire observation space similarly and ignore any variability and local structure inherent to the data. This work studies this aspect of the face presentation attack detection problem in relation to multiple kernel learning in a one-class setting to benefit from intrinsic local structure in bona fide face samples. More concretely, inspired by the success of the one-class Fisher null formalism, we formulate a convex localised multiple kernel learning algorithm by imposing a joint matrix-norm constraint on the collection of local kernel weights and infer locally adaptive weights for zero-shot one-class unseen attack detection. We present a theoretical study of the proposed localised MKL algorithm using Rademacher complexities to characterise its generalisation capability and demonstrate the advantages of the proposed technique over some other options. An assessment of the proposed approach on general object image datasets illustrates its efficacy for abnormality and novelty detection while the results of the experiments on face PAD datasets verifies its potential in detecting unknown/unseen face presentation attacks.
$\ell_p$-Norm Multiple Kernel One-Class Fisher Null-Space
Aug 19, 2020
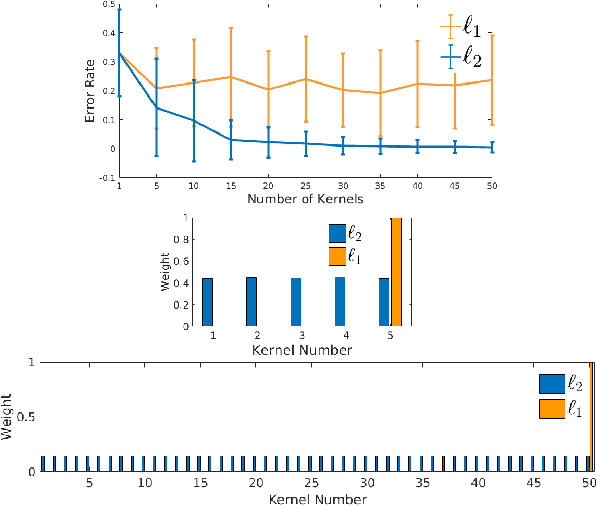
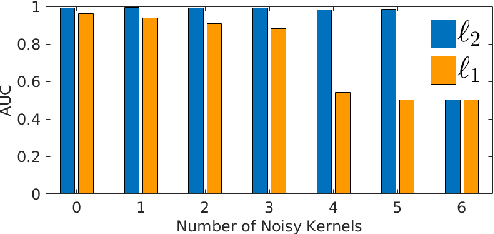
The paper addresses the multiple kernel learning (MKL) problem for one-class classification (OCC). For this purpose, based on the Fisher null-space one-class classification method, we present a multiple kernel learning algorithm where a general $\ell_p$-norm constraint ($p\geq1$) on kernel weights is considered. The proposed approach is then extended to learn several related one-class MKL problems jointly by constraining them to share common kernel weights. We pose the one-class MKL task as a min-max saddle point Lagrangian optimisation problem and propose an efficient alternating optimisation method to solve it. An extensive assessment of the proposed method on ten data sets from different application domains in one-class classification confirms its merits against the baseline and several other one-class multiple kernel learning methods.
Unseen Face Presentation Attack Detection Using Class-Specific Sparse One-Class Multiple Kernel Fusion Regression
Dec 31, 2019
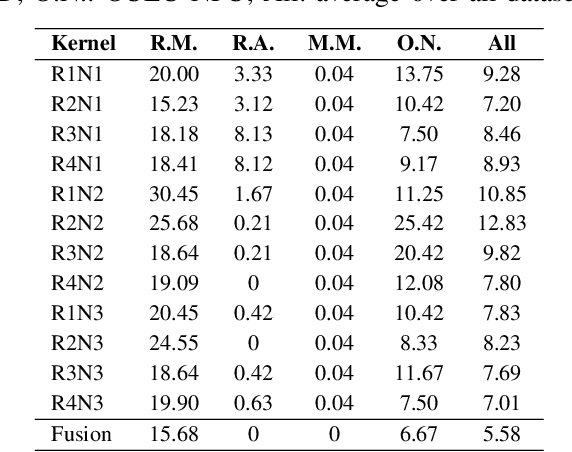

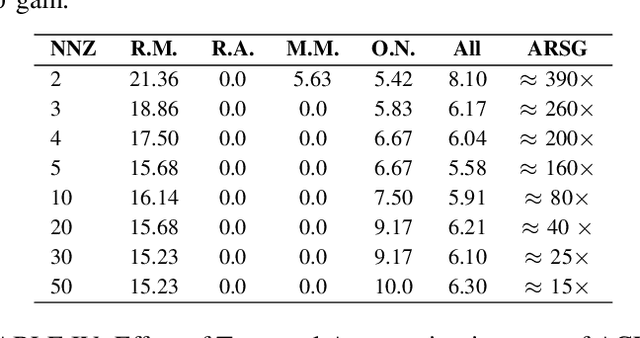
The paper addresses face presentation attack detection in the challenging conditions of an unseen attack scenario where the system is exposed to novel presentation attacks that were not present in the training step. For this purpose, a pure one-class face presentation attack detection approach based on kernel regression is developed which only utilises bona fide (genuine) samples for training. In the context of the proposed approach, a number of innovations, including multiple kernel fusion, client-specific modelling, sparse regularisation and probabilistic modelling of score distributions are introduced to improve the efficacy of the method. The results of experimental evaluations conducted on the OULU-NPU, Replay-Mobile, Replay-Attack and MSU-MFSD datasets illustrate that the proposed method compares very favourably with other methods operating in an unseen attack detection scenario while achieving very competitive performance to multi-class methods (benefiting from presentation attack data for training) despite using only bona fide samples for training.
Multi-Task Kernel Null-Space for One-Class Classification
May 22, 2019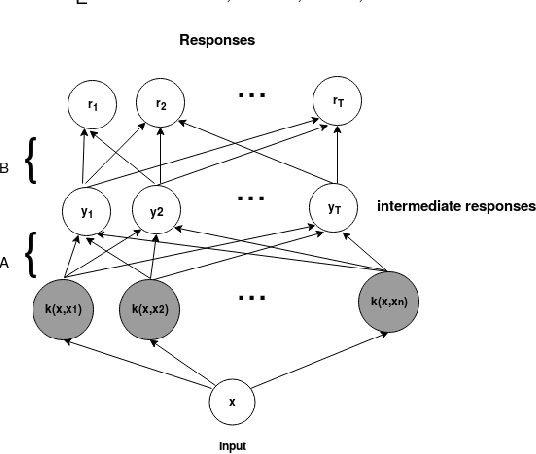
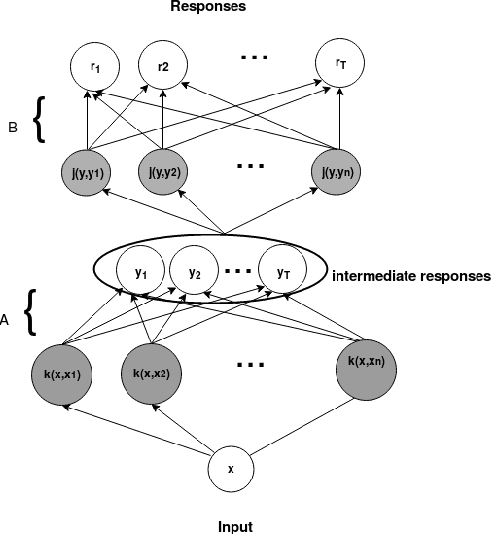

The one-class kernel spectral regression (OC-KSR), the regression-based formulation of the kernel null-space approach has been found to be an effective Fisher criterion-based methodology for one-class classification (OCC), achieving state-of-the-art performance in one-class classification while providing relatively high robustness against data corruption. This work extends the OC-KSR methodology to a multi-task setting where multiple one-class problems share information for improved performance. By viewing the multi-task structure learning problem as one of compositional function learning, first, the OC-KSR method is extended to learn multiple tasks' structure \textit{linearly} by posing it as an instantiation of the separable kernel learning problem in a vector-valued reproducing kernel Hilbert space where an output kernel encodes tasks' structure while another kernel captures input similarities. Next, a non-linear structure learning mechanism is proposed which captures multiple tasks' relationships \textit{non-linearly} via an output kernel. The non-linear structure learning method is then extended to a sparse setting where different tasks compete in an output composition mechanism, leading to a sparse non-linear structure among multiple problems. Through extensive experiments on different data sets, the merits of the proposed multi-task kernel null-space techniques are verified against the baseline as well as other existing multi-task one-class learning techniques.
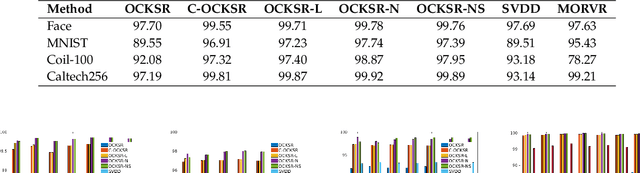
Robust One-Class Kernel Spectral Regression
Feb 06, 2019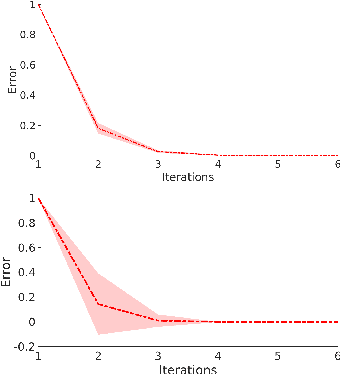
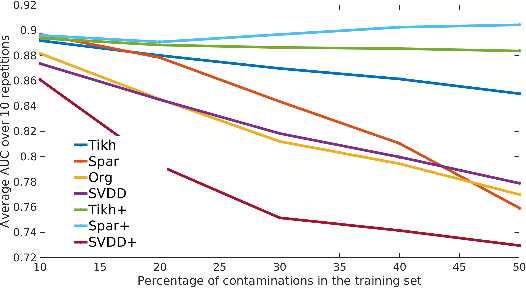
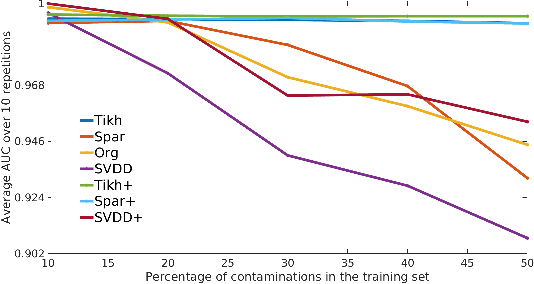
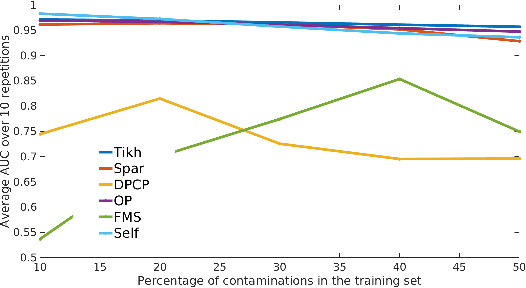
The kernel null-space technique and its regression-based formulation (called one-class kernel spectral regression, a.k.a. OC-KSR) is known to be an effective and computationally attractive one-class classification framework. Despite its outstanding performance, the applicability of kernel null-space method is limited due to its susceptibility to possible training data corruptions and inability to rank training observations according to their conformity with the model. This work addresses these shortcomings by studying the effect of regularising the solution of the null-space kernel Fisher methodology in the context of its regression-based formulation (OC-KSR). In this respect, first, the effect of a Tikhonov regularisation in the Hilbert space is analysed where the one-class learning problem in presence of contaminations in the training set is posed as a sensitivity analysis problem. Next, driven by the success of the sparse representation methodology, the effect of a sparsity regularisation on the solution is studied. For both alternative regularisation schemes, iterative algorithms are proposed which recursively update label confidences and rank training observations based on their fit with the model. Through extensive experiments conducted on different data sets, the proposed methodology is found to enhance robustness against contamination in the training set as compared with the baseline kernel null-space technique as well as other existing approaches in a one-class classification paradigm while providing the functionality to rank training samples effectively.
One-Class Kernel Spectral Regression for Outlier Detection
Aug 20, 2018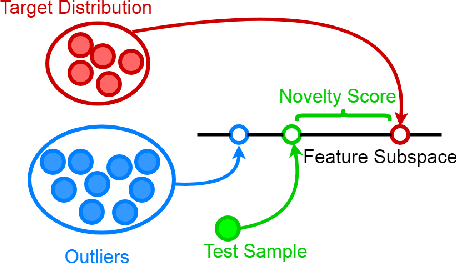
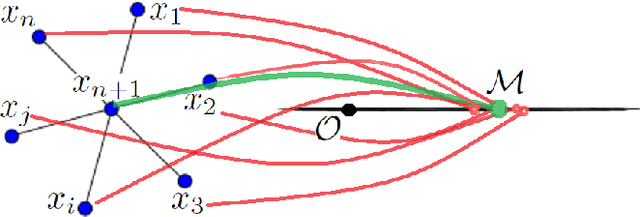
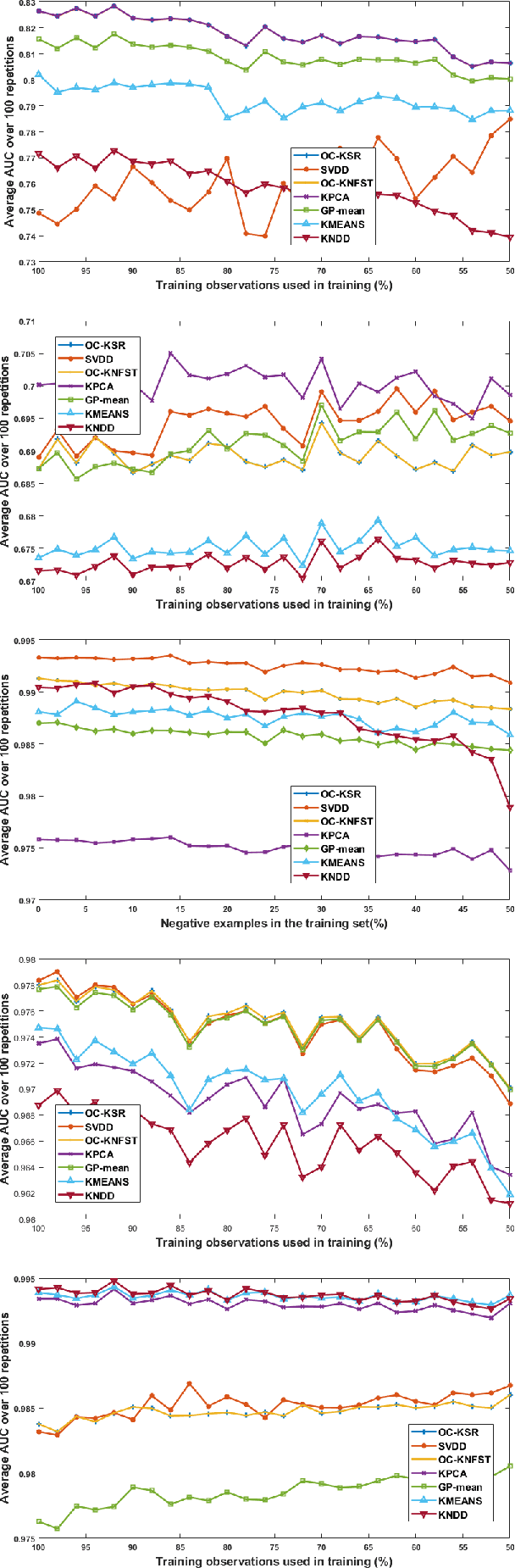
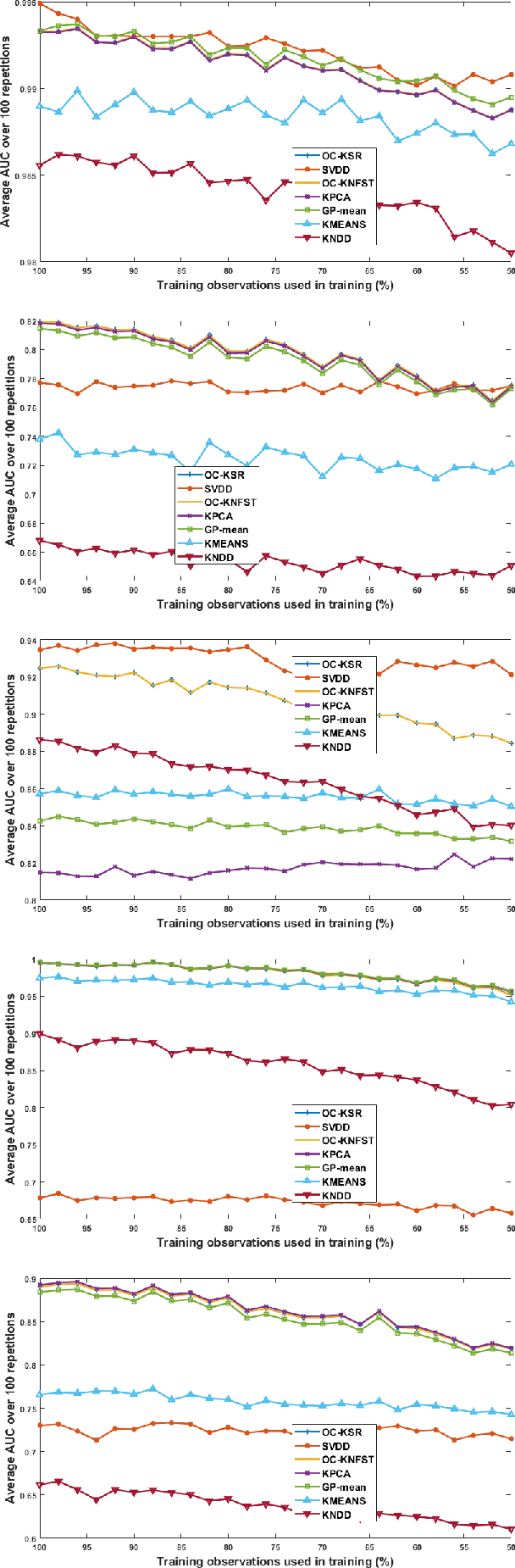
The paper introduces a new efficient nonlinear one-class classifier formulated as the Rayleigh quotient criterion optimisation. The method, operating in a reproducing kernel Hilbert subspace, minimises the scatter of target distribution along an optimal projection direction while at the same time keeping projections of positive observations distant from the mean of the negative class. We provide a graph embedding view of the problem which can then be solved efficiently using the spectral regression approach. In this sense, unlike previous similar methods which often require costly eigen-computations of dense matrices, the proposed approach casts the problem under consideration into a regression framework which is computationally more efficient. In particular, it is shown that the dominant complexity of the proposed method is the complexity of computing the kernel matrix. Additional appealing characteristics of the proposed one-class classifier are: 1-the ability to be trained in an incremental fashion (allowing for application in streaming data scenarios while also reducing the computational complexity in a non-streaming operation mode); 2-being unsupervised, but providing the option for refining the solution using negative training examples, when available; Last but not least, 3-the use of the kernel trick which facilitates a nonlinear mapping of the data into a high-dimensional feature space to seek better solutions.
Client-Specific Anomaly Detection for Face Presentation Attack Detection
Jul 02, 2018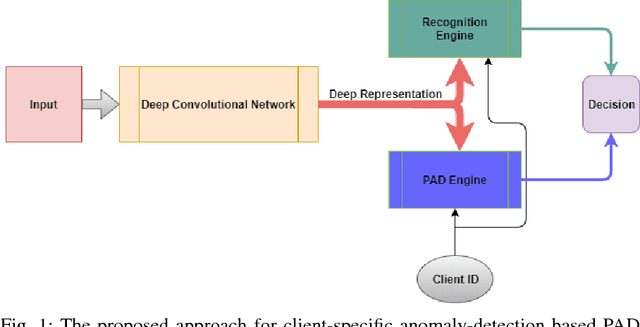
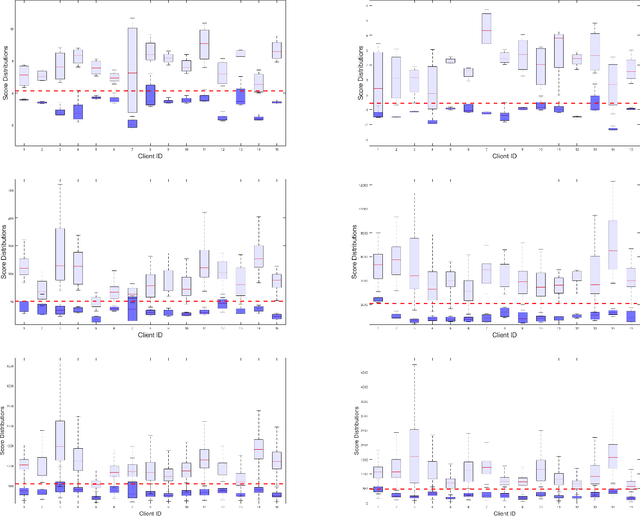
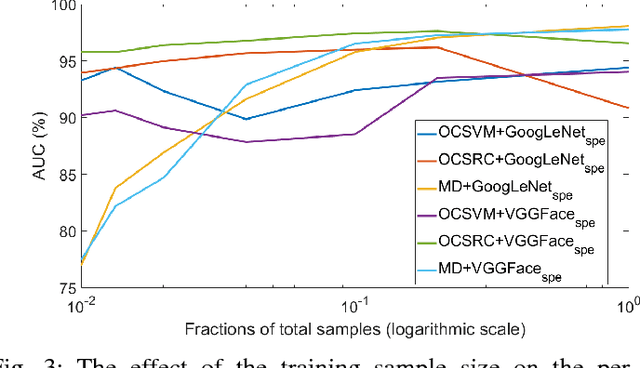
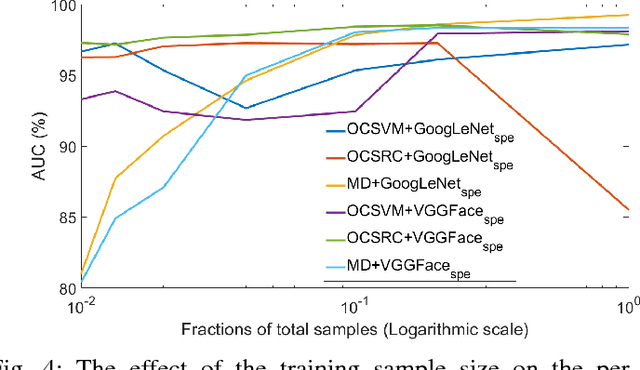
The one-class anomaly detection approach has previously been found to be effective in face presentation attack detection, especially in an \textit{unseen} attack scenario, where the system is exposed to novel types of attacks. This work follows the same anomaly-based formulation of the problem and analyses the merits of deploying \textit{client-specific} information for face spoofing detection. We propose training one-class client-specific classifiers (both generative and discriminative) using representations obtained from pre-trained deep convolutional neural networks. Next, based on subject-specific score distributions, a distinct threshold is set for each client, which is then used for decision making regarding a test query. Through extensive experiments using different one-class systems, it is shown that the use of client-specific information in a one-class anomaly detection formulation (both in model construction as well as decision threshold tuning) improves the performance significantly. In addition, it is demonstrated that the same set of deep convolutional features used for the recognition purposes is effective for face presentation attack detection in the class-specific one-class anomaly detection paradigm.