 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Spurious Correlations with Memorization-Guided Dataset De-Biasing
Jun 01, 2026Real-world datasets often contain spurious correlations that are not causally related to the target label. When such correlations dominate the majority of training samples, models tend to rely on them, leading to misclassification of minority samples that do not exhibit the same spurious patterns. While a potential approach is to select subsets of data to better represent the minority samples, this may require access to group labels, which are typically unknown. Furthermore, as we demonstrate, widely used sample scoring functions in the invariant subset or coreset selection literature largely depend on spurious features and therefore fail to accurately capture the importance or difficulty of core, causally relevant features. Accordingly, we propose to mitigate spurious correlations by developing a two-stage sample scoring function that disentangles the learning dynamics of core and spurious features and evaluates their difficulty separately. Based on our proposed metric, we introduce a new algorithm to find and prioritize informative samples both with and without spurious correlations. Extensive experiments demonstrate that a standard ERM model trained on our selected samples achieves superior performance compared to state-of-the-art debiasing techniques, while requiring as little as 10\% of the original training data.
Hybrid State Space-based Learning for Sequential Data Prediction with Joint Optimization
Sep 19, 2023We investigate nonlinear prediction/regression in an online setting and introduce a hybrid model that effectively mitigates, via a joint mechanism through a state space formulation, the need for domain-specific feature engineering issues of conventional nonlinear prediction models and achieves an efficient mix of nonlinear and linear components. In particular, we use recursive structures to extract features from raw sequential sequences and a traditional linear time series model to deal with the intricacies of the sequential data, e.g., seasonality, trends. The state-of-the-art ensemble or hybrid models typically train the base models in a disjoint manner, which is not only time consuming but also sub-optimal due to the separation of modeling or independent training. In contrast, as the first time in the literature, we jointly optimize an enhanced recurrent neural network (LSTM) for automatic feature extraction from raw data and an ARMA-family time series model (SARIMAX) for effectively addressing peculiarities associated with time series data. We achieve this by introducing novel state space representations for the base models, which are then combined to provide a full state space representation of the hybrid or the ensemble. Hence, we are able to jointly optimize both models in a single pass via particle filtering, for which we also provide the update equations. The introduced architecture is generic so that one can use other recurrent architectures, e.g., GRUs, traditional time series-specific models, e.g., ETS or other optimization methods, e.g., EKF, UKF. Due to such novel combination and joint optimization, we demonstrate significant improvements in widely publicized real life competition datasets. We also openly share our code for further research and replicability of our results.
Context-Aware Ensemble Learning for Time Series
Nov 30, 2022



We investigate ensemble methods for prediction in an online setting. Unlike all the literature in ensembling, for the first time, we introduce a new approach using a meta learner that effectively combines the base model predictions via using a superset of the features that is the union of the base models' feature vectors instead of the predictions themselves. Here, our model does not use the predictions of the base models as inputs to a machine learning algorithm, but choose the best possible combination at each time step based on the state of the problem. We explore three different constraint spaces for the ensembling of the base learners that linearly combines the base predictions, which are convex combinations where the components of the ensembling vector are all nonnegative and sum up to 1; affine combinations where the weight vector components are required to sum up to 1; and the unconstrained combinations where the components are free to take any real value. The constraints are both theoretically analyzed under known statistics and integrated into the learning procedure of the meta learner as a part of the optimization in an automated manner. To show the practical efficiency of the proposed method, we employ a gradient-boosted decision tree and a multi-layer perceptron separately as the meta learners. Our framework is generic so that one can use other machine learning architectures as the ensembler as long as they allow for a custom differentiable loss for minimization. We demonstrate the learning behavior of our algorithm on synthetic data and the significant performance improvements over the conventional methods over various real life datasets, extensively used in the well-known data competitions. Furthermore, we openly share the source code of the proposed method to facilitate further research and comparison.
Semi-Automatic Video Annotation For Object Detection
Jan 24, 2021
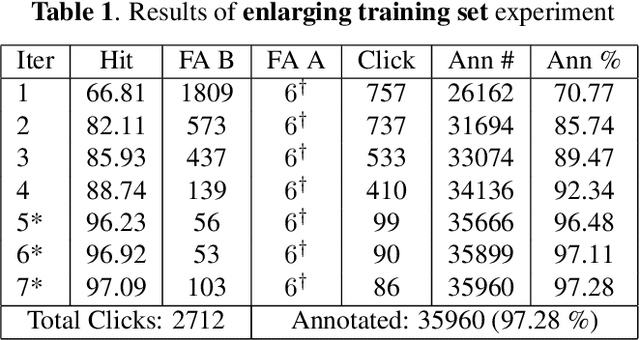


In this study, a semi-automatic video annotation method is proposed which utilizes temporal information to eliminate false-positives with a tracking-by-detection approach by employing multiple hypothesis tracking (MHT). MHT method automatically forms tracklets which are confirmed by human operators to enlarge the training set. A novel incremental learning approach helps to annotate videos in an iterative way. The experiments performed on AUTH Multidrone Dataset reveals that the annotation workload can be reduced up to 96% by the proposed approach.