 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Hard Example Mining Approach for Single Shot Object Detectors
Feb 26, 2022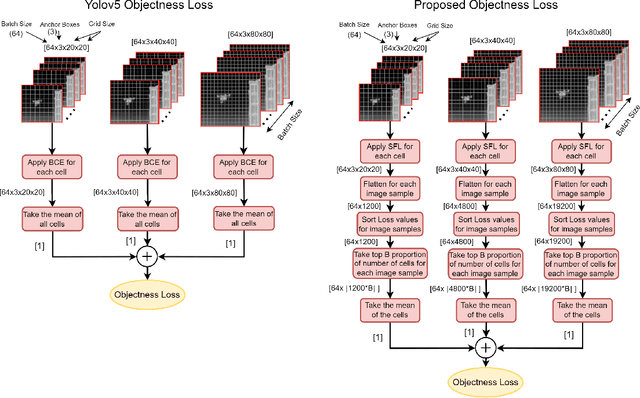
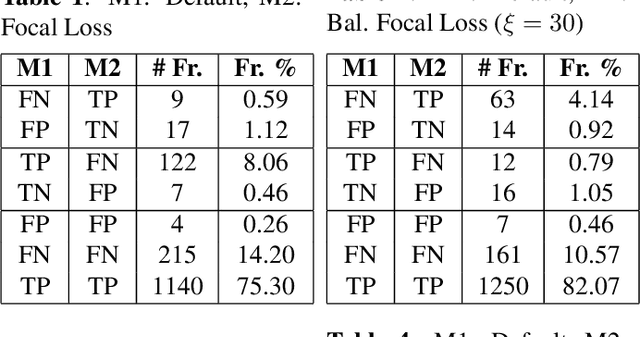


Hard example mining methods generally improve the performance of the object detectors, which suffer from imbalanced training sets. In this work, two existing hard example mining approaches (LRM and focal loss, FL) are adapted and combined in a state-of-the-art real-time object detector, YOLOv5. The effectiveness of the proposed approach for improving the performance on hard examples is extensively evaluated. The proposed method increases mAP by 3% compared to using the original loss function and around 1-2% compared to using the hard-mining methods (LRM or FL) individually on 2021 Anti-UAV Challenge Dataset.
Effect of Parameter Optimization on Classical and Learning-based Image Matching Methods
Aug 28, 2021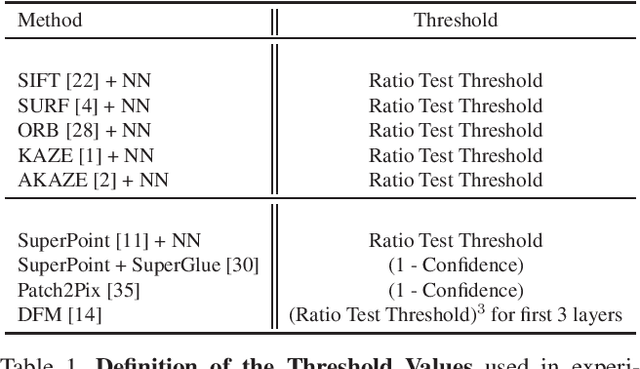


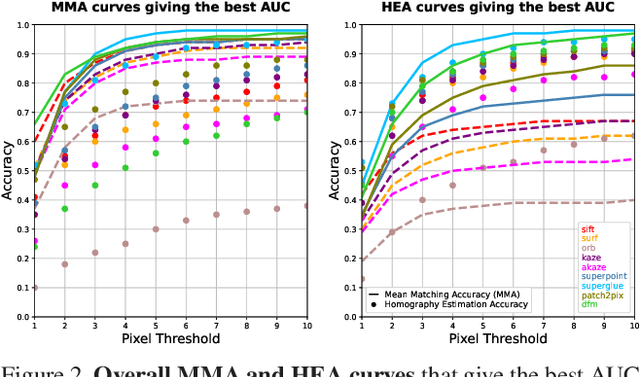
Deep learning-based image matching methods are improved significantly during the recent years. Although these methods are reported to outperform the classical techniques, the performance of the classical methods is not examined in detail. In this study, we compare classical and learning-based methods by employing mutual nearest neighbor search with ratio test and optimizing the ratio test threshold to achieve the best performance on two different performance metrics. After a fair comparison, the experimental results on HPatches dataset reveal that the performance gap between classical and learning-based methods is not that significant. Throughout the experiments, we demonstrated that SuperGlue is the state-of-the-art technique for the image matching problem on HPatches dataset. However, if a single parameter, namely ratio test threshold, is carefully optimized, a well-known traditional method SIFT performs quite close to SuperGlue and even outperforms in terms of mean matching accuracy (MMA) under 1 and 2 pixel thresholds. Moreover, a recent approach, DFM, which only uses pre-trained VGG features as descriptors and ratio test, is shown to outperform most of the well-trained learning-based methods. Therefore, we conclude that the parameters of any classical method should be analyzed carefully before comparing against a learning-based technique.
DFM: A Performance Baseline for Deep Feature Matching
Jun 14, 2021



A novel image matching method is proposed that utilizes learned features extracted by an off-the-shelf deep neural network to obtain a promising performance. The proposed method uses pre-trained VGG architecture as a feature extractor and does not require any additional training specific to improve matching. Inspired by well-established concepts in the psychology area, such as the Mental Rotation paradigm, an initial warping is performed as a result of a preliminary geometric transformation estimate. These estimates are simply based on dense matching of nearest neighbors at the terminal layer of VGG network outputs of the images to be matched. After this initial alignment, the same approach is repeated again between reference and aligned images in a hierarchical manner to reach a good localization and matching performance. Our algorithm achieves 0.57 and 0.80 overall scores in terms of Mean Matching Accuracy (MMA) for 1 pixel and 2 pixels thresholds respectively on Hpatches dataset, which indicates a better performance than the state-of-the-art.
Semi-Automatic Video Annotation For Object Detection
Jan 24, 2021
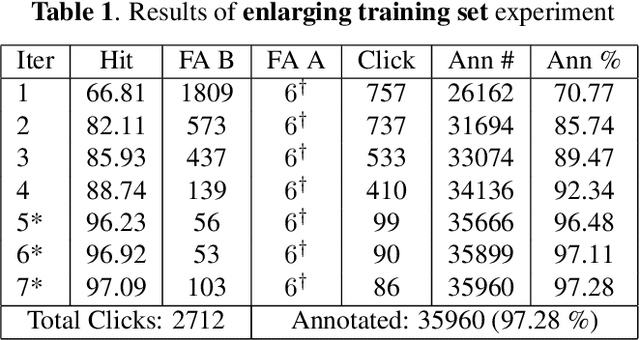


In this study, a semi-automatic video annotation method is proposed which utilizes temporal information to eliminate false-positives with a tracking-by-detection approach by employing multiple hypothesis tracking (MHT). MHT method automatically forms tracklets which are confirmed by human operators to enlarge the training set. A novel incremental learning approach helps to annotate videos in an iterative way. The experiments performed on AUTH Multidrone Dataset reveals that the annotation workload can be reduced up to 96% by the proposed approach.
Effect of Annotation Errors on Drone Detection with YOLOv3
Apr 14, 2020



Following the recent advances in deep networks, object detection and tracking algorithms with deep learning backbones have been improved significantly; however, this rapid development resulted in the necessity of large amounts of annotated labels. Even if the details of such semi-automatic annotation processes for most of these datasets are not known precisely, especially for the video annotations, some automated labeling processes are usually employed. Unfortunately, such approaches might result with erroneous annotations. In this work, different types of annotation errors for object detection problem are simulated and the performance of a popular state-of-the-art object detector, YOLOv3, with erroneous annotations during training and testing stages is examined. Moreover, some inevitable annotation errors in CVPR-2020 Anti-UAV Challenge dataset is also examined in this manner, while proposing a solution to correct such annotation errors of this valuable data set.