 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Based Meta Learning of Critics for Policy Gradients
Paper and Code
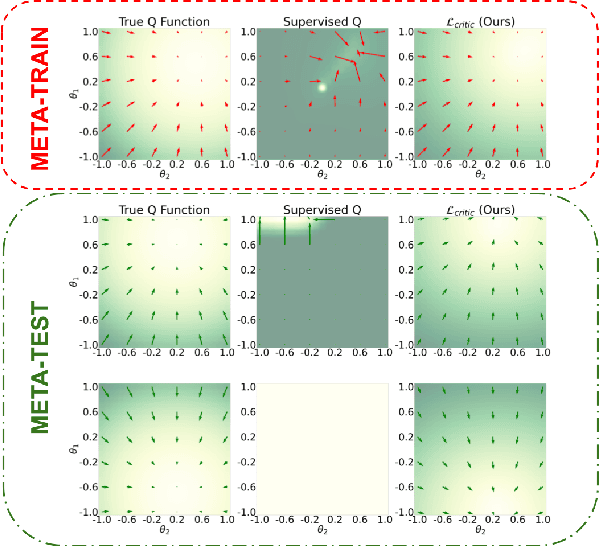
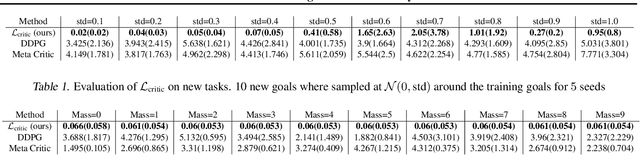
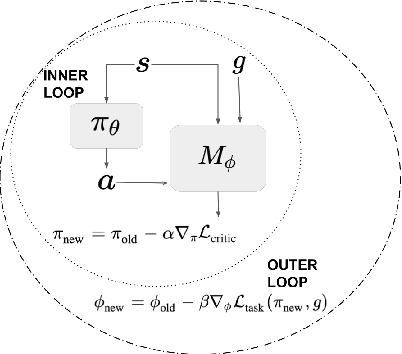
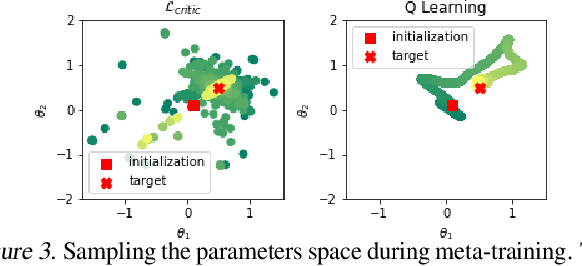
Being able to seamlessly generalize across different tasks is fundamental for robots to act in our world. However, learning representations that generalize quickly to new scenarios is still an open research problem in reinforcement learning. In this paper we present a framework to meta-learn the critic for gradient-based policy learning. Concretely, we propose a model-based bi-level optimization algorithm that updates the critics parameters such that the policy that is learned with the updated critic gets closer to solving the meta-training tasks. We illustrate that our algorithm leads to learned critics that resemble the ground truth Q function for a given task. Finally, after meta-training, the learned critic can be used to learn new policies for new unseen task and environment settings via model-free policy gradient optimization, without requiring a model. We present results that show the generalization capabilities of our learned critic to new tasks and dynamics when used to learn a new policy in a new scenario.