 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Spectral Control of Partially Observed Linear Dynamical Systems
May 27, 2025We propose a new method for the problem of controlling linear dynamical systems under partial observation and adversarial disturbances. Our new algorithm, Double Spectral Control (DSC), matches the best known regret guarantees while exponentially improving runtime complexity over previous approaches in its dependence on the system's stability margin. Our key innovation is a two-level spectral approximation strategy, leveraging double convolution with a universal basis of spectral filters, enabling efficient and accurate learning of the best linear dynamical controllers.
A New Approach to Controlling Linear Dynamical Systems
Apr 04, 2025


We propose a new method for controlling linear dynamical systems under adversarial disturbances and cost functions. Our algorithm achieves a running time that scales polylogarithmically with the inverse of the stability margin, improving upon prior methods with polynomial dependence maintaining the same regret guarantees. The technique, which may be of independent interest, is based on a novel convex relaxation that approximates linear control policies using spectral filters constructed from the eigenvectors of a specific Hankel matrix.
How Uniform Random Weights Induce Non-uniform Bias: Typical Interpolating Neural Networks Generalize with Narrow Teachers
Feb 09, 2024
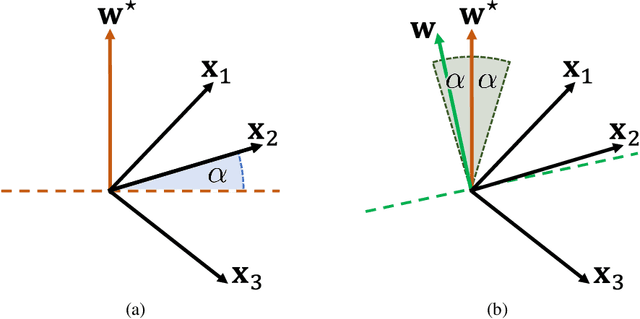
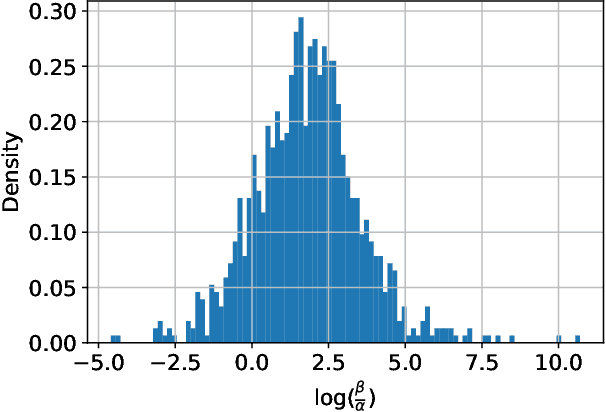
Background. A main theoretical puzzle is why over-parameterized Neural Networks (NNs) generalize well when trained to zero loss (i.e., so they interpolate the data). Usually, the NN is trained with Stochastic Gradient Descent (SGD) or one of its variants. However, recent empirical work examined the generalization of a random NN that interpolates the data: the NN was sampled from a seemingly uniform prior over the parameters, conditioned on that the NN perfectly classifying the training set. Interestingly, such a NN sample typically generalized as well as SGD-trained NNs. Contributions. We prove that such a random NN interpolator typically generalizes well if there exists an underlying narrow ``teacher NN" that agrees with the labels. Specifically, we show that such a `flat' prior over the NN parametrization induces a rich prior over the NN functions, due to the redundancy in the NN structure. In particular, this creates a bias towards simpler functions, which require less relevant parameters to represent -- enabling learning with a sample complexity approximately proportional to the complexity of the teacher (roughly, the number of non-redundant parameters), rather than the student's.
Deconstructing Data Reconstruction: Multiclass, Weight Decay and General Losses
Jul 04, 2023
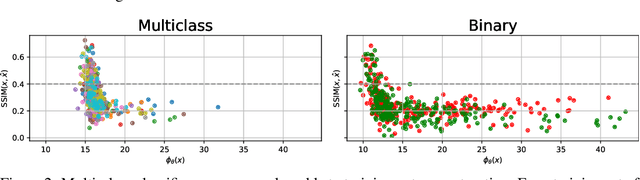
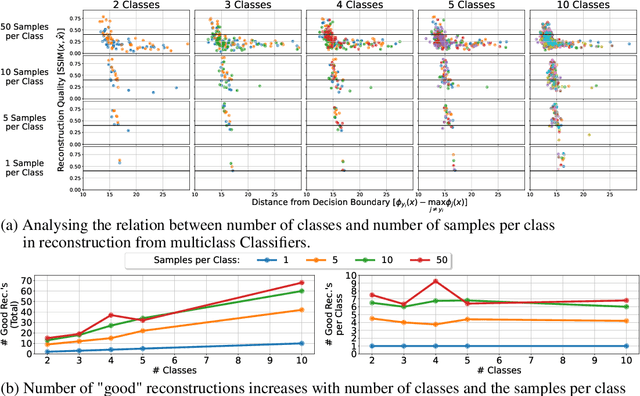
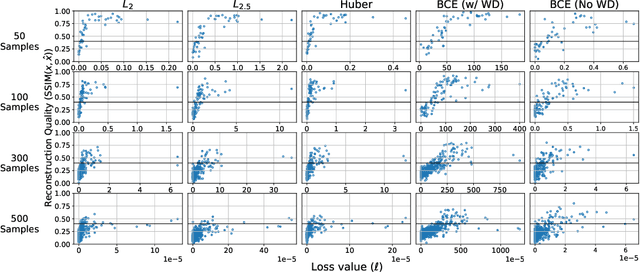
Memorization of training data is an active research area, yet our understanding of the inner workings of neural networks is still in its infancy. Recently, Haim et al. (2022) proposed a scheme to reconstruct training samples from multilayer perceptron binary classifiers, effectively demonstrating that a large portion of training samples are encoded in the parameters of such networks. In this work, we extend their findings in several directions, including reconstruction from multiclass and convolutional neural networks. We derive a more general reconstruction scheme which is applicable to a wider range of loss functions such as regression losses. Moreover, we study the various factors that contribute to networks' susceptibility to such reconstruction schemes. Intriguingly, we observe that using weight decay during training increases reconstructability both in terms of quantity and quality. Additionally, we examine the influence of the number of neurons relative to the number of training samples on the reconstructability.
Continual Learning in Linear Classification on Separable Data
Jun 06, 2023We analyze continual learning on a sequence of separable linear classification tasks with binary labels. We show theoretically that learning with weak regularization reduces to solving a sequential max-margin problem, corresponding to a special case of the Projection Onto Convex Sets (POCS) framework. We then develop upper bounds on the forgetting and other quantities of interest under various settings with recurring tasks, including cyclic and random orderings of tasks. We discuss several practical implications to popular training practices like regularization scheduling and weighting. We point out several theoretical differences between our continual classification setting and a recently studied continual regression setting.
Reconstructing Training Data from Multiclass Neural Networks
May 05, 2023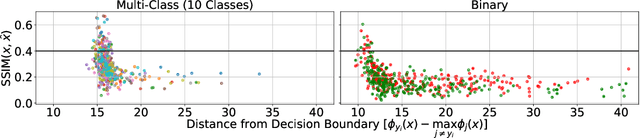
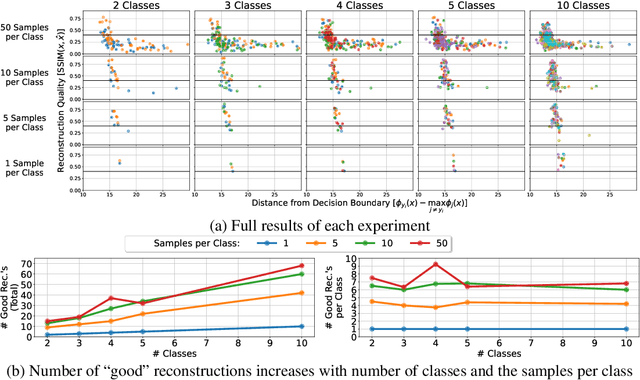
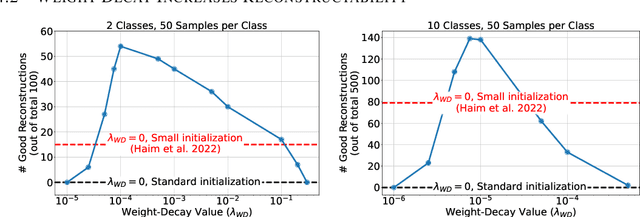
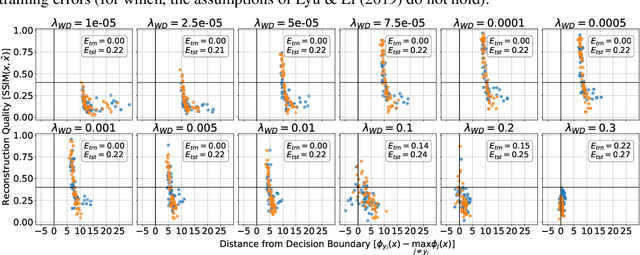
Reconstructing samples from the training set of trained neural networks is a major privacy concern. Haim et al. (2022) recently showed that it is possible to reconstruct training samples from neural network binary classifiers, based on theoretical results about the implicit bias of gradient methods. In this work, we present several improvements and new insights over this previous work. As our main improvement, we show that training-data reconstruction is possible in the multi-class setting and that the reconstruction quality is even higher than in the case of binary classification. Moreover, we show that using weight-decay during training increases the vulnerability to sample reconstruction. Finally, while in the previous work the training set was of size at most $1000$ from $10$ classes, we show preliminary evidence of the ability to reconstruct from a model trained on $5000$ samples from $100$ classes.