 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemperature is All You Need for Generalization in Langevin Dynamics and other Markov Processes
May 25, 2025



We analyze the generalization gap (gap between the training and test errors) when training a potentially over-parametrized model using a Markovian stochastic training algorithm, initialized from some distribution $\theta_0 \sim p_0$. We focus on Langevin dynamics with a positive temperature $\beta^{-1}$, i.e. gradient descent on a training loss $L$ with infinitesimal step size, perturbed with $\beta^{-1}$-variances Gaussian noise, and lightly regularized or bounded. There, we bound the generalization gap, at any time during training, by $\sqrt{(\beta\mathbb{E} L (\theta_0) + \log(1/\delta))/N}$ with probability $1-\delta$ over the dataset, where $N$ is the sample size, and $\mathbb{E} L (\theta_0) =O(1)$ with standard initialization scaling. In contrast to previous guarantees, we have no dependence on either training time or reliance on mixing, nor a dependence on dimensionality, gradient norms, or any other properties of the loss or model. This guarantee follows from a general analysis of any Markov process-based training that has a Gibbs-style stationary distribution. The proof is surprisingly simple, once we observe that the marginal distribution divergence from initialization remains bounded, as implied by a generalized second law of thermodynamics.
Provable Tempered Overfitting of Minimal Nets and Typical Nets
Oct 24, 2024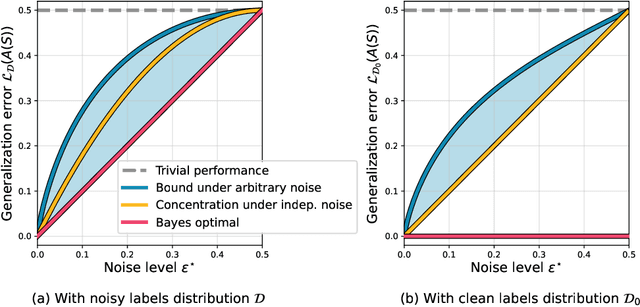
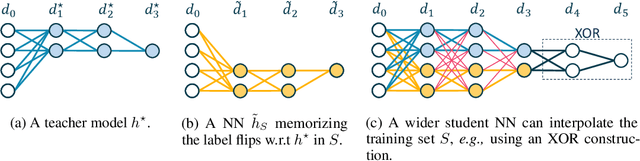
We study the overfitting behavior of fully connected deep Neural Networks (NNs) with binary weights fitted to perfectly classify a noisy training set. We consider interpolation using both the smallest NN (having the minimal number of weights) and a random interpolating NN. For both learning rules, we prove overfitting is tempered. Our analysis rests on a new bound on the size of a threshold circuit consistent with a partial function. To the best of our knowledge, ours are the first theoretical results on benign or tempered overfitting that: (1) apply to deep NNs, and (2) do not require a very high or very low input dimension.
How Uniform Random Weights Induce Non-uniform Bias: Typical Interpolating Neural Networks Generalize with Narrow Teachers
Feb 09, 2024
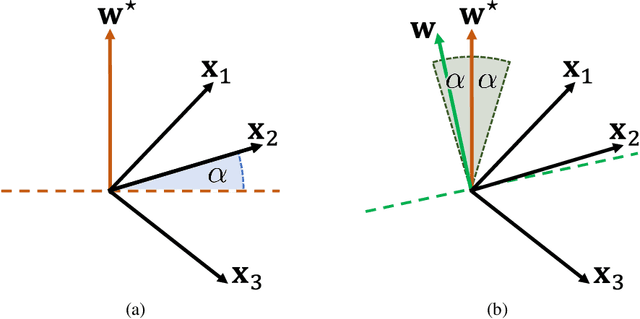
Background. A main theoretical puzzle is why over-parameterized Neural Networks (NNs) generalize well when trained to zero loss (i.e., so they interpolate the data). Usually, the NN is trained with Stochastic Gradient Descent (SGD) or one of its variants. However, recent empirical work examined the generalization of a random NN that interpolates the data: the NN was sampled from a seemingly uniform prior over the parameters, conditioned on that the NN perfectly classifying the training set. Interestingly, such a NN sample typically generalized as well as SGD-trained NNs. Contributions. We prove that such a random NN interpolator typically generalizes well if there exists an underlying narrow ``teacher NN" that agrees with the labels. Specifically, we show that such a `flat' prior over the NN parametrization induces a rich prior over the NN functions, due to the redundancy in the NN structure. In particular, this creates a bias towards simpler functions, which require less relevant parameters to represent -- enabling learning with a sample complexity approximately proportional to the complexity of the teacher (roughly, the number of non-redundant parameters), rather than the student's.