 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Models Know What's Important, and Encode It in Their Activations
Apr 20, 2026Language models often solve complex tasks by generating long reasoning chains, consisting of many steps with varying importance. While some steps are crucial for generating the final answer, others are removable. Determining which steps matter most, and why, remains an open question central to understanding how models process reasoning. We investigate if this question is best approached through model internals or through tokens of the reasoning chain itself. We find that model activations contain more information than tokens for identifying important reasoning steps. Crucially, by training probes on model activations to predict importance, we show that models encode an internal representation of step importance, even prior to the generation of subsequent steps. This internal representation of importance generalizes across models, is distributed across layers, and does not correlate with surface-level features, such as a step's relative position or its length. Our findings suggest that analyzing activations can reveal aspects of reasoning that surface-level approaches fundamentally miss, indicating that reasoning analyses should look into model internals.
Induction Meets Biology: Mechanisms of Repeat Detection in Protein Language Models
Feb 26, 2026Protein sequences are abundant in repeating segments, both as exact copies and as approximate segments with mutations. These repeats are important for protein structure and function, motivating decades of algorithmic work on repeat identification. Recent work has shown that protein language models (PLMs) identify repeats, by examining their behavior in masked-token prediction. To elucidate their internal mechanisms, we investigate how PLMs detect both exact and approximate repeats. We find that the mechanism for approximate repeats functionally subsumes that of exact repeats. We then characterize this mechanism, revealing two main stages: PLMs first build feature representations using both general positional attention heads and biologically specialized components, such as neurons that encode amino-acid similarity. Then, induction heads attend to aligned tokens across repeated segments, promoting the correct answer. Our results reveal how PLMs solve this biological task by combining language-based pattern matching with specialized biological knowledge, thereby establishing a basis for studying more complex evolutionary processes in PLMs.
Same Task, Different Circuits: Disentangling Modality-Specific Mechanisms in VLMs
Jun 11, 2025

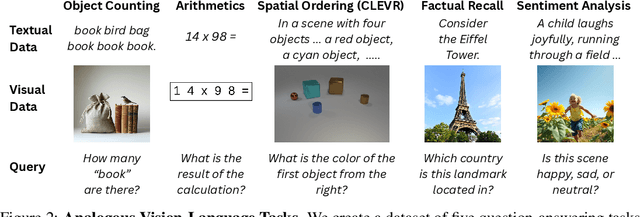
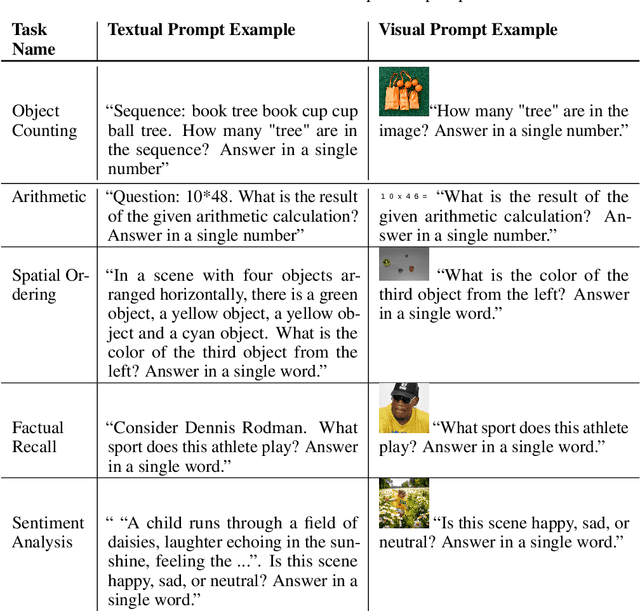
Vision-Language models (VLMs) show impressive abilities to answer questions on visual inputs (e.g., counting objects in an image), yet demonstrate higher accuracies when performing an analogous task on text (e.g., counting words in a text). We investigate this accuracy gap by identifying and comparing the \textit{circuits} - the task-specific computational sub-graphs - in different modalities. We show that while circuits are largely disjoint between modalities, they implement relatively similar functionalities: the differences lie primarily in processing modality-specific data positions (an image or a text sequence). Zooming in on the image data representations, we observe they become aligned with the higher-performing analogous textual representations only towards later layers, too late in processing to effectively influence subsequent positions. To overcome this, we patch the representations of visual data tokens from later layers back into earlier layers. In experiments with multiple tasks and models, this simple intervention closes a third of the performance gap between the modalities, on average. Our analysis sheds light on the multi-modal performance gap in VLMs and suggests a training-free approach for reducing it.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics
Oct 28, 2024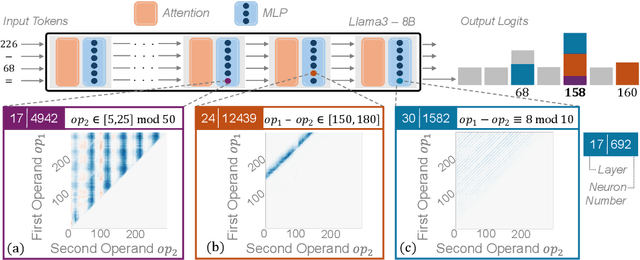
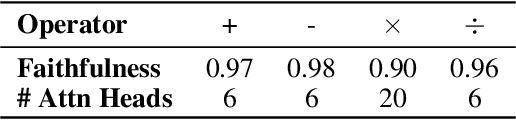
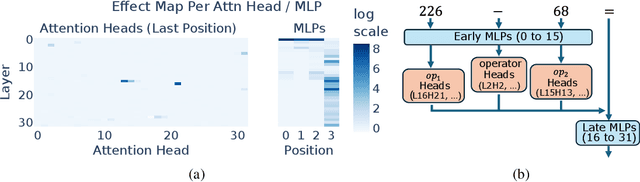

Do large language models (LLMs) solve reasoning tasks by learning robust generalizable algorithms, or do they memorize training data? To investigate this question, we use arithmetic reasoning as a representative task. Using causal analysis, we identify a subset of the model (a circuit) that explains most of the model's behavior for basic arithmetic logic and examine its functionality. By zooming in on the level of individual circuit neurons, we discover a sparse set of important neurons that implement simple heuristics. Each heuristic identifies a numerical input pattern and outputs corresponding answers. We hypothesize that the combination of these heuristic neurons is the mechanism used to produce correct arithmetic answers. To test this, we categorize each neuron into several heuristic types-such as neurons that activate when an operand falls within a certain range-and find that the unordered combination of these heuristic types is the mechanism that explains most of the model's accuracy on arithmetic prompts. Finally, we demonstrate that this mechanism appears as the main source of arithmetic accuracy early in training. Overall, our experimental results across several LLMs show that LLMs perform arithmetic using neither robust algorithms nor memorization; rather, they rely on a "bag of heuristics".
Deconstructing Data Reconstruction: Multiclass, Weight Decay and General Losses
Jul 04, 2023
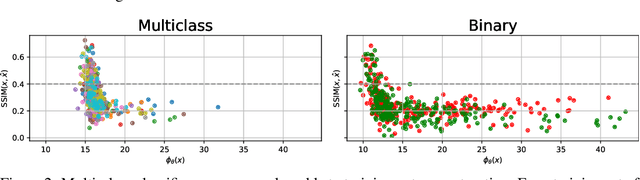
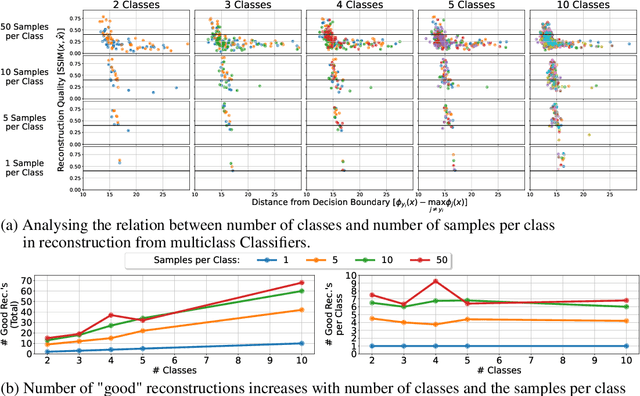
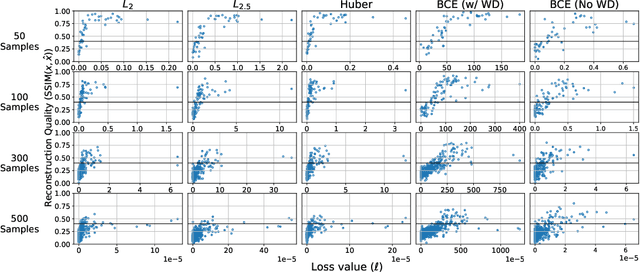
Memorization of training data is an active research area, yet our understanding of the inner workings of neural networks is still in its infancy. Recently, Haim et al. (2022) proposed a scheme to reconstruct training samples from multilayer perceptron binary classifiers, effectively demonstrating that a large portion of training samples are encoded in the parameters of such networks. In this work, we extend their findings in several directions, including reconstruction from multiclass and convolutional neural networks. We derive a more general reconstruction scheme which is applicable to a wider range of loss functions such as regression losses. Moreover, we study the various factors that contribute to networks' susceptibility to such reconstruction schemes. Intriguingly, we observe that using weight decay during training increases reconstructability both in terms of quantity and quality. Additionally, we examine the influence of the number of neurons relative to the number of training samples on the reconstructability.
SinFusion: Training Diffusion Models on a Single Image or Video
Nov 21, 2022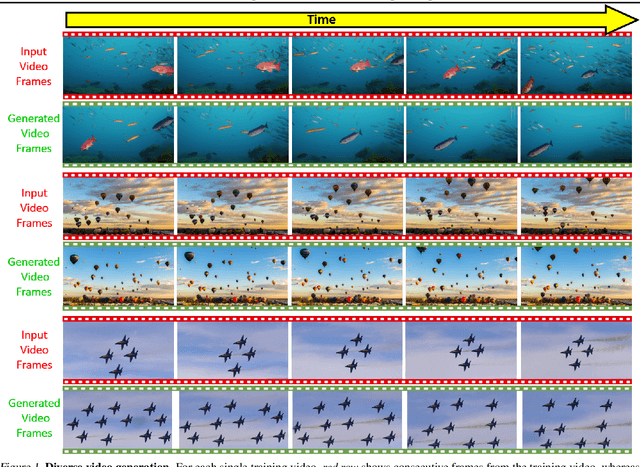
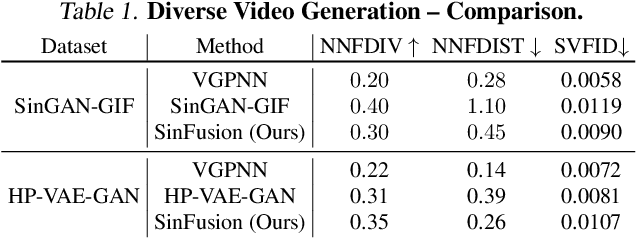

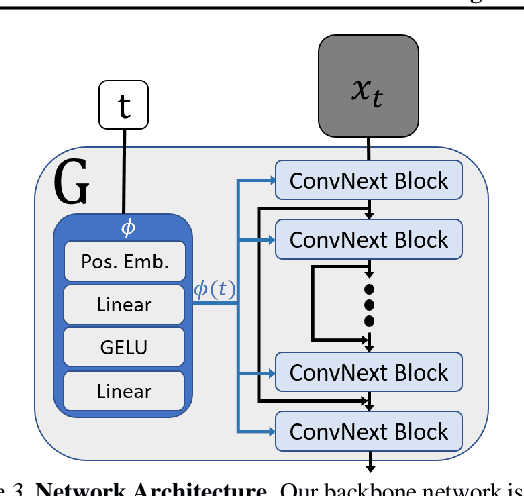
Diffusion models exhibited tremendous progress in image and video generation, exceeding GANs in quality and diversity. However, they are usually trained on very large datasets and are not naturally adapted to manipulate a given input image or video. In this paper we show how this can be resolved by training a diffusion model on a single input image or video. Our image/video-specific diffusion model (SinFusion) learns the appearance and dynamics of the single image or video, while utilizing the conditioning capabilities of diffusion models. It can solve a wide array of image/video-specific manipulation tasks. In particular, our model can learn from few frames the motion and dynamics of a single input video. It can then generate diverse new video samples of the same dynamic scene, extrapolate short videos into long ones (both forward and backward in time) and perform video upsampling. When trained on a single image, our model shows comparable performance and capabilities to previous single-image models in various image manipulation tasks.