 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInduction Meets Biology: Mechanisms of Repeat Detection in Protein Language Models
Feb 26, 2026Protein sequences are abundant in repeating segments, both as exact copies and as approximate segments with mutations. These repeats are important for protein structure and function, motivating decades of algorithmic work on repeat identification. Recent work has shown that protein language models (PLMs) identify repeats, by examining their behavior in masked-token prediction. To elucidate their internal mechanisms, we investigate how PLMs detect both exact and approximate repeats. We find that the mechanism for approximate repeats functionally subsumes that of exact repeats. We then characterize this mechanism, revealing two main stages: PLMs first build feature representations using both general positional attention heads and biologically specialized components, such as neurons that encode amino-acid similarity. Then, induction heads attend to aligned tokens across repeated segments, promoting the correct answer. Our results reveal how PLMs solve this biological task by combining language-based pattern matching with specialized biological knowledge, thereby establishing a basis for studying more complex evolutionary processes in PLMs.
Survey of Active Learning Hyperparameters: Insights from a Large-Scale Experimental Grid
Jun 04, 2025Annotating data is a time-consuming and costly task, but it is inherently required for supervised machine learning. Active Learning (AL) is an established method that minimizes human labeling effort by iteratively selecting the most informative unlabeled samples for expert annotation, thereby improving the overall classification performance. Even though AL has been known for decades, AL is still rarely used in real-world applications. As indicated in the two community web surveys among the NLP community about AL, two main reasons continue to hold practitioners back from using AL: first, the complexity of setting AL up, and second, a lack of trust in its effectiveness. We hypothesize that both reasons share the same culprit: the large hyperparameter space of AL. This mostly unexplored hyperparameter space often leads to misleading and irreproducible AL experiment results. In this study, we first compiled a large hyperparameter grid of over 4.6 million hyperparameter combinations, second, recorded the performance of all combinations in the so-far biggest conducted AL study, and third, analyzed the impact of each hyperparameter in the experiment results. In the end, we give recommendations about the influence of each hyperparameter, demonstrate the surprising influence of the concrete AL strategy implementation, and outline an experimental study design for reproducible AL experiments with minimal computational effort, thus contributing to more reproducible and trustworthy AL research in the future.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
How Generative IR Retrieves Documents Mechanistically
Mar 25, 2025
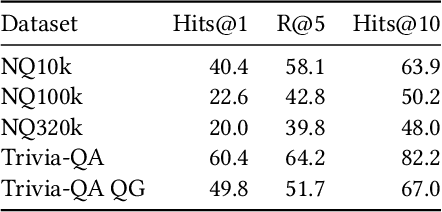
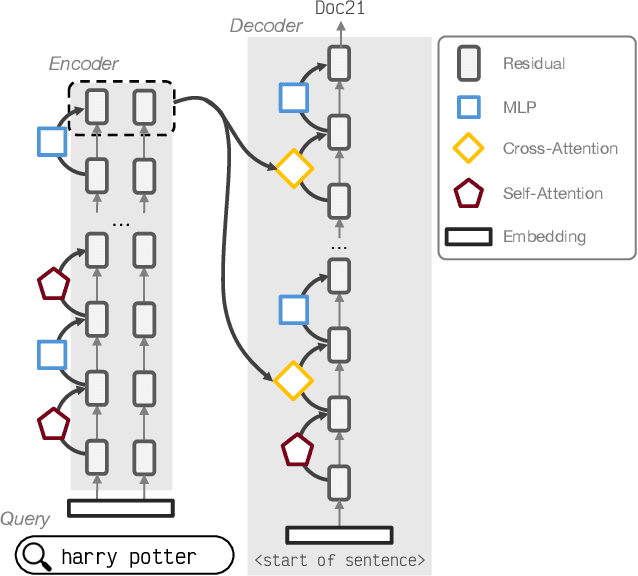

Generative Information Retrieval (GenIR) is a novel paradigm in which a transformer encoder-decoder model predicts document rankings based on a query in an end-to-end fashion. These GenIR models have received significant attention due to their simple retrieval architecture while maintaining high retrieval effectiveness. However, in contrast to established retrieval architectures like cross-encoders or bi-encoders, their internal computations remain largely unknown. Therefore, this work studies the internal retrieval process of GenIR models by applying methods based on mechanistic interpretability, such as patching and vocabulary projections. By replacing the GenIR encoder with one trained on fewer documents, we demonstrate that the decoder is the primary component responsible for successful retrieval. Our patching experiments reveal that not all components in the decoder are crucial for the retrieval process. More specifically, we find that a pass through the decoder can be divided into three stages: (I) the priming stage, which contributes important information for activating subsequent components in later layers; (II) the bridging stage, where cross-attention is primarily active to transfer query information from the encoder to the decoder; and (III) the interaction stage, where predominantly MLPs are active to predict the document identifier. Our findings indicate that interaction between query and document information occurs only in the last stage. We hope our results promote a better understanding of GenIR models and foster future research to overcome the current challenges associated with these models.
MAMUT: A Novel Framework for Modifying Mathematical Formulas for the Generation of Specialized Datasets for Language Model Training
Feb 28, 2025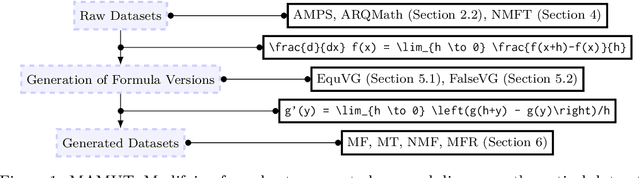
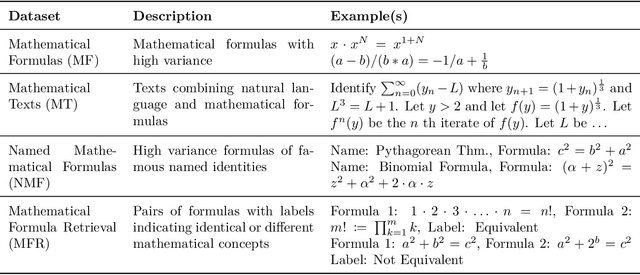

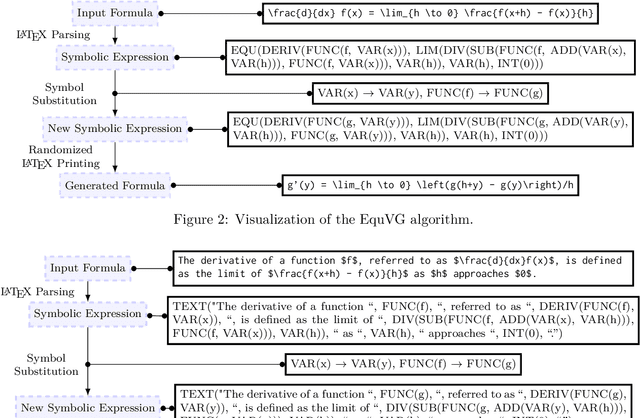
Mathematical formulas are a fundamental and widely used component in various scientific fields, serving as a universal language for expressing complex concepts and relationships. While state-of-the-art transformer models excel in processing and understanding natural language, they encounter challenges with mathematical notation, which involves a complex structure and diverse representations. This study focuses on the development of specialized training datasets to enhance the encoding of mathematical content. We introduce Math Mutator (MAMUT), a framework capable of generating equivalent and falsified versions of a given mathematical formula in LaTeX notation, effectively capturing the mathematical variety in notation of the same concept. Based on MAMUT, we have generated four large mathematical datasets containing diverse notation, which can be used to train language models with enhanced mathematical embeddings.
Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics
Oct 28, 2024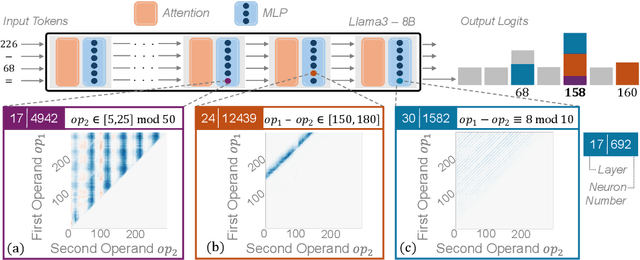
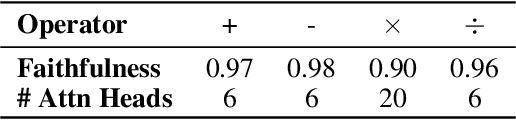
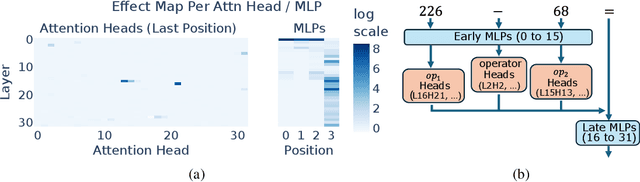

Do large language models (LLMs) solve reasoning tasks by learning robust generalizable algorithms, or do they memorize training data? To investigate this question, we use arithmetic reasoning as a representative task. Using causal analysis, we identify a subset of the model (a circuit) that explains most of the model's behavior for basic arithmetic logic and examine its functionality. By zooming in on the level of individual circuit neurons, we discover a sparse set of important neurons that implement simple heuristics. Each heuristic identifies a numerical input pattern and outputs corresponding answers. We hypothesize that the combination of these heuristic neurons is the mechanism used to produce correct arithmetic answers. To test this, we categorize each neuron into several heuristic types-such as neurons that activate when an operand falls within a certain range-and find that the unordered combination of these heuristic types is the mechanism that explains most of the model's accuracy on arithmetic prompts. Finally, we demonstrate that this mechanism appears as the main source of arithmetic accuracy early in training. Overall, our experimental results across several LLMs show that LLMs perform arithmetic using neither robust algorithms nor memorization; rather, they rely on a "bag of heuristics".
To Softmax, or not to Softmax: that is the question when applying Active Learning for Transformer Models
Oct 06, 2022



Despite achieving state-of-the-art results in nearly all Natural Language Processing applications, fine-tuning Transformer-based language models still requires a significant amount of labeled data to work. A well known technique to reduce the amount of human effort in acquiring a labeled dataset is \textit{Active Learning} (AL): an iterative process in which only the minimal amount of samples is labeled. AL strategies require access to a quantified confidence measure of the model predictions. A common choice is the softmax activation function for the final layer. As the softmax function provides misleading probabilities, this paper compares eight alternatives on seven datasets. Our almost paradoxical finding is that most of the methods are too good at identifying the true most uncertain samples (outliers), and that labeling therefore exclusively outliers results in worse performance. As a heuristic we propose to systematically ignore samples, which results in improvements of various methods compared to the softmax function.