 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Active Learning Hyperparameters: Insights from a Large-Scale Experimental Grid
Jun 04, 2025Annotating data is a time-consuming and costly task, but it is inherently required for supervised machine learning. Active Learning (AL) is an established method that minimizes human labeling effort by iteratively selecting the most informative unlabeled samples for expert annotation, thereby improving the overall classification performance. Even though AL has been known for decades, AL is still rarely used in real-world applications. As indicated in the two community web surveys among the NLP community about AL, two main reasons continue to hold practitioners back from using AL: first, the complexity of setting AL up, and second, a lack of trust in its effectiveness. We hypothesize that both reasons share the same culprit: the large hyperparameter space of AL. This mostly unexplored hyperparameter space often leads to misleading and irreproducible AL experiment results. In this study, we first compiled a large hyperparameter grid of over 4.6 million hyperparameter combinations, second, recorded the performance of all combinations in the so-far biggest conducted AL study, and third, analyzed the impact of each hyperparameter in the experiment results. In the end, we give recommendations about the influence of each hyperparameter, demonstrate the surprising influence of the concrete AL strategy implementation, and outline an experimental study design for reproducible AL experiments with minimal computational effort, thus contributing to more reproducible and trustworthy AL research in the future.
Have LLMs Made Active Learning Obsolete? Surveying the NLP Community
Mar 12, 2025



Supervised learning relies on annotated data, which is expensive to obtain. A longstanding strategy to reduce annotation costs is active learning, an iterative process, in which a human annotates only data instances deemed informative by a model. Large language models (LLMs) have pushed the effectiveness of active learning, but have also improved methods such as few- or zero-shot learning, and text synthesis - thereby introducing potential alternatives. This raises the question: has active learning become obsolete? To answer this fully, we must look beyond literature to practical experiences. We conduct an online survey in the NLP community to collect previously intangible insights on the perceived relevance of data annotation, particularly focusing on active learning, including best practices, obstacles and expected future developments. Our findings show that annotated data remains a key factor, and active learning continues to be relevant. While the majority of active learning users find it effective, a comparison with a community survey from over a decade ago reveals persistent challenges: setup complexity, estimation of cost reduction, and tooling. We publish an anonymized version of the collected dataset
To Softmax, or not to Softmax: that is the question when applying Active Learning for Transformer Models
Oct 06, 2022



Despite achieving state-of-the-art results in nearly all Natural Language Processing applications, fine-tuning Transformer-based language models still requires a significant amount of labeled data to work. A well known technique to reduce the amount of human effort in acquiring a labeled dataset is \textit{Active Learning} (AL): an iterative process in which only the minimal amount of samples is labeled. AL strategies require access to a quantified confidence measure of the model predictions. A common choice is the softmax activation function for the final layer. As the softmax function provides misleading probabilities, this paper compares eight alternatives on seven datasets. Our almost paradoxical finding is that most of the methods are too good at identifying the true most uncertain samples (outliers), and that labeling therefore exclusively outliers results in worse performance. As a heuristic we propose to systematically ignore samples, which results in improvements of various methods compared to the softmax function.
ImitAL: Learned Active Learning Strategy on Synthetic Data
Aug 24, 2022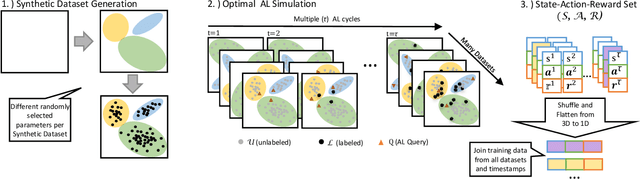
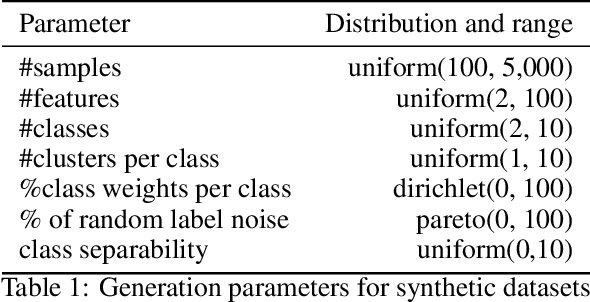
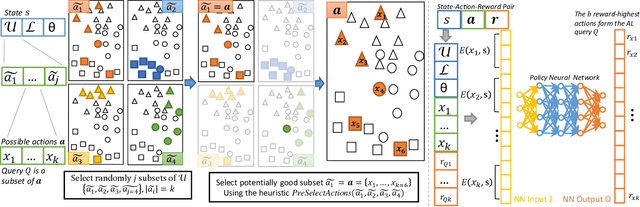
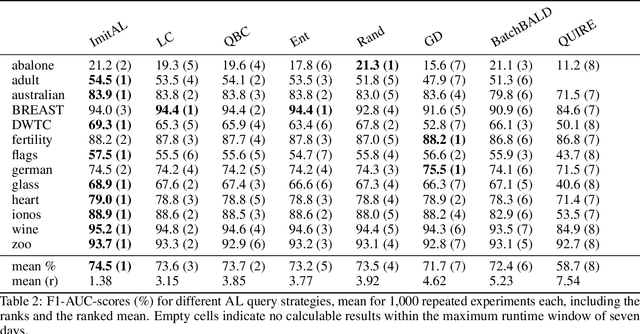
Active Learning (AL) is a well-known standard method for efficiently obtaining annotated data by first labeling the samples that contain the most information based on a query strategy. In the past, a large variety of such query strategies has been proposed, with each generation of new strategies increasing the runtime and adding more complexity. However, to the best of our our knowledge, none of these strategies excels consistently over a large number of datasets from different application domains. Basically, most of the the existing AL strategies are a combination of the two simple heuristics informativeness and representativeness, and the big differences lie in the combination of the often conflicting heuristics. Within this paper, we propose ImitAL, a domain-independent novel query strategy, which encodes AL as a learning-to-rank problem and learns an optimal combination between both heuristics. We train ImitAL on large-scale simulated AL runs on purely synthetic datasets. To show that ImitAL was successfully trained, we perform an extensive evaluation comparing our strategy on 13 different datasets, from a wide range of domains, with 7 other query strategies.
ImitAL: Learning Active Learning Strategies from Synthetic Data
Aug 17, 2021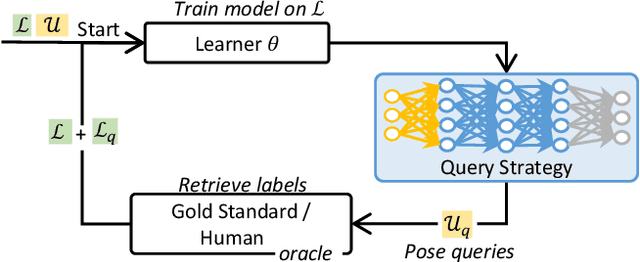



One of the biggest challenges that complicates applied supervised machine learning is the need for huge amounts of labeled data. Active Learning (AL) is a well-known standard method for efficiently obtaining labeled data by first labeling the samples that contain the most information based on a query strategy. Although many methods for query strategies have been proposed in the past, no clear superior method that works well in general for all domains has been found yet. Additionally, many strategies are computationally expensive which further hinders the widespread use of AL for large-scale annotation projects. We, therefore, propose ImitAL, a novel query strategy, which encodes AL as a learning-to-rank problem. For training the underlying neural network we chose Imitation Learning. The required demonstrative expert experience for training is generated from purely synthetic data. To show the general and superior applicability of \ImitAL{}, we perform an extensive evaluation comparing our strategy on 15 different datasets, from a wide range of domains, with 10 different state-of-the-art query strategies. We also show that our approach is more runtime performant than most other strategies, especially on very large datasets.