 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Object Detection from Captions via Textual Scene Attributes
Sep 30, 2020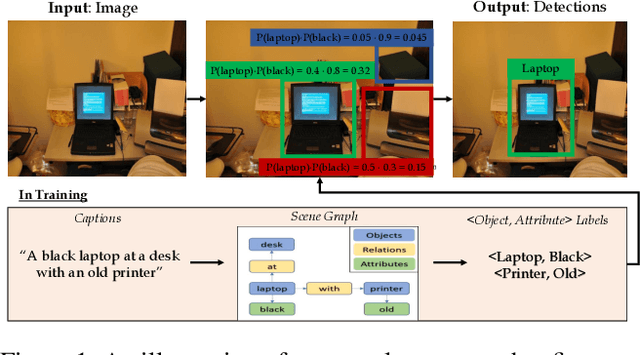
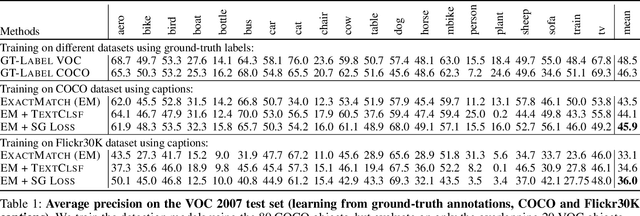
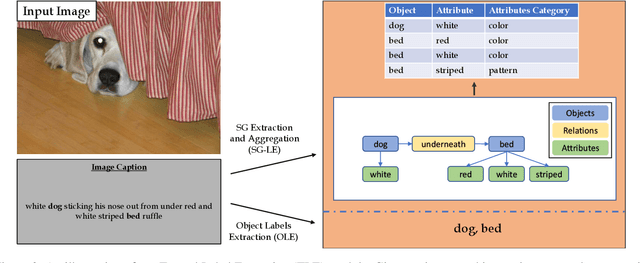
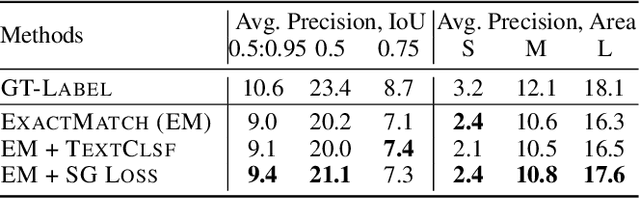
Object detection is a fundamental task in computer vision, requiring large annotated datasets that are difficult to collect, as annotators need to label objects and their bounding boxes. Thus, it is a significant challenge to use cheaper forms of supervision effectively. Recent work has begun to explore image captions as a source for weak supervision, but to date, in the context of object detection, captions have only been used to infer the categories of the objects in the image. In this work, we argue that captions contain much richer information about the image, including attributes of objects and their relations. Namely, the text represents a scene of the image, as described recently in the literature. We present a method that uses the attributes in this "textual scene graph" to train object detectors. We empirically demonstrate that the resulting model achieves state-of-the-art results on several challenging object detection datasets, outperforming recent approaches.
orgFAQ: A New Dataset and Analysis on Organizational FAQs and User Questions
Sep 03, 2020Frequently Asked Questions (FAQ) webpages are created by organizations for their users. FAQs are used in several scenarios, e.g., to answer user questions. On the other hand, the content of FAQs is affected by user questions by definition. In order to promote research in this field, several FAQ datasets exist. However, we claim that being collected from community websites, they do not correctly represent challenges associated with FAQs in an organizational context. Thus, we release orgFAQ, a new dataset composed of $6988$ user questions and $1579$ corresponding FAQs that were extracted from organizations' FAQ webpages in the Jobs domain. In this paper, we provide an analysis of the properties of such FAQs, and demonstrate the usefulness of our new dataset by utilizing it in a relevant task from the Jobs domain. We also show the value of the orgFAQ dataset in a task of a different domain - the COVID-19 pandemic.
A Summarization System for Scientific Documents
Aug 29, 2019

We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
TalkSumm: A Dataset and Scalable Annotation Method for Scientific Paper Summarization Based on Conference Talks
Jun 13, 2019
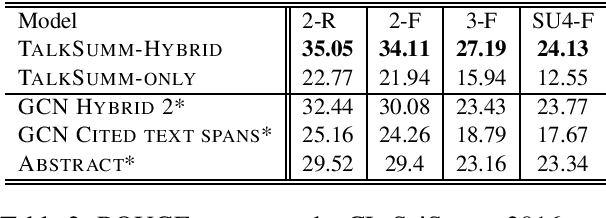

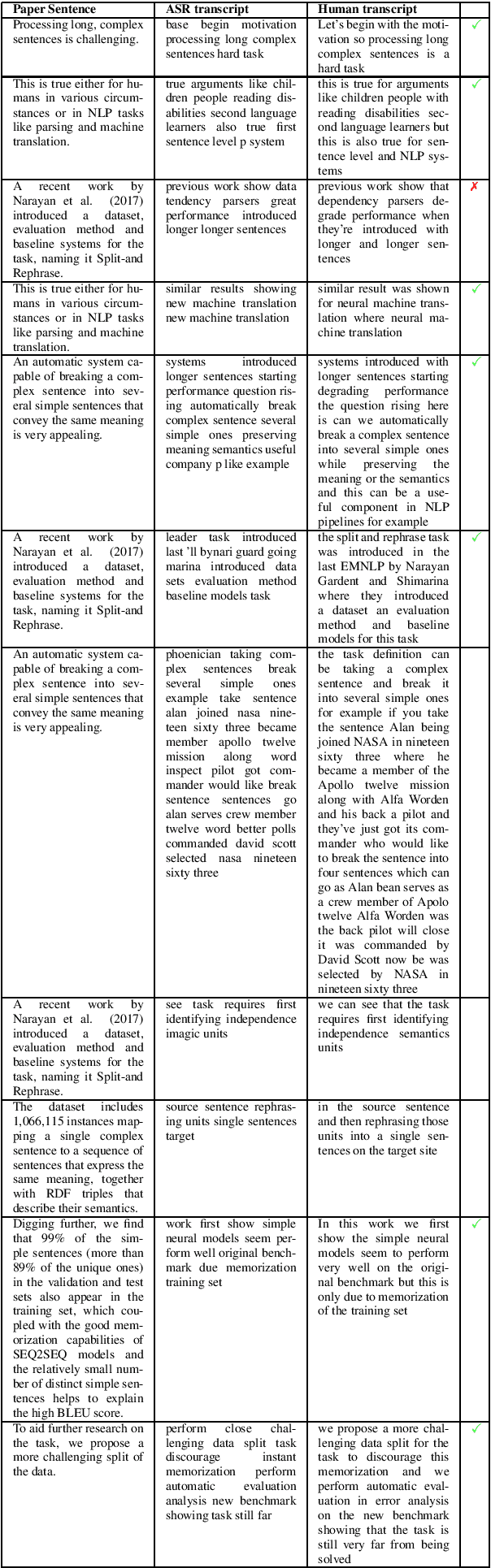
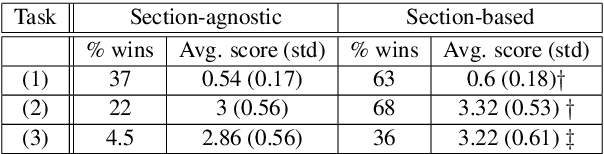
Currently, no large-scale training data is available for the task of scientific paper summarization. In this paper, we propose a novel method that automatically generates summaries for scientific papers, by utilizing videos of talks at scientific conferences. We hypothesize that such talks constitute a coherent and concise description of the papers' content, and can form the basis for good summaries. We collected 1716 papers and their corresponding videos, and created a dataset of paper summaries. A model trained on this dataset achieves similar performance as models trained on a dataset of summaries created manually. In addition, we validated the quality of our summaries by human experts.