 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Object Detection from Captions via Textual Scene Attributes
Paper and Code
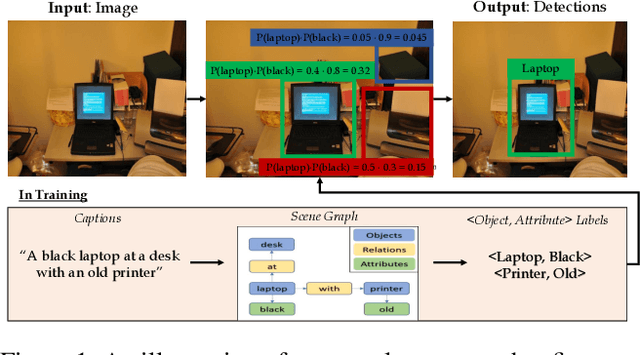
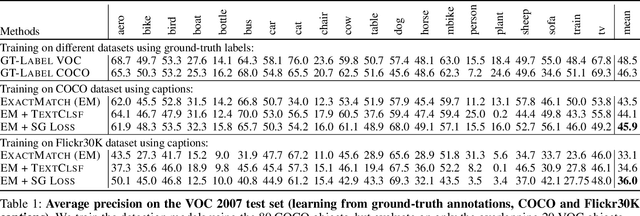
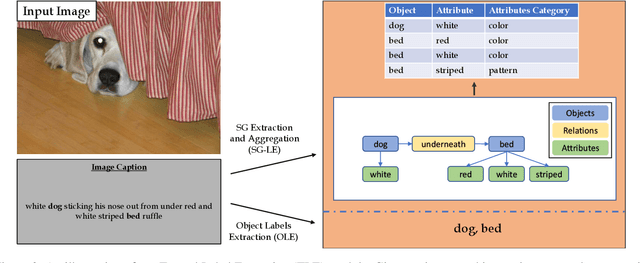
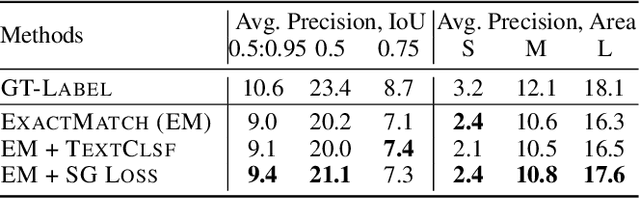
Object detection is a fundamental task in computer vision, requiring large annotated datasets that are difficult to collect, as annotators need to label objects and their bounding boxes. Thus, it is a significant challenge to use cheaper forms of supervision effectively. Recent work has begun to explore image captions as a source for weak supervision, but to date, in the context of object detection, captions have only been used to infer the categories of the objects in the image. In this work, we argue that captions contain much richer information about the image, including attributes of objects and their relations. Namely, the text represents a scene of the image, as described recently in the literature. We present a method that uses the attributes in this "textual scene graph" to train object detectors. We empirically demonstrate that the resulting model achieves state-of-the-art results on several challenging object detection datasets, outperforming recent approaches.