 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Efficiency and Safety: Formal Verification of Neural Networks with Early Exits
Dec 23, 2025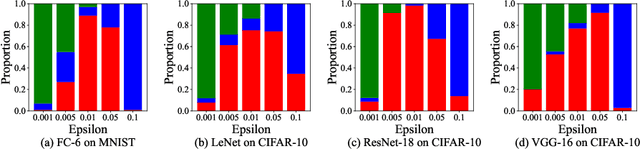
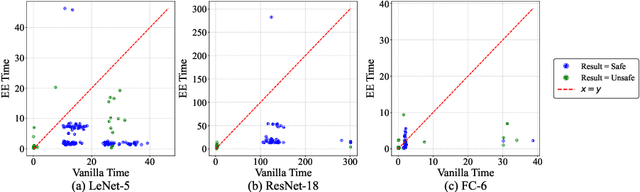


Ensuring the safety and efficiency of AI systems is a central goal of modern research. Formal verification provides guarantees of neural network robustness, while early exits improve inference efficiency by enabling intermediate predictions. Yet verifying networks with early exits introduces new challenges due to their conditional execution paths. In this work, we define a robustness property tailored to early exit architectures and show how off-the-shelf solvers can be used to assess it. We present a baseline algorithm, enhanced with an early stopping strategy and heuristic optimizations that maintain soundness and completeness. Experiments on multiple benchmarks validate our framework's effectiveness and demonstrate the performance gains of the improved algorithm. Alongside the natural inference acceleration provided by early exits, we show that they also enhance verifiability, enabling more queries to be solved in less time compared to standard networks. Together with a robustness analysis, we show how these metrics can help users navigate the inherent trade-off between accuracy and efficiency.
Formal Verification of Object Detection
Jul 01, 2024



Deep Neural Networks (DNNs) are ubiquitous in real-world applications, yet they remain vulnerable to errors and adversarial attacks. This work tackles the challenge of applying formal verification to ensure the safety of computer vision models, extending verification beyond image classification to object detection. We propose a general formulation for certifying the robustness of object detection models using formal verification and outline implementation strategies compatible with state-of-the-art verification tools. Our approach enables the application of these tools, originally designed for verifying classification models, to object detection. We define various attacks for object detection, illustrating the diverse ways adversarial inputs can compromise neural network outputs. Our experiments, conducted on several common datasets and networks, reveal potential errors in object detection models, highlighting system vulnerabilities and emphasizing the need for expanding formal verification to these new domains. This work paves the way for further research in integrating formal verification across a broader range of computer vision applications.
Layer Folding: Neural Network Depth Reduction using Activation Linearization
Jun 17, 2021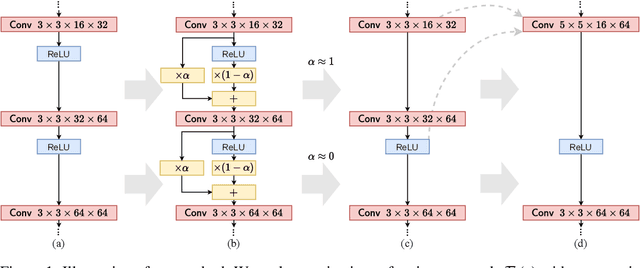

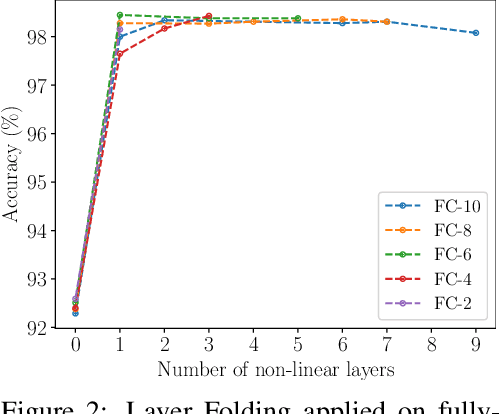

Despite the increasing prevalence of deep neural networks, their applicability in resource-constrained devices is limited due to their computational load. While modern devices exhibit a high level of parallelism, real-time latency is still highly dependent on networks' depth. Although recent works show that below a certain depth, the width of shallower networks must grow exponentially, we presume that neural networks typically exceed this minimal depth to accelerate convergence and incrementally increase accuracy. This motivates us to transform pre-trained deep networks that already exploit such advantages into shallower forms. We propose a method that learns whether non-linear activations can be removed, allowing to fold consecutive linear layers into one. We apply our method to networks pre-trained on CIFAR-10 and CIFAR-100 and find that they can all be transformed into shallower forms that share a similar depth. Finally, we use our method to provide more efficient alternatives to MobileNetV2 and EfficientNet-Lite architectures on the ImageNet classification task.