 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Math Reasoning Evaluation: A Robust LLM-as-a-Judge Framework Beyond Symbolic Rigidity
Apr 24, 2026Recent advancements in large language models have led to significant improvements across various tasks, including mathematical reasoning, which is used to assess models' intelligence in logical reasoning and problem-solving. Models are evaluated on mathematical reasoning benchmarks by verifying the correctness of the final answer against a ground truth answer. A common approach for this verification is based on symbolic mathematics comparison, which fails to generalize across diverse mathematical representations and solution formats. In this work, we offer a robust and flexible alternative to rule-based symbolic mathematics comparison. We propose an LLM-based evaluation framework for evaluating model-generated answers, enabling accurate evaluation across diverse mathematical representations and answer formats. We present failure cases of symbolic evaluation in two popular frameworks, Lighteval and SimpleRL, and compare them to our approach, demonstrating clear improvements over commonly used methods. Our framework enables more reliable evaluation and benchmarking, leading to more accurate performance monitoring, which is important for advancing mathematical problem-solving and intelligent systems.
Guided Lensless Polarization Imaging
Mar 28, 2026Polarization imaging captures the polarization state of light, revealing information invisible to the human eye yet valuable in domains such as biomedical diagnostics, autonomous driving, and remote sensing. However, conventional polarization cameras are often expensive, bulky, or both, limiting their practical use. Lensless imaging offers a compact, low-cost alternative by replacing the lens with a simple optical element like a diffuser and performing computational reconstruction, but existing lensless polarization systems suffer from limited reconstruction quality. To overcome these limitations, we introduce a RGB-guided lensless polarization imaging system that combines a compact polarization-RGB sensor with an auxiliary, widely available conventional RGB camera providing structural guidance. We reconstruct multi-angle polarization images for each RGB color channel through a two-stage pipeline: a physics-based inversion recovers an initial polarization image, followed by a Transformer-based fusion network that refines this reconstruction using the RGB guidance image from the conventional RGB camera. Our two-stage method significantly improves reconstruction quality and fidelity over lensless-only baselines, generalizes across datasets and imaging conditions, and achieves high-quality real-world results on our physical prototype lensless camera without any fine-tuning.
A Lensless Polarization Camera
Mar 17, 2026Polarization imaging is a technique that creates a pixel map of the polarization state in a scene. Although invisible to the human eye, polarization can assist various sensing and computer vision tasks. Existing polarization cameras use spatial or temporal multiplexing, which increases the camera volume, weight, cost, or all of the above. Recent lensless imaging approaches, such as DiffuserCam, have demonstrated that compact imaging systems can be realized by replacing the lens with a coding element and performing computational reconstruction. In this work, we propose a compact lensless polarization camera composed of a diffuser and a simple striped polarization mask. By combining this optical design with a reconstruction algorithm that explicitly models the polarization-encoded lensless measurements, four linear polarization images are recovered from a single snapshot. Our results demonstrate the potential of lensless approaches for polarization imaging and reveal the physical factors that govern reconstruction quality, guiding the development of high-quality practical systems.
Scene-VLM: Multimodal Video Scene Segmentation via Vision-Language Models
Dec 25, 2025



Segmenting long-form videos into semantically coherent scenes is a fundamental task in large-scale video understanding. Existing encoder-based methods are limited by visual-centric biases, classify each shot in isolation without leveraging sequential dependencies, and lack both narrative understanding and explainability. In this paper, we present Scene-VLM, the first fine-tuned vision-language model (VLM) framework for video scene segmentation. Scene-VLM jointly processes visual and textual cues including frames, transcriptions, and optional metadata to enable multimodal reasoning across consecutive shots. The model generates predictions sequentially with causal dependencies among shots and introduces a context-focus window mechanism to ensure sufficient temporal context for each shot-level decision. In addition, we propose a scheme to extract confidence scores from the token-level logits of the VLM, enabling controllable precision-recall trade-offs that were previously limited to encoder-based methods. Furthermore, we demonstrate that our model can be aligned to generate coherent natural-language rationales for its boundary decisions through minimal targeted supervision. Our approach achieves state-of-the-art performance on standard scene segmentation benchmarks. On MovieNet, for example, Scene-VLM yields significant improvements of +6 AP and +13.7 F1 over the previous leading method.
DifuzCam: Replacing Camera Lens with a Mask and a Diffusion Model
Aug 14, 2024The flat lensless camera design reduces the camera size and weight significantly. In this design, the camera lens is replaced by another optical element that interferes with the incoming light. The image is recovered from the raw sensor measurements using a reconstruction algorithm. Yet, the quality of the reconstructed images is not satisfactory. To mitigate this, we propose utilizing a pre-trained diffusion model with a control network and a learned separable transformation for reconstruction. This allows us to build a prototype flat camera with high-quality imaging, presenting state-of-the-art results in both terms of quality and perceptuality. We demonstrate its ability to leverage also textual descriptions of the captured scene to further enhance reconstruction. Our reconstruction method which leverages the strong capabilities of a pre-trained diffusion model can be used in other imaging systems for improved reconstruction results.
Tell Me What You See: Text-Guided Real-World Image Denoising
Dec 15, 2023Image reconstruction in low-light conditions is a challenging problem. Many solutions have been proposed for it, where the main approach is trying to learn a good prior of natural images along with modeling the true statistics of the noise in the scene. In the presence of very low lighting conditions, such approaches are usually not enough, and additional information is required, e.g., in the form of using multiple captures. In this work, we suggest as an alternative to add a description of the scene as prior, which can be easily done by the photographer who is capturing the scene. Using a text-conditioned diffusion model, we show that adding image caption information improves significantly the image reconstruction in low-light conditions on both synthetic and real-world images.
Mind The Edge: Refining Depth Edges in Sparsely-Supervised Monocular Depth Estimation
Dec 10, 2022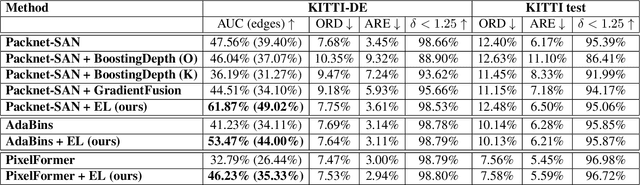



Monocular Depth Estimation (MDE) is a fundamental problem in computer vision with numerous applications. Recently, LIDAR-supervised methods have achieved remarkable per-pixel depth accuracy in outdoor scenes. However, significant errors are typically found in the proximity of depth discontinuities, i.e., depth edges, which often hinder the performance of depth-dependent applications that are sensitive to such inaccuracies, e.g., novel view synthesis and augmented reality. Since direct supervision for the location of depth edges is typically unavailable in sparse LIDAR-based scenes, encouraging the MDE model to produce correct depth edges is not straightforward. In this work we propose to learn to detect the location of depth edges from densely-supervised synthetic data, and use it to generate supervision for the depth edges in the MDE training. %Despite the 'domain gap' between synthetic and real data, we show that depth edges that are estimated directly are significantly more accurate than the ones that emerge indirectly from the MDE training. To quantitatively evaluate our approach, and due to the lack of depth edges ground truth in LIDAR-based scenes, we manually annotated subsets of the KITTI and the DDAD datasets with depth edges ground truth. We demonstrate significant gains in the accuracy of the depth edges with comparable per-pixel depth accuracy on several challenging datasets.
Video Reconstruction from a Single Motion Blurred Image using Learned Dynamic Phase Coding
Dec 28, 2021

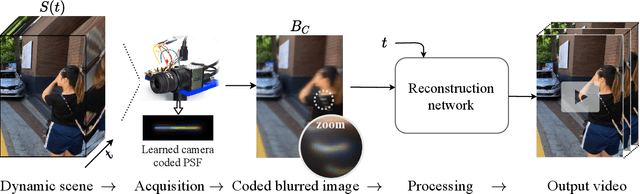
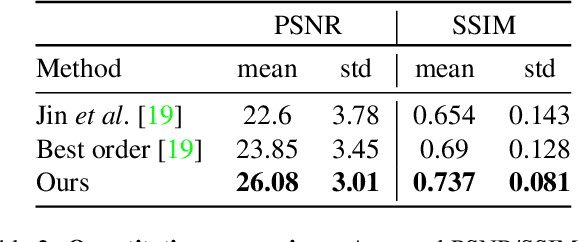
Video reconstruction from a single motion-blurred image is a challenging problem, which can enhance existing cameras' capabilities. Recently, several works addressed this task using conventional imaging and deep learning. Yet, such purely-digital methods are inherently limited, due to direction ambiguity and noise sensitivity. Some works proposed to address these limitations using non-conventional image sensors, however, such sensors are extremely rare and expensive. To circumvent these limitations with simpler means, we propose a hybrid optical-digital method for video reconstruction that requires only simple modifications to existing optical systems. We use a learned dynamic phase-coding in the lens aperture during the image acquisition to encode the motion trajectories, which serve as prior information for the video reconstruction process. The proposed computational camera generates a sharp frame burst of the scene at various frame rates from a single coded motion-blurred image, using an image-to-video convolutional neural network. We present advantages and improved performance compared to existing methods, using both simulations and a real-world camera prototype.