 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lensless Polarization Camera
Mar 17, 2026Polarization imaging is a technique that creates a pixel map of the polarization state in a scene. Although invisible to the human eye, polarization can assist various sensing and computer vision tasks. Existing polarization cameras use spatial or temporal multiplexing, which increases the camera volume, weight, cost, or all of the above. Recent lensless imaging approaches, such as DiffuserCam, have demonstrated that compact imaging systems can be realized by replacing the lens with a coding element and performing computational reconstruction. In this work, we propose a compact lensless polarization camera composed of a diffuser and a simple striped polarization mask. By combining this optical design with a reconstruction algorithm that explicitly models the polarization-encoded lensless measurements, four linear polarization images are recovered from a single snapshot. Our results demonstrate the potential of lensless approaches for polarization imaging and reveal the physical factors that govern reconstruction quality, guiding the development of high-quality practical systems.
Video Reconstruction from a Single Motion Blurred Image using Learned Dynamic Phase Coding
Dec 28, 2021

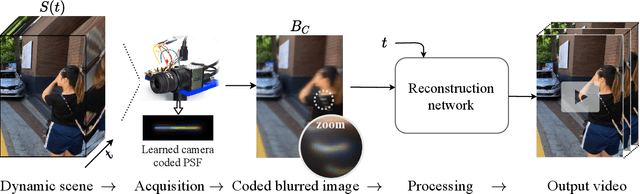
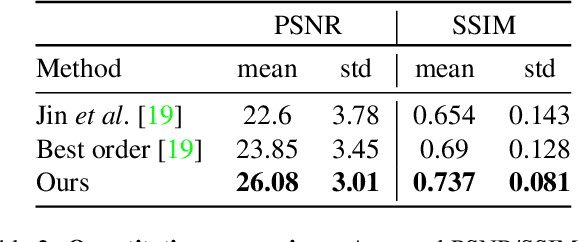
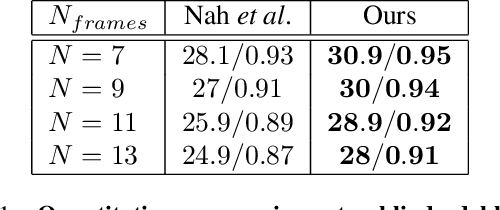
Video reconstruction from a single motion-blurred image is a challenging problem, which can enhance existing cameras' capabilities. Recently, several works addressed this task using conventional imaging and deep learning. Yet, such purely-digital methods are inherently limited, due to direction ambiguity and noise sensitivity. Some works proposed to address these limitations using non-conventional image sensors, however, such sensors are extremely rare and expensive. To circumvent these limitations with simpler means, we propose a hybrid optical-digital method for video reconstruction that requires only simple modifications to existing optical systems. We use a learned dynamic phase-coding in the lens aperture during the image acquisition to encode the motion trajectories, which serve as prior information for the video reconstruction process. The proposed computational camera generates a sharp frame burst of the scene at various frame rates from a single coded motion-blurred image, using an image-to-video convolutional neural network. We present advantages and improved performance compared to existing methods, using both simulations and a real-world camera prototype.
Motion Deblurring using Spatiotemporal Phase Aperture Coding
Feb 18, 2020

Motion blur is a known issue in photography, as it limits the exposure time while capturing moving objects. Extensive research has been carried to compensate for it. In this work, a computational imaging approach for motion deblurring is proposed and demonstrated. Using dynamic phase-coding in the lens aperture during the image acquisition, the trajectory of the motion is encoded in an intermediate optical image. This encoding embeds both the motion direction and extent by coloring the spatial blur of each object. The color cues serve as prior information for a blind deblurring process, implemented using a convolutional neural network (CNN) trained to utilize such coding for image restoration. We demonstrate the advantage of the proposed approach over blind-deblurring with no coding and other solutions that use coded acquisition, both in simulation and real-world experiments.
MonSter: Awakening the Mono in Stereo
Oct 30, 2019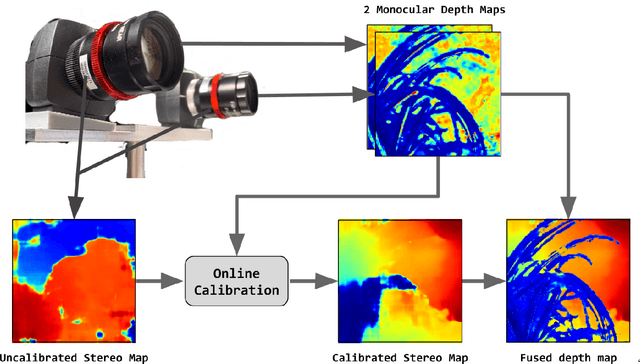
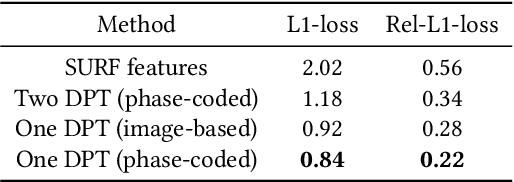
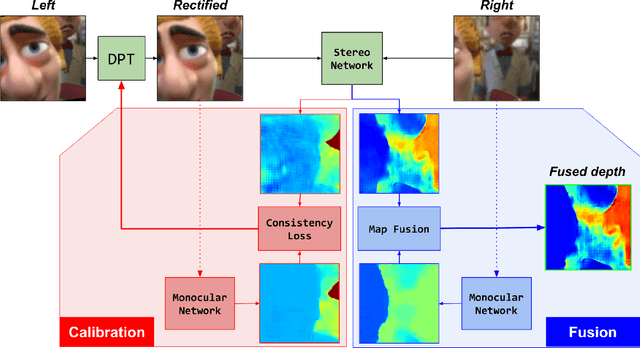

Passive depth estimation is among the most long-studied fields in computer vision. The most common methods for passive depth estimation are either a stereo or a monocular system. Using the former requires an accurate calibration process, and has a limited effective range. The latter, which does not require extrinsic calibration but generally achieves inferior depth accuracy, can be tuned to achieve better results in part of the depth range. In this work, we suggest combining the two frameworks. We propose a two-camera system, in which the cameras are used jointly to extract a stereo depth and individually to provide a monocular depth from each camera. The combination of these depth maps leads to more accurate depth estimation. Moreover, enforcing consistency between the extracted maps leads to a novel online self-calibration strategy. We present a prototype camera that demonstrates the benefits of the proposed combination, for both self-calibration and depth reconstruction in real-world scenes.