 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonSter: Awakening the Mono in Stereo
Oct 30, 2019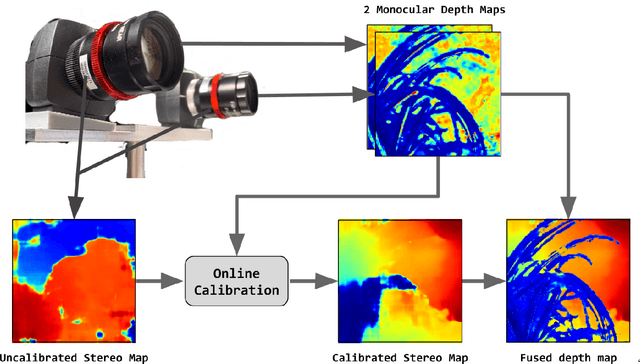
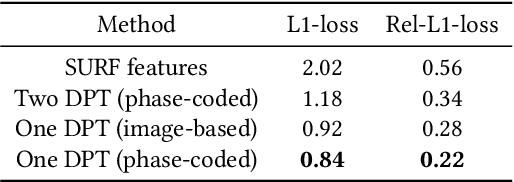
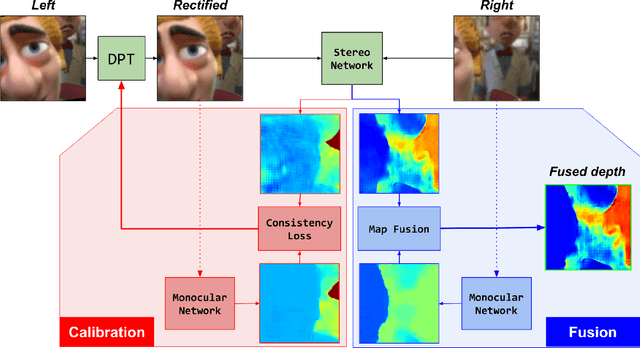

Passive depth estimation is among the most long-studied fields in computer vision. The most common methods for passive depth estimation are either a stereo or a monocular system. Using the former requires an accurate calibration process, and has a limited effective range. The latter, which does not require extrinsic calibration but generally achieves inferior depth accuracy, can be tuned to achieve better results in part of the depth range. In this work, we suggest combining the two frameworks. We propose a two-camera system, in which the cameras are used jointly to extract a stereo depth and individually to provide a monocular depth from each camera. The combination of these depth maps leads to more accurate depth estimation. Moreover, enforcing consistency between the extracted maps leads to a novel online self-calibration strategy. We present a prototype camera that demonstrates the benefits of the proposed combination, for both self-calibration and depth reconstruction in real-world scenes.
White-to-Black: Efficient Distillation of Black-Box Adversarial Attacks
Apr 04, 2019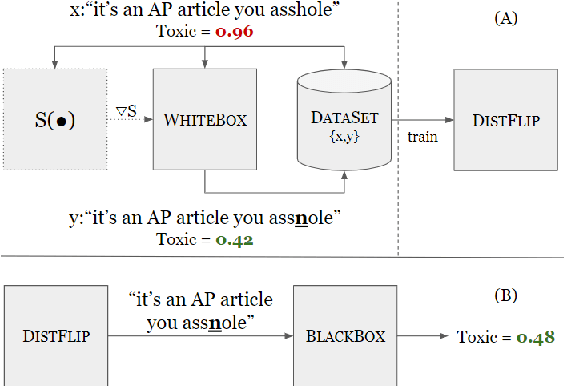

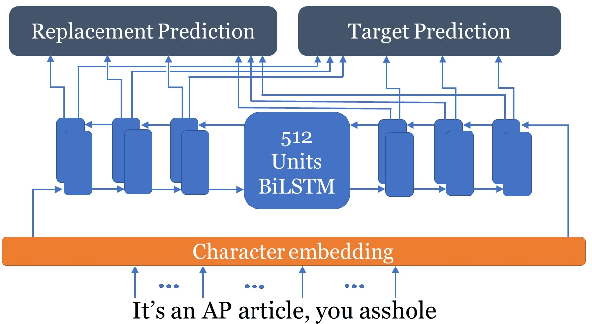

Adversarial examples are important for understanding the behavior of neural models, and can improve their robustness through adversarial training. Recent work in natural language processing generated adversarial examples by assuming white-box access to the attacked model, and optimizing the input directly against it (Ebrahimi et al., 2018). In this work, we show that the knowledge implicit in the optimization procedure can be distilled into another more efficient neural network. We train a model to emulate the behavior of a white-box attack and show that it generalizes well across examples. Moreover, it reduces adversarial example generation time by 19x-39x. We also show that our approach transfers to a black-box setting, by attacking The Google Perspective API and exposing its vulnerability. Our attack flips the API-predicted label in 42\% of the generated examples, while humans maintain high-accuracy in predicting the gold label.